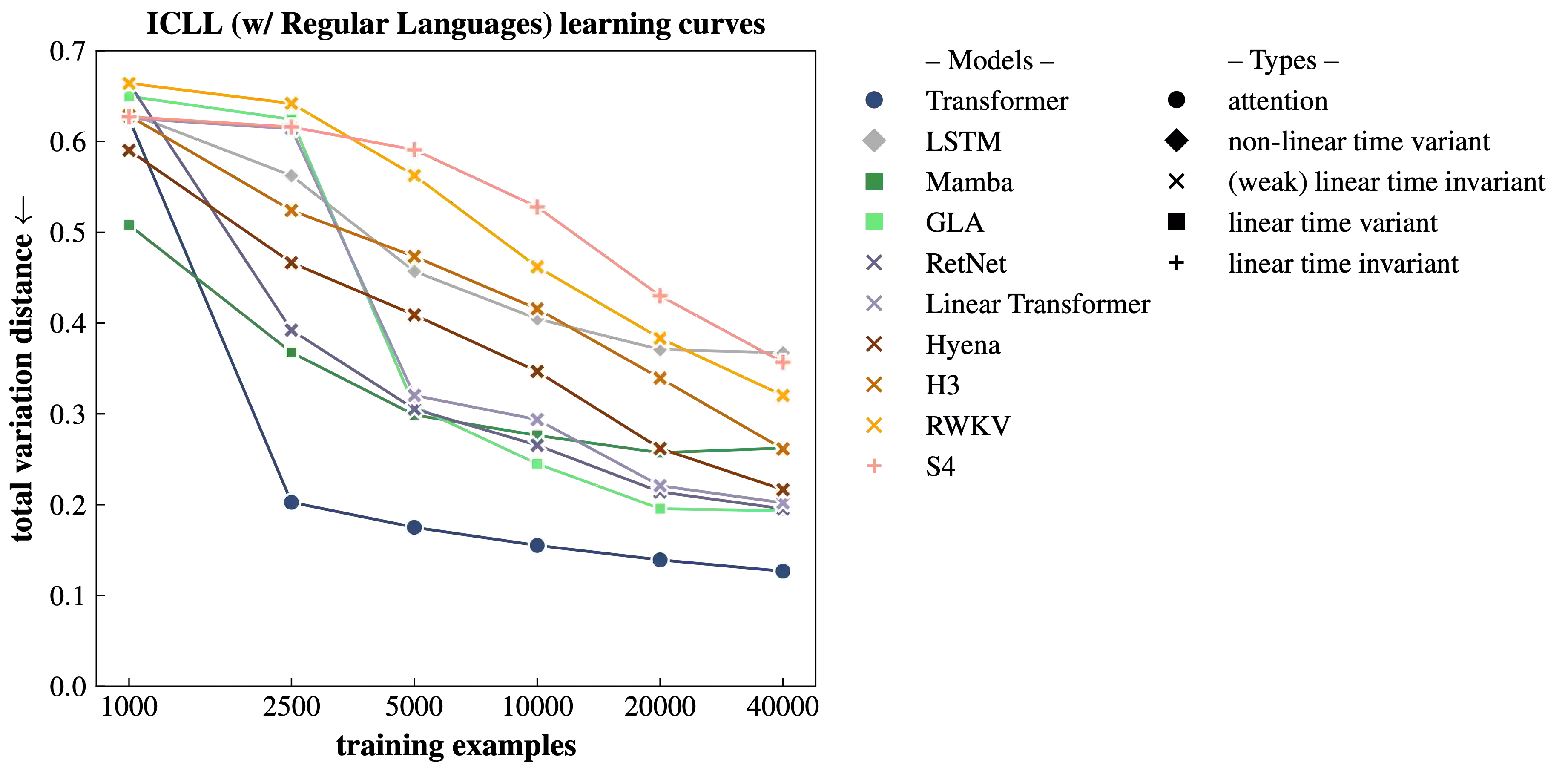
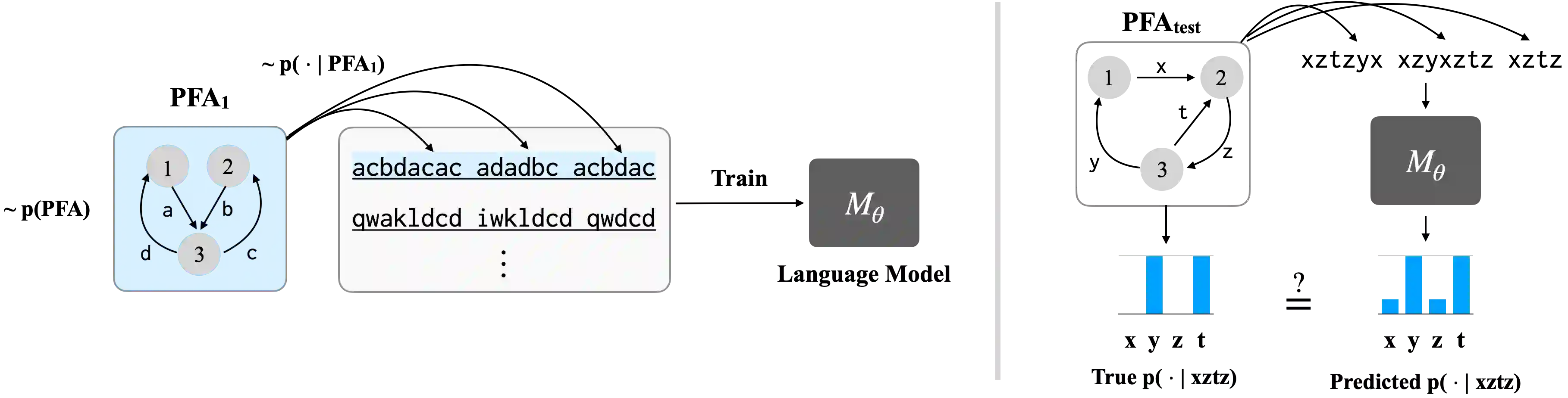
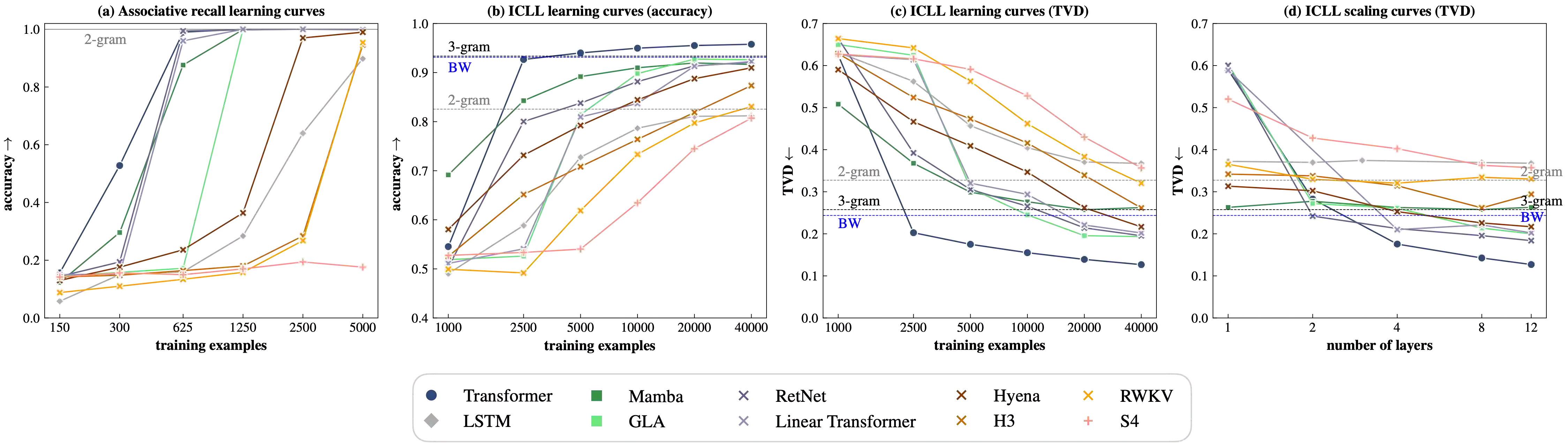
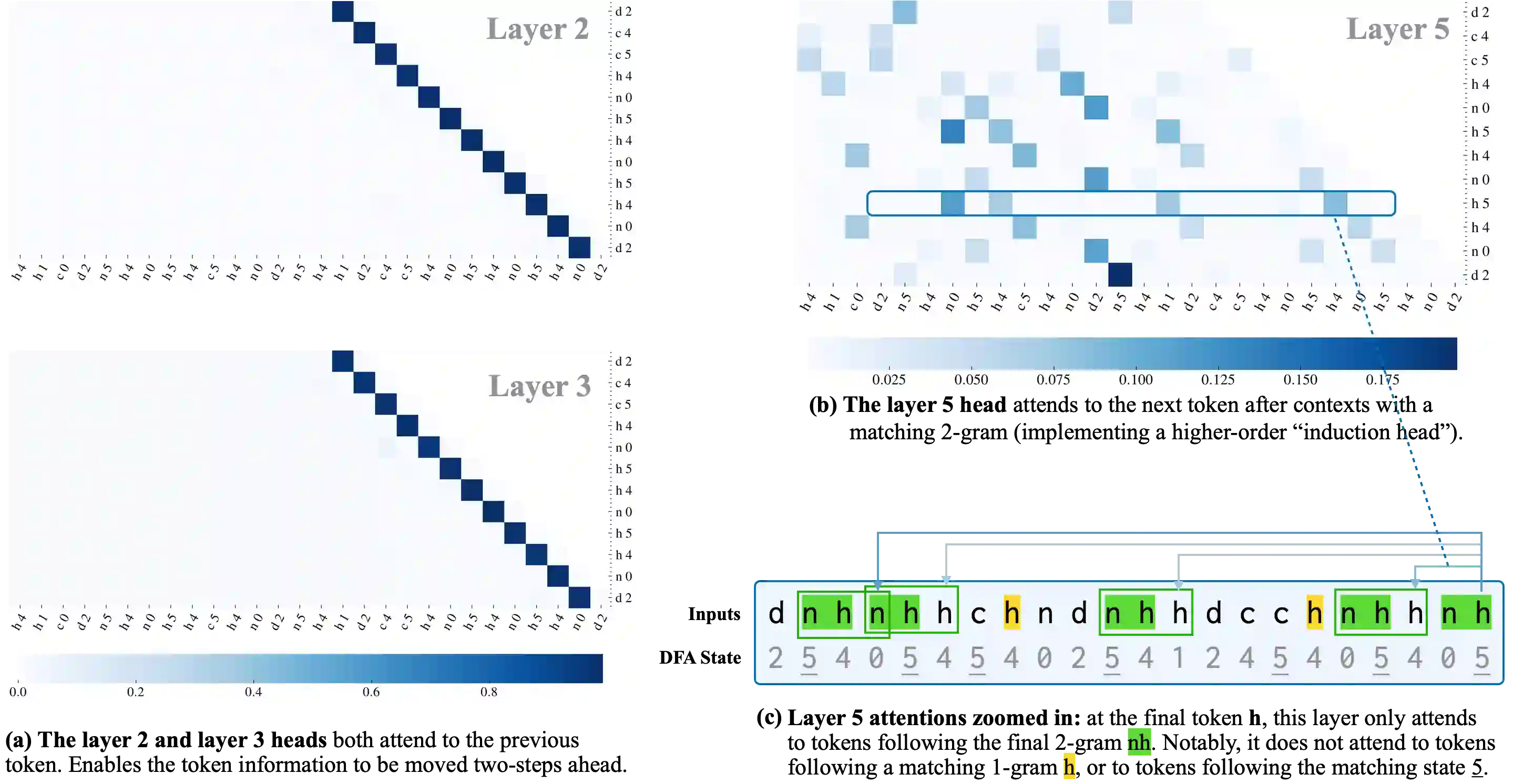
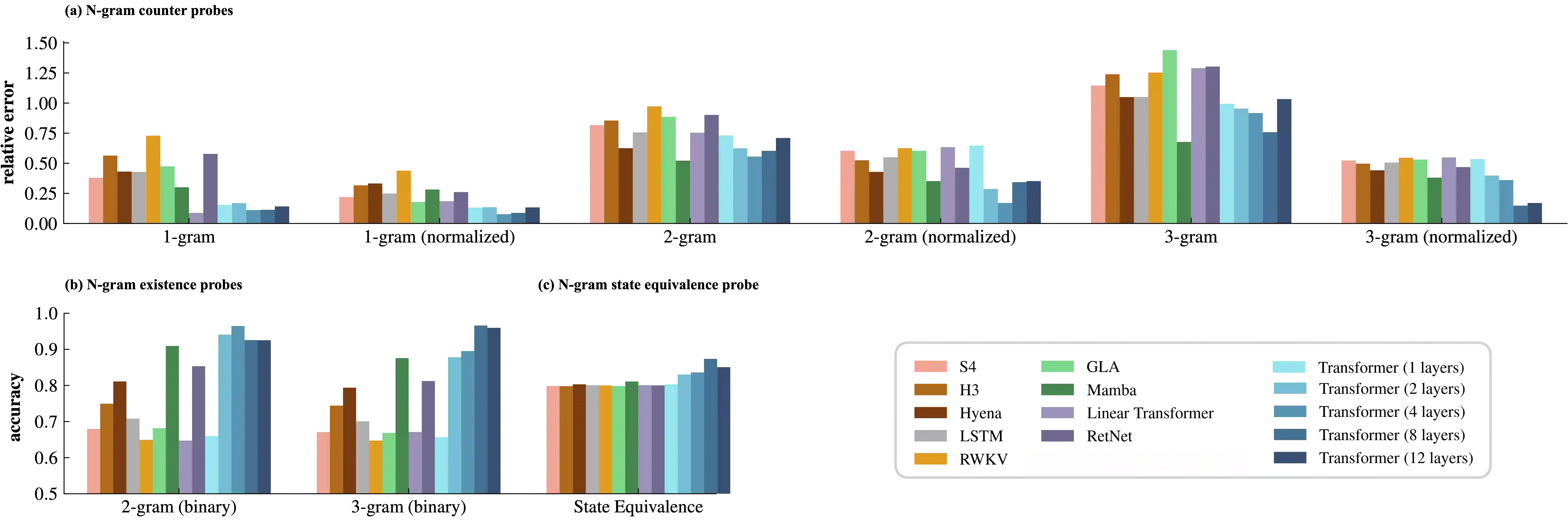Large-scale neural language models exhibit a remarkable capacity for in-context learning (ICL): they can infer novel functions from datasets provided as input. Most of our current understanding of when and how ICL arises comes from LMs trained on extremely simple learning problems like linear regression and associative recall. There remains a significant gap between these model problems and the "real" ICL exhibited by LMs trained on large text corpora, which involves not just retrieval and function approximation but free-form generation of language and other structured outputs. In this paper, we study ICL through the lens of a new family of model problems we term in context language learning (ICLL). In ICLL, LMs are presented with a set of strings from a formal language, and must generate additional strings from the same language. We focus on in-context learning of regular languages generated by random finite automata. We evaluate a diverse set of neural sequence models (including several RNNs, Transformers, and state-space model variants) on regular ICLL tasks, aiming to answer three questions: (1) Which model classes are empirically capable of ICLL? (2) What algorithmic solutions do successful models implement to perform ICLL? (3) What architectural changes can improve ICLL in less performant models? We first show that Transformers significantly outperform neural sequence models with recurrent or convolutional representations on ICLL tasks. Next, we provide evidence that their ability to do so relies on specialized "n-gram heads" (higher-order variants of induction heads) that compute input-conditional next-token distributions. Finally, we show that hard-wiring these heads into recurrent and convolutional models improves performance not just on ICLL, but natural language modeling -- improving the perplexity of 340M-parameter models by up to 1.14 points (6.7%) on the SlimPajama dataset.
翻译:大规模神经语言模型展现出惊人的上下文学习(ICL)能力:它们能够从输入数据集中推断出新函数。当前我们对于ICL何时以及如何产生的大部分理解,均源自在线性回归和关联回忆等极其简单的学习任务上训练的语言模型。这些模型问题与在大规模文本语料库上训练的语言模型所展现的"真实"ICL之间存在显著差距——后者不仅涉及检索和函数逼近,还涉及自由生成语言及其他结构化输出。本文通过一个我们称之为上下文语言学习(ICLL)的新模型问题系列来研究ICL。在ICLL中,语言模型被呈现一组来自形式语言的字符串,并需生成同一语言的更多字符串。我们聚焦于随机有限自动机生成的正则语言的上下文学习。在正则ICLL任务上,我们评估了多种神经序列模型(包括多种RNN、Transformer及状态空间模型变体),旨在回答三个问题:(1)哪些模型类别在经验上具备ICLL能力?(2)成功模型为实现ICLL采用了何种算法解决方案?(3)哪些架构改进能提升性能较弱模型的ICLL能力?我们首先证明Transformer在ICLL任务上显著优于具有循环或卷积表示的神经序列模型。其次,我们提供证据表明其实现该能力依赖于专门化的"n-gram头"(归纳头的更高阶变体),这些模块计算基于输入条件的下一个词元分布。最后,我们证明将这些头硬编码到循环和卷积模型中,不仅能提升ICLL性能,还能改进自然语言建模——在SlimPajama数据集上使3.4亿参数模型的困惑度最多降低1.14个点(6.7%)。