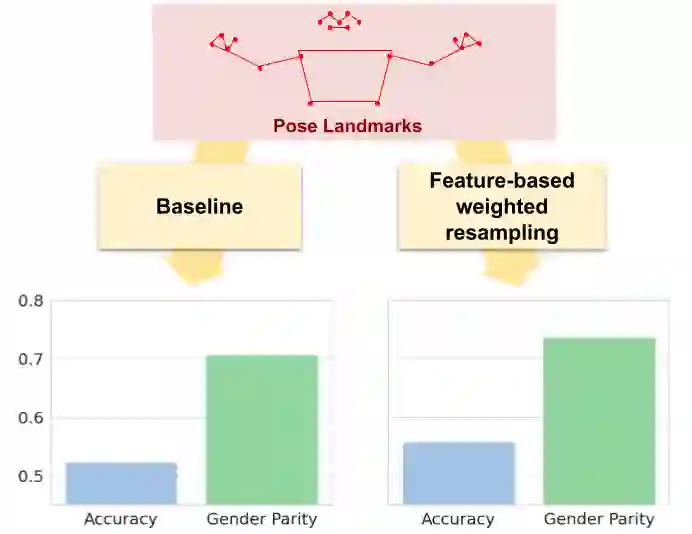
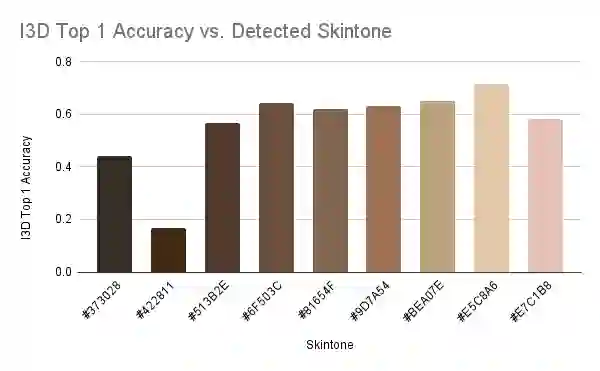
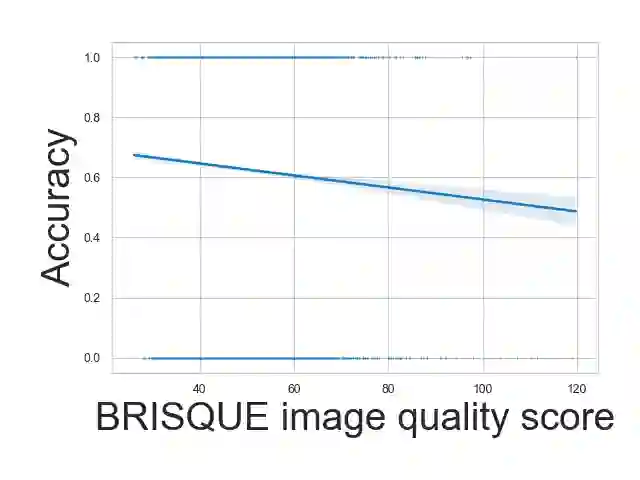
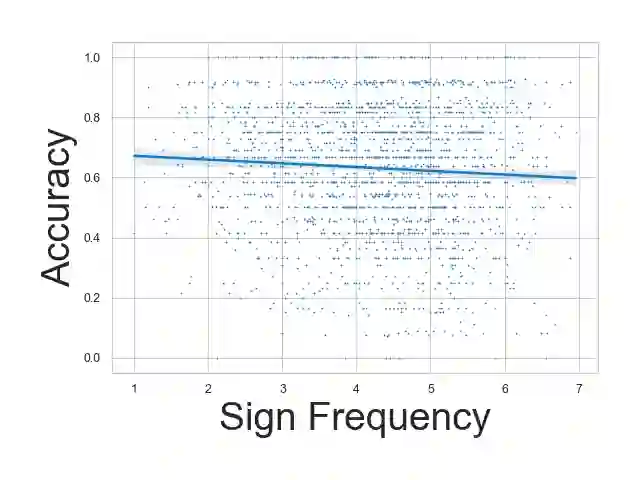
Ensuring that the benefits of sign language technologies are distributed equitably among all community members is crucial. Thus, it is important to address potential biases and inequities that may arise from the design or use of these resources. Crowd-sourced sign language datasets, such as the ASL Citizen dataset, are great resources for improving accessibility and preserving linguistic diversity, but they must be used thoughtfully to avoid reinforcing existing biases. In this work, we utilize the rich information about participant demographics and lexical features present in the ASL Citizen dataset to study and document the biases that may result from models trained on crowd-sourced sign datasets. Further, we apply several bias mitigation techniques during model training, and find that these techniques reduce performance disparities without decreasing accuracy. With the publication of this work, we release the demographic information about the participants in the ASL Citizen dataset to encourage future bias mitigation work in this space.
翻译:确保手语技术带来的益处能够公平地惠及所有社区成员至关重要。因此,必须解决这些资源在设计或使用过程中可能产生的潜在偏见与不平等问题。众包手语数据集(如ASL Citizen数据集)是提升可访问性和保护语言多样性的重要资源,但需审慎使用以避免强化既有偏见。本研究利用ASL Citizen数据集中丰富的参与者人口统计学特征与词汇特征信息,系统研究并记录了基于众包手语数据集训练的模型可能产生的偏见。此外,我们在模型训练阶段应用了多种偏见缓解技术,发现这些技术能在保持准确率的同时有效减少性能差异。通过发表本研究成果,我们同步公开了ASL Citizen数据集的参与者人口统计学信息,以促进该领域未来的偏见缓解研究。