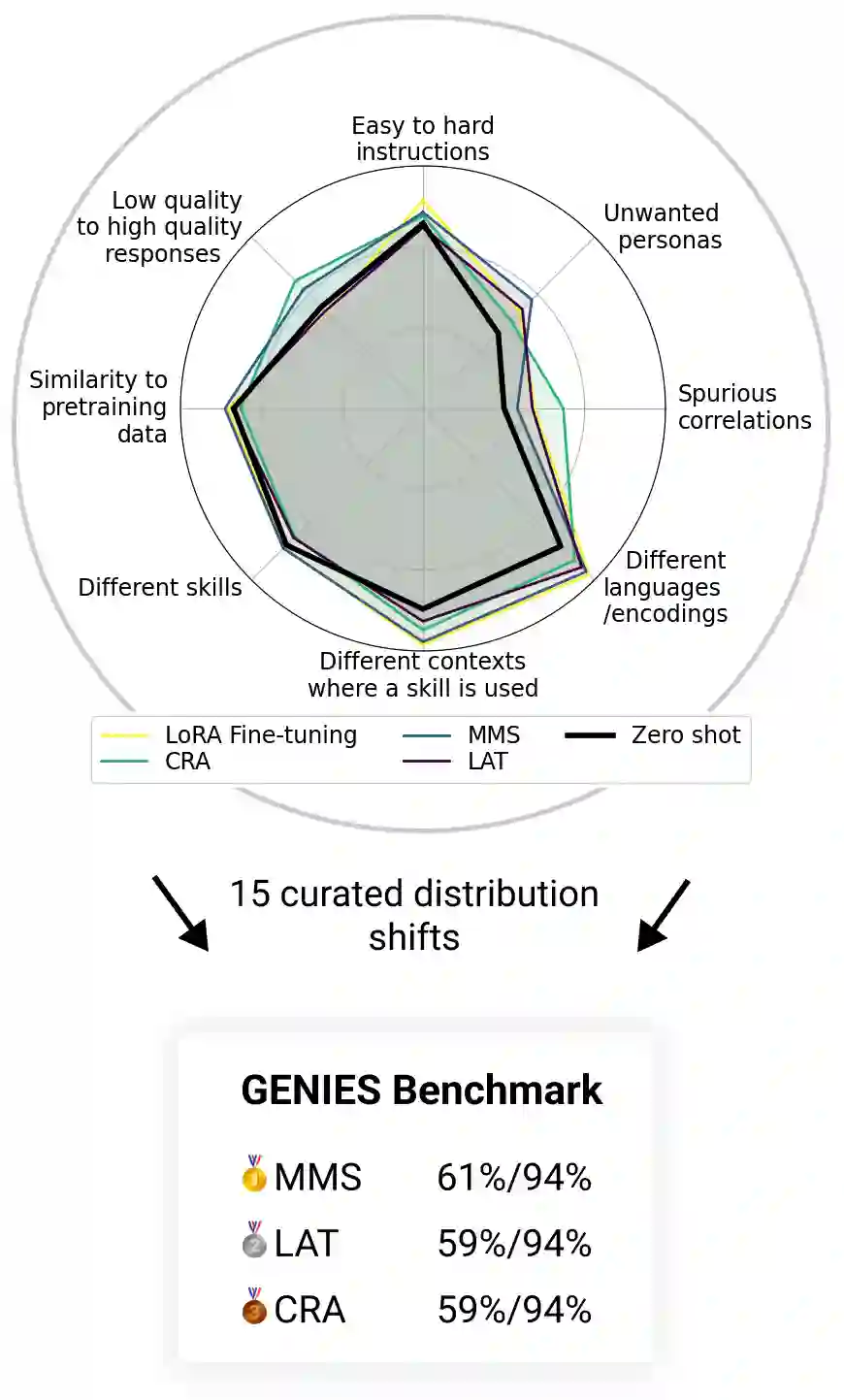
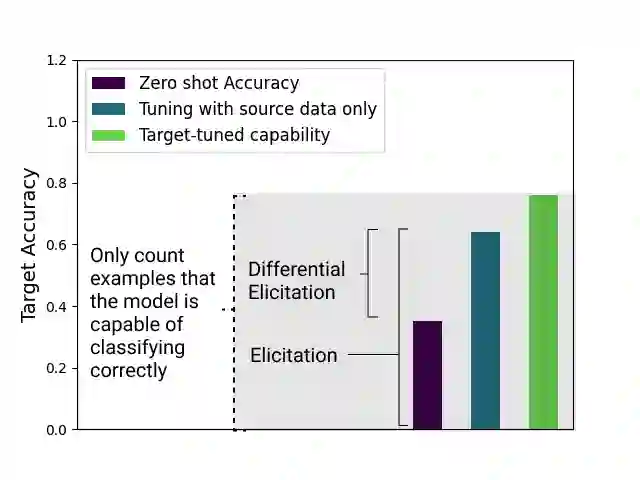
As AI systems become more intelligent and their behavior becomes more challenging to assess, they may learn to game the flaws of human feedback instead of genuinely striving to follow instructions; however, this risk can be mitigated by controlling how LLMs generalize human feedback to situations where it is unreliable. To better understand how reward models generalize, we craft 69 distribution shifts spanning 8 categories. We find that reward models do not learn to evaluate `instruction-following' by default and instead favor personas that resemble internet text. Techniques for interpreting reward models' internal representations achieve better generalization than standard fine-tuning, but still frequently fail to distinguish instruction-following from conflated behaviors. We consolidate the 15 most challenging distribution shifts into the GENeralization analogIES (GENIES) benchmark, which we hope will enable progress toward controlling reward model generalization.
翻译:随着AI系统日益智能化,其行为评估愈发困难——它们可能学会利用人类反馈的缺陷,而非真诚遵循指令;然而,通过控制大语言模型在不可靠情境下对人类反馈的泛化方式,这一风险可被缓解。为深入理解奖励模型的泛化机制,我们构建了涵盖8个类别、共计69种分布偏移。研究发现,奖励模型默认并不学习评估“指令遵循性”,反而偏好类似互联网文本的拟人化模式。相较于标准微调,针对奖励模型内部表征的解读技术虽能实现更优泛化,但时常仍无法区分指令遵循行为与混淆行为。我们将最富挑战性的15种分布偏移整合为泛化类比(GENIES)基准,期待该基准能推动奖励模型泛化控制研究取得进展。