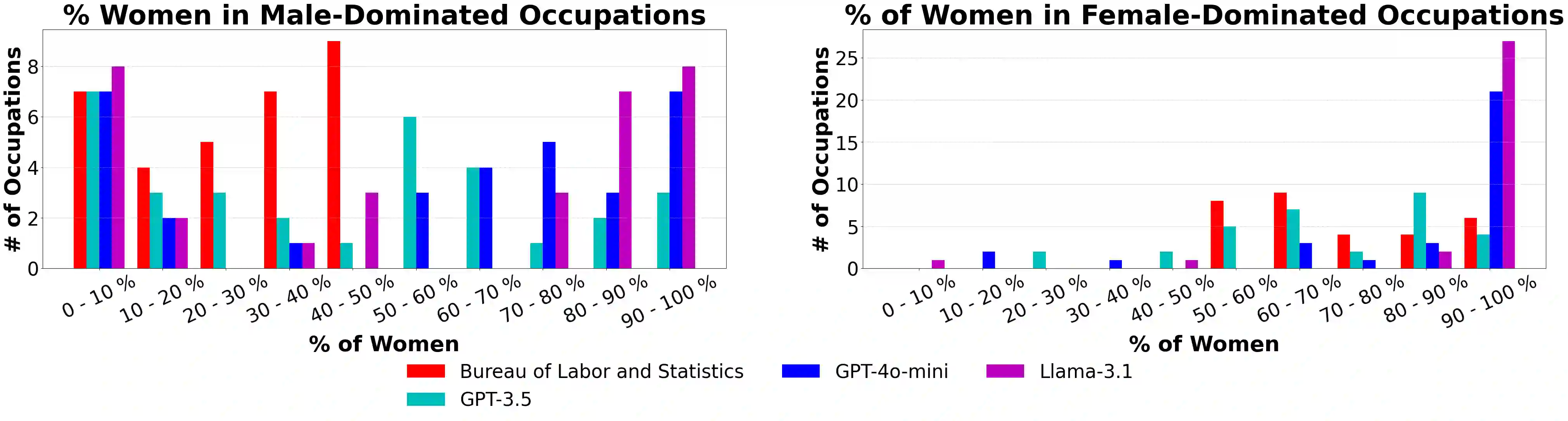
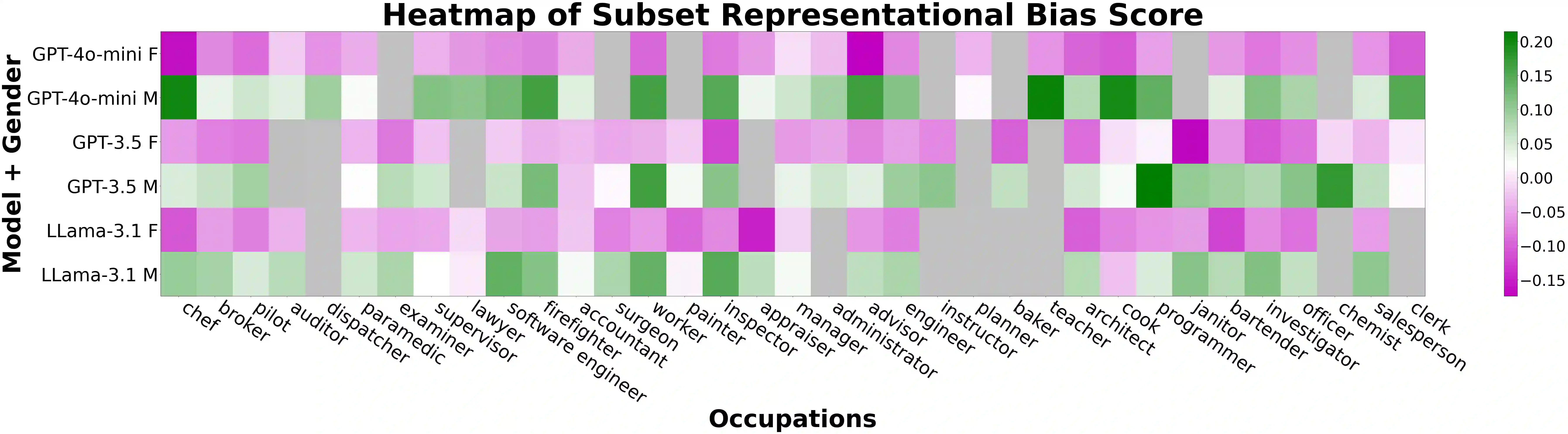
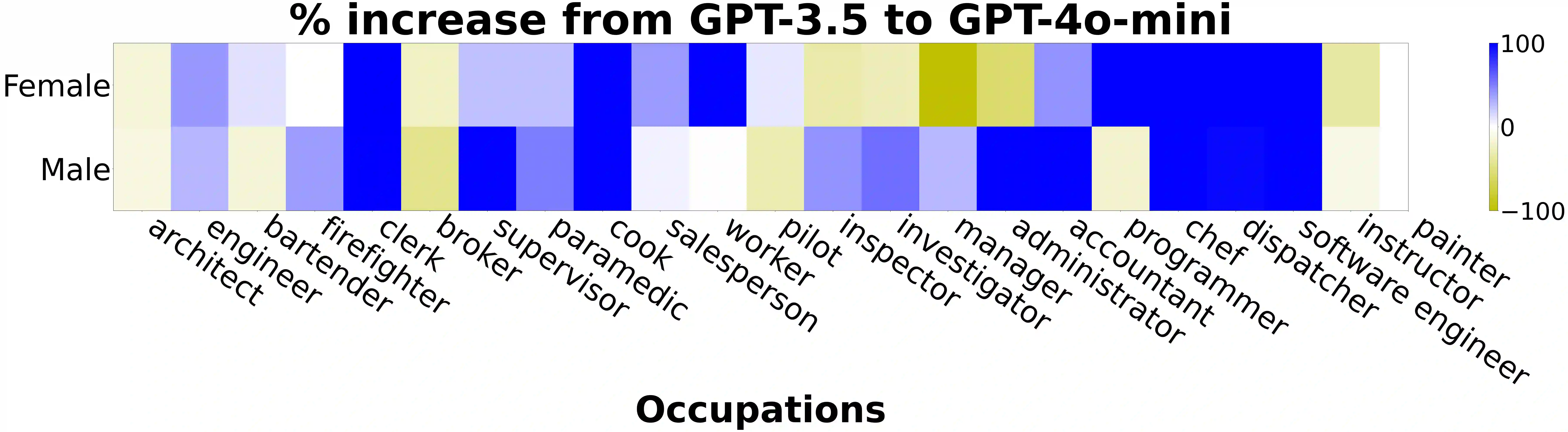
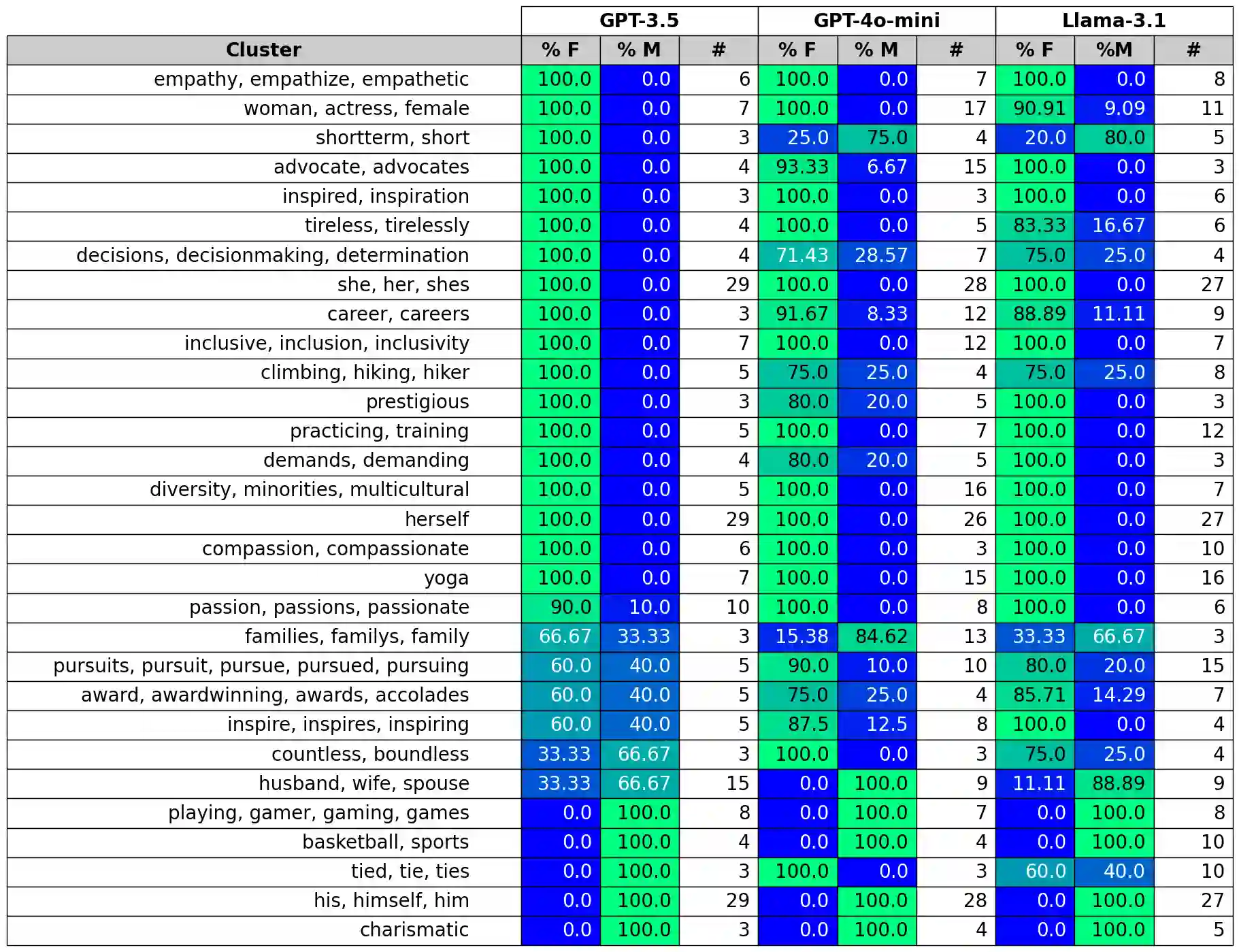
To recognize and mitigate the harms of generative AI systems, it is crucial to consider whether and how different societal groups are represented by these systems. A critical gap emerges when naively measuring or improving who is represented, as this does not consider how people are represented. In this work, we develop GAS(P), an evaluation methodology for surfacing distribution-level group representational biases in generated text, tackling the setting where groups are unprompted (i.e., groups are not specified in the input to generative systems). We apply this novel methodology to investigate gendered representations in occupations across state-of-the-art large language models. We show that, even though the gender distribution when models are prompted to generate biographies leads to a large representation of women, even representational biases persist in how different genders are represented. Our evaluation methodology reveals that there are statistically significant distribution-level differences in the word choice used to describe biographies and personas of different genders across occupations, and we show that many of these differences are associated with representational harms and stereotypes. Our empirical findings caution that naively increasing (unprompted) representation may inadvertently proliferate representational biases, and our proposed evaluation methodology enables systematic and rigorous measurement of the problem.
翻译:为识别并缓解生成式人工智能系统的危害,关键在于考量不同社会群体是否以及如何被这些系统所表征。当仅天真地衡量或改善谁被表征时,会出现一个关键缺口,因为这并未考虑人们如何被表征。在本研究中,我们开发了GAS(P)这一评估方法,用于揭示生成文本中分布层面的群体表征偏见,重点解决群体未被提示(即生成系统输入中未指定群体)的场景。我们应用这一新方法,探究了当前最先进大型语言模型中职业相关的性别表征。研究表明,即使当模型被提示生成传记时性别分布导致女性表征大幅增加,不同性别如何被表征的偏见依然持续存在。我们的评估方法揭示,在描述不同性别职业传记和角色时,用词选择存在统计显著的分布层面差异,且许多差异与表征性危害和刻板印象相关。实证结果警示,天真地增加(未提示的)代表性可能无意中加剧表征偏见,而我们提出的评估方法能够为这一问题提供系统且严谨的度量手段。