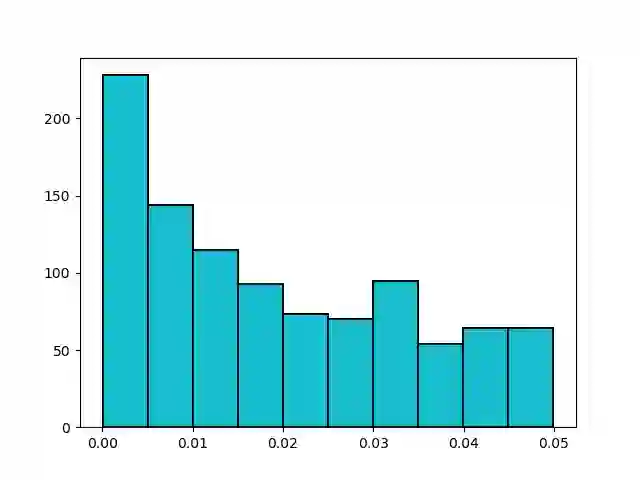
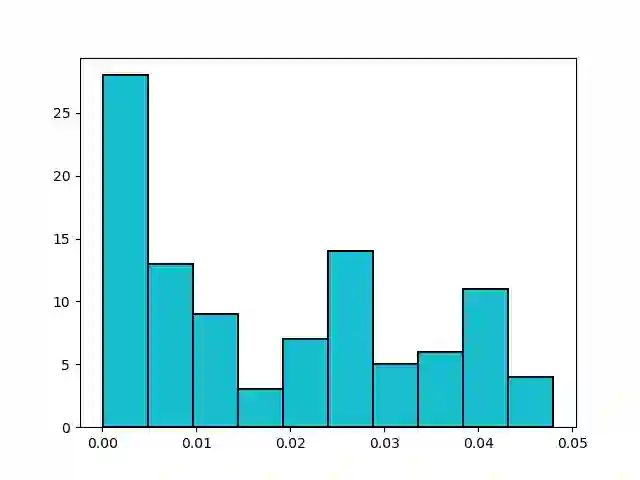
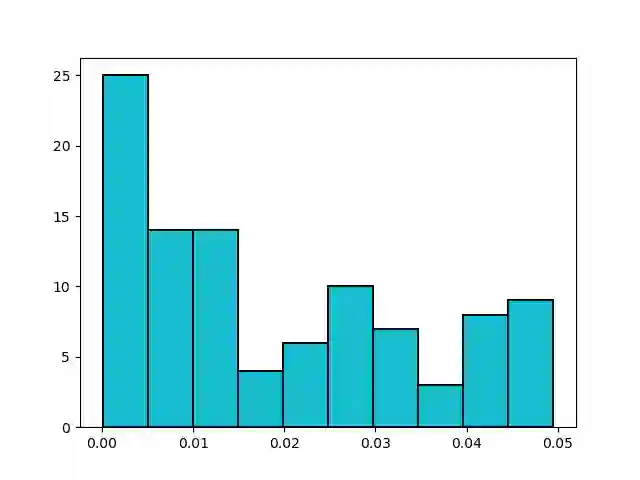
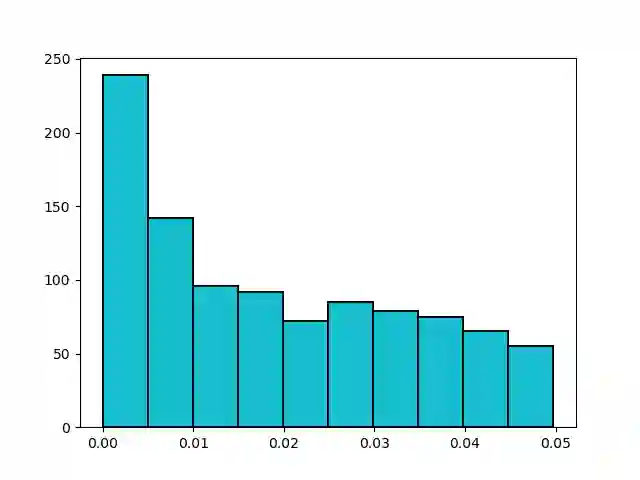
We study the Stochastic Multi-armed Bandit problem under bounded arm-memory. In this setting, the arms arrive in a stream, and the number of arms that can be stored in the memory at any time, is bounded. The decision-maker can only pull arms that are present in the memory. We address the problem from the perspective of two standard objectives: 1) regret minimization, and 2) best-arm identification. For regret minimization, we settle an important open question by showing an almost tight hardness. We show {\Omega}(T^{2/3}) cumulative regret in expectation for arm-memory size of (n-1), where n is the number of arms. For best-arm identification, we study two algorithms. First, we present an O(r) arm-memory r-round adaptive streaming algorithm to find an {\epsilon}-best arm. In r-round adaptive streaming algorithm for best-arm identification, the arm pulls in each round are decided based on the observed outcomes in the earlier rounds. The best-arm is the output at the end of r rounds. The upper bound on the sample complexity of our algorithm matches with the lower bound for any r-round adaptive streaming algorithm. Secondly, we present a heuristic to find the {\epsilon}-best arm with optimal sample complexity, by storing only one extra arm in the memory.
翻译:我们用捆绑的手臂来研究多武装盗匪问题。 在这个环境中, 武器进入一个流体, 以及随时可以存储在记忆中的武器数量, 被捆绑。 决策者只能拉出记忆中存在的武器。 我们从两个标准目标的角度来解决这个问题:(1) 尽量减少遗憾, 和(2) 最佳武器识别。 为了最小化, 我们通过展示近乎紧紧的硬性来解决一个重要的开放问题 。 我们表现出对武器( n-1, 其中武器数量为n-1) 的期待累积的遗憾。 为了最佳武器识别, 我们研究两种算法。 首先, 我们提出一个O(r) 手臂- 模拟的调整性回流算法, 以找到一个最优武器识别的快速适应性流算法 。 每一轮的手臂拉动法都是根据前几轮中观察到的结果决定的。 最佳武器( n-1, 其中n-1, 即武器的数量。 为了最佳武器识别, 我们研究两种算法。 首先, 我们提出一个最高级的调整性回流 。