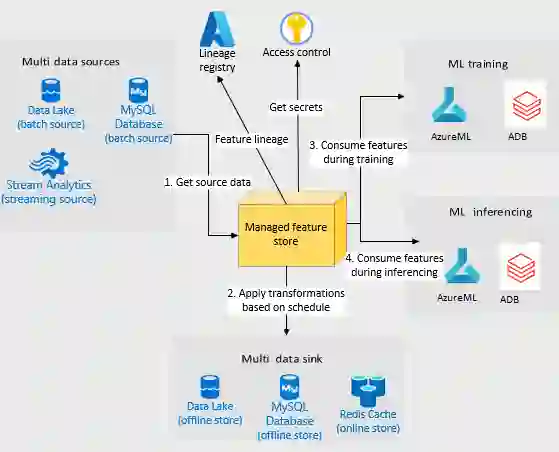
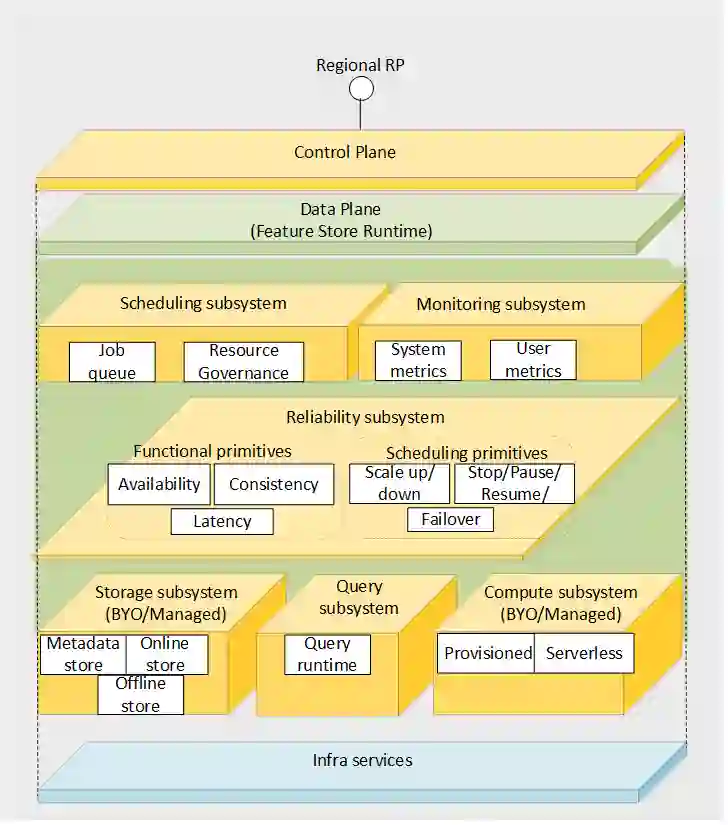
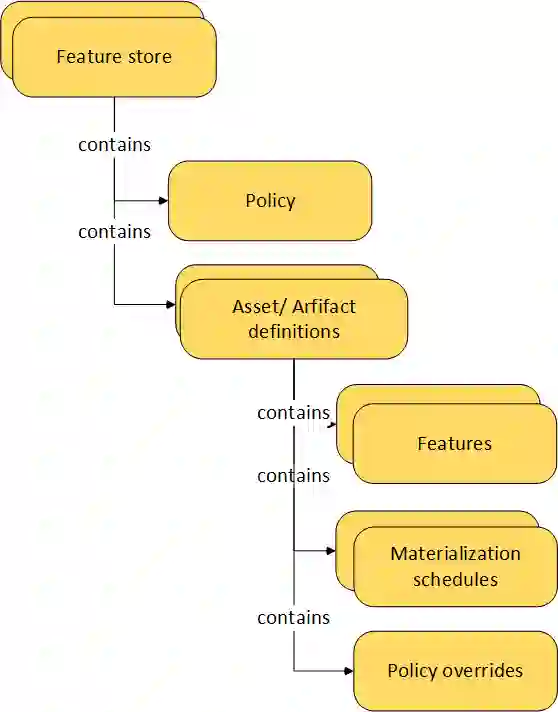
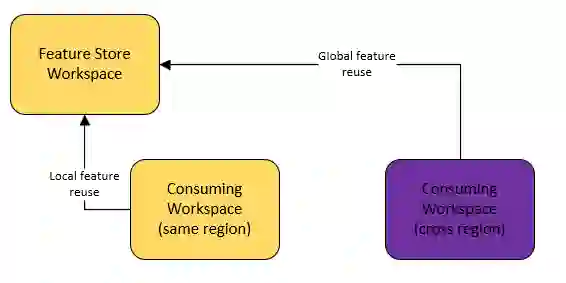
Companies are using machine learning to solve real-world problems and are developing hundreds to thousands of features in the process. They are building feature engineering pipelines as part of MLOps life cycle to transform data from various data sources and materialize the same for future consumption. Without feature stores, different teams across various business groups would maintain the above process independently, which can lead to conflicting and duplicated features in the system. Data scientists find it hard to search for and reuse existing features and it is painful to maintain version control. Furthermore, feature correctness violations related to online (inferencing) - offline (training) skews and data leakage are common. Although the machine learning community has extensively discussed the need for feature stores and their purpose, this paper aims to capture the core architectural components that make up a managed feature store and to share the design learning in building such a system.
翻译:企业正利用机器学习解决实际问题,并在过程中开发数百至数千个特征。作为MLOps生命周期的一部分,他们构建特征工程流水线,将来自不同数据源的数据进行转换并物化以供未来使用。若缺乏特征存储,不同业务组中的各个团队将独立维护上述流程,可能导致系统中特征冲突与重复。数据科学家难以检索和复用现有特征,版本控制维护也颇为棘手。此外,与在线(推理)与离线(训练)不一致及数据泄漏相关的特征正确性问题屡见不鲜。尽管机器学习社区已广泛讨论特征存储的需求及目的,本文旨在阐述构成托管式特征存储的核心架构组件,并分享构建此类系统的设计经验。