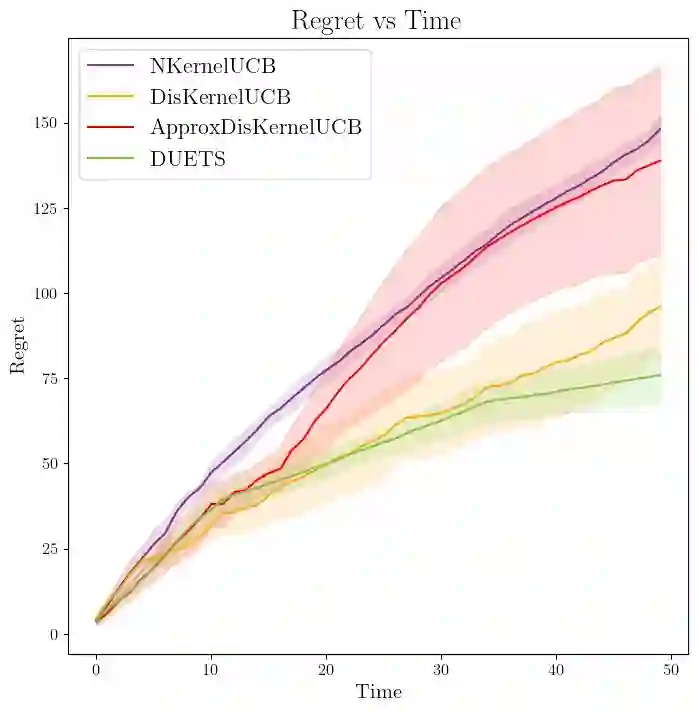
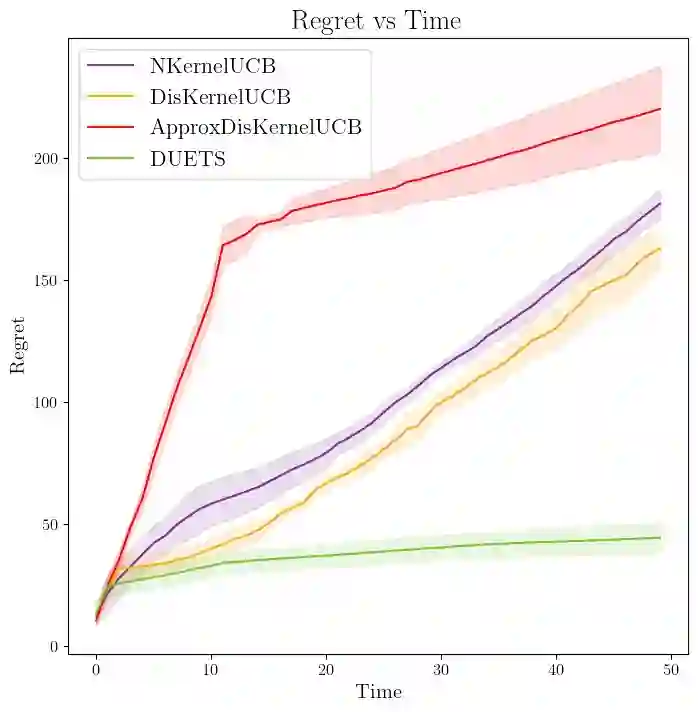
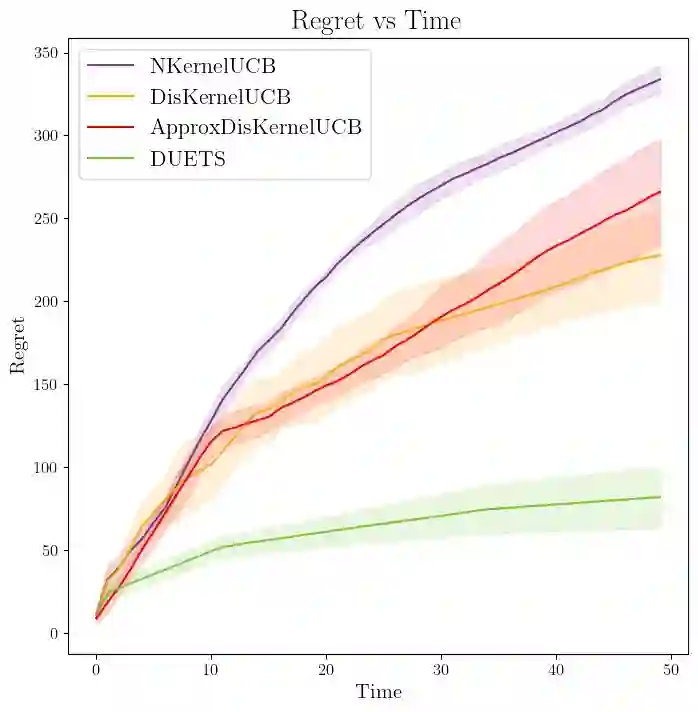
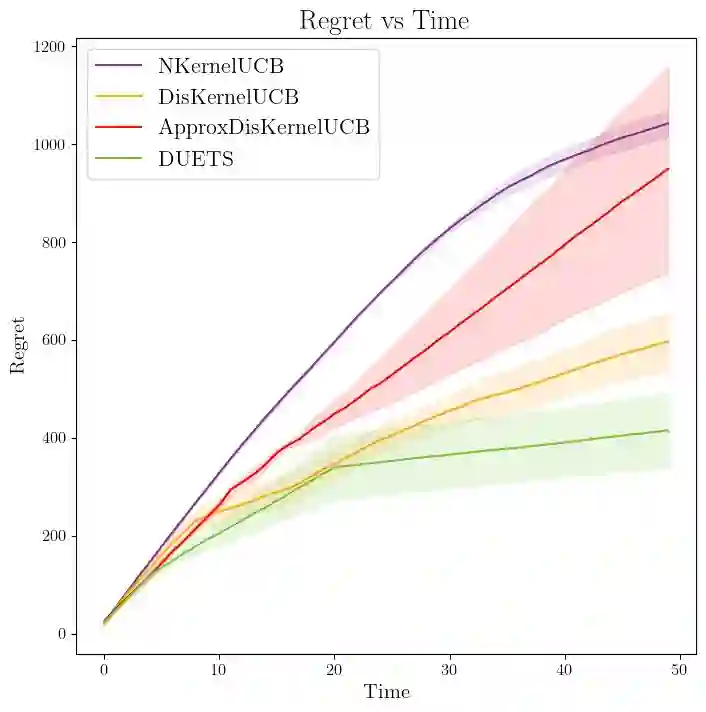
We consider distributed kernel bandits where $N$ agents aim to collaboratively maximize an unknown reward function that lies in a reproducing kernel Hilbert space. Each agent sequentially queries the function to obtain noisy observations at the query points. Agents can share information through a central server, with the objective of minimizing regret that is accumulating over time $T$ and aggregating over agents. We develop the first algorithm that achieves the optimal regret order (as defined by centralized learning) with a communication cost that is sublinear in both $N$ and $T$. The key features of the proposed algorithm are the uniform exploration at the local agents and shared randomness with the central server. Working together with the sparse approximation of the GP model, these two key components make it possible to preserve the learning rate of the centralized setting at a diminishing rate of communication.
翻译:我们考虑分布式核老虎机问题,其中 $N$ 个智能体协同最大化一个位于再生核希尔伯特空间中的未知奖励函数。每个智能体顺序查询该函数,在查询点获取带噪声的观测值。智能体可通过中央服务器共享信息,目标是最小化随时间 $T$ 累积并聚合所有智能体的遗憾值。我们提出了首个算法,在通信成本关于 $N$ 和 $T$ 均呈次线性增长的情况下,实现了(由集中式学习定义的)最优遗憾阶。该算法的关键特征在于局部智能体的均匀探索以及与中央服务器的共享随机性。这两个关键组件与高斯过程模型的稀疏近似协同工作,使得以递减的通信速率保持集中式设置的学习速率成为可能。