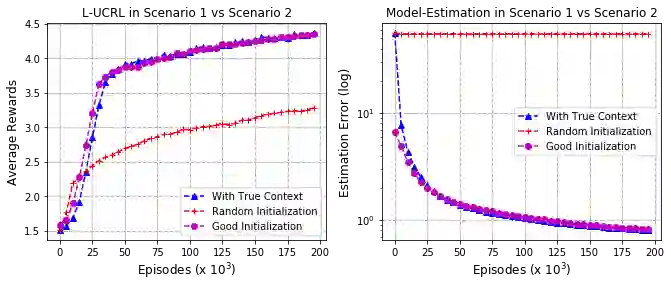
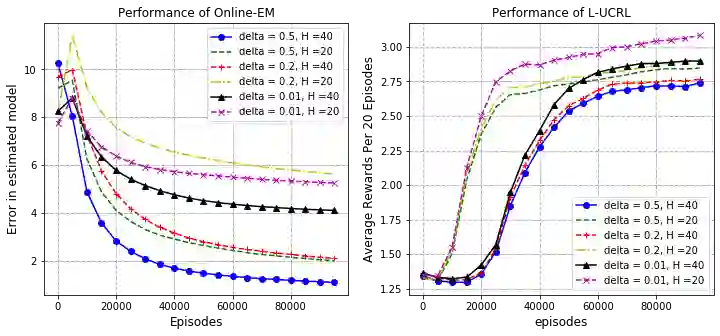
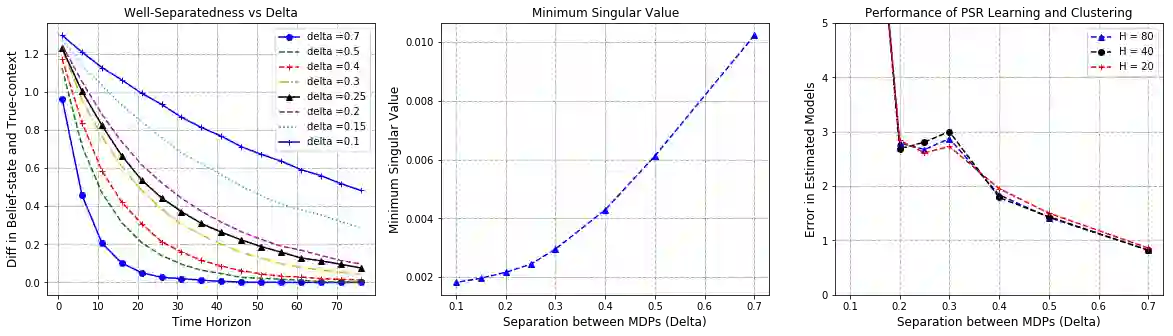
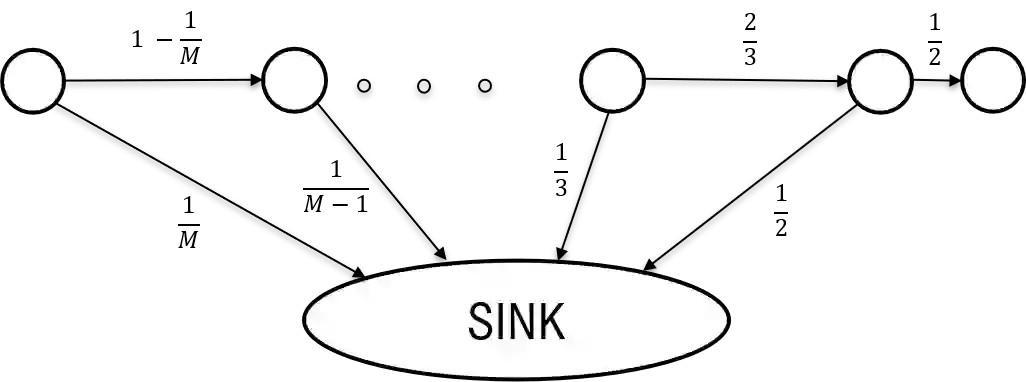
In this work, we consider the regret minimization problem for reinforcement learning in latent Markov Decision Processes (LMDP). In an LMDP, an MDP is randomly drawn from a set of $M$ possible MDPs at the beginning of the interaction, but the identity of the chosen MDP is not revealed to the agent. We first show that a general instance of LMDPs requires at least $\Omega((SA)^M)$ episodes to even approximate the optimal policy. Then, we consider sufficient assumptions under which learning good policies requires polynomial number of episodes. We show that the key link is a notion of separation between the MDP system dynamics. With sufficient separation, we provide an efficient algorithm with local guarantee, {\it i.e.,} providing a sublinear regret guarantee when we are given a good initialization. Finally, if we are given standard statistical sufficiency assumptions common in the Predictive State Representation (PSR) literature (e.g., Boots et al.) and a reachability assumption, we show that the need for initialization can be removed.
翻译:在这项工作中,我们考虑了潜伏的Markov决定程序(LMDP)中强化学习的最小化问题。在LMDP中,MDP随机地从互动开始时的一套可能的MDP中抽取出,但所选择的MDP的身份没有透露给代理人。我们首先表明,LMDP的一般例子至少需要$\Omega(SA)%M(M)美元,甚至接近最佳政策。然后,我们考虑了足够的假设,根据这些假设,学习好的政策需要多出几集。我们表明,关键联系是MDP系统动态之间的分离概念。在充分分离后,我们提供了一种具有当地保证的高效算法,即当我们得到良好的初始化时提供亚线性遗憾保证。最后,如果我们给预测性国家代表(PSR)文献中常见的标准统计充分性假设(例如,Boots et al.)和可实现的假设,我们表明,初始化的必要性是可以消除的。