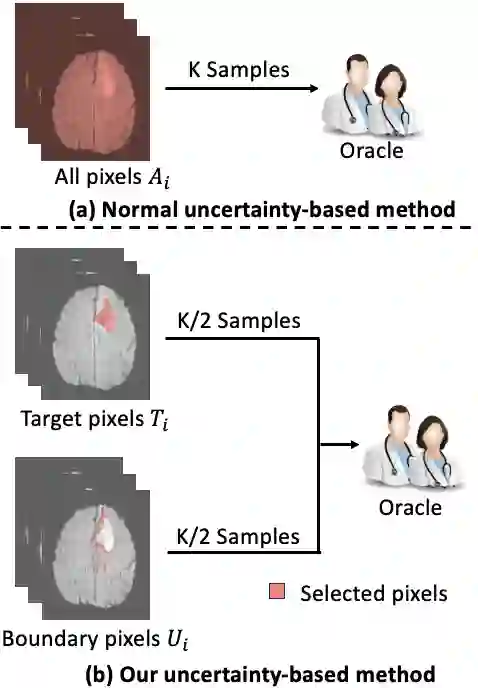
Active learning (AL) has found wide applications in medical image segmentation, aiming to alleviate the annotation workload and enhance performance. Conventional uncertainty-based AL methods, such as entropy and Bayesian, often rely on an aggregate of all pixel-level metrics. However, in imbalanced settings, these methods tend to neglect the significance of target regions, eg., lesions, and tumors. Moreover, uncertainty-based selection introduces redundancy. These factors lead to unsatisfactory performance, and in many cases, even underperform random sampling. To solve this problem, we introduce a novel approach called the Selective Uncertainty-based AL, avoiding the conventional practice of summing up the metrics of all pixels. Through a filtering process, our strategy prioritizes pixels within target areas and those near decision boundaries. This resolves the aforementioned disregard for target areas and redundancy. Our method showed substantial improvements across five different uncertainty-based methods and two distinct datasets, utilizing fewer labeled data to reach the supervised baseline and consistently achieving the highest overall performance. Our code is available at https://github.com/HelenMa9998/Selective\_Uncertainty\_AL.
翻译:主动学习(AL)已广泛应用于医学图像分割,旨在减轻标注工作量并提升性能。传统基于不确定性的主动学习方法(如熵方法和贝叶斯方法)通常依赖于对所有像素级指标的汇总。然而,在类别不平衡场景下,这些方法往往忽略目标区域(如病变和肿瘤)的重要性。此外,基于不确定性的样本选择会引入冗余。这些因素导致性能不佳,在许多情况下甚至不如随机采样。为解决此问题,我们提出一种名为“基于选择性的不确定性主动学习”的新方法,避免对所有像素指标进行求和的传统做法。通过过滤过程,我们的策略优先选择目标区域内的像素以及靠近决策边界的像素,从而解决上述对目标区域的忽视及冗余问题。我们的方法在五种不同的基于不确定性的方法和两个不同的数据集上均展现出显著改进,能够使用更少的标注数据达到监督学习的基线水平,并始终实现最优的整体性能。我们的代码已开源,见https://github.com/HelenMa9998/Selective\_Uncertainty\_AL。