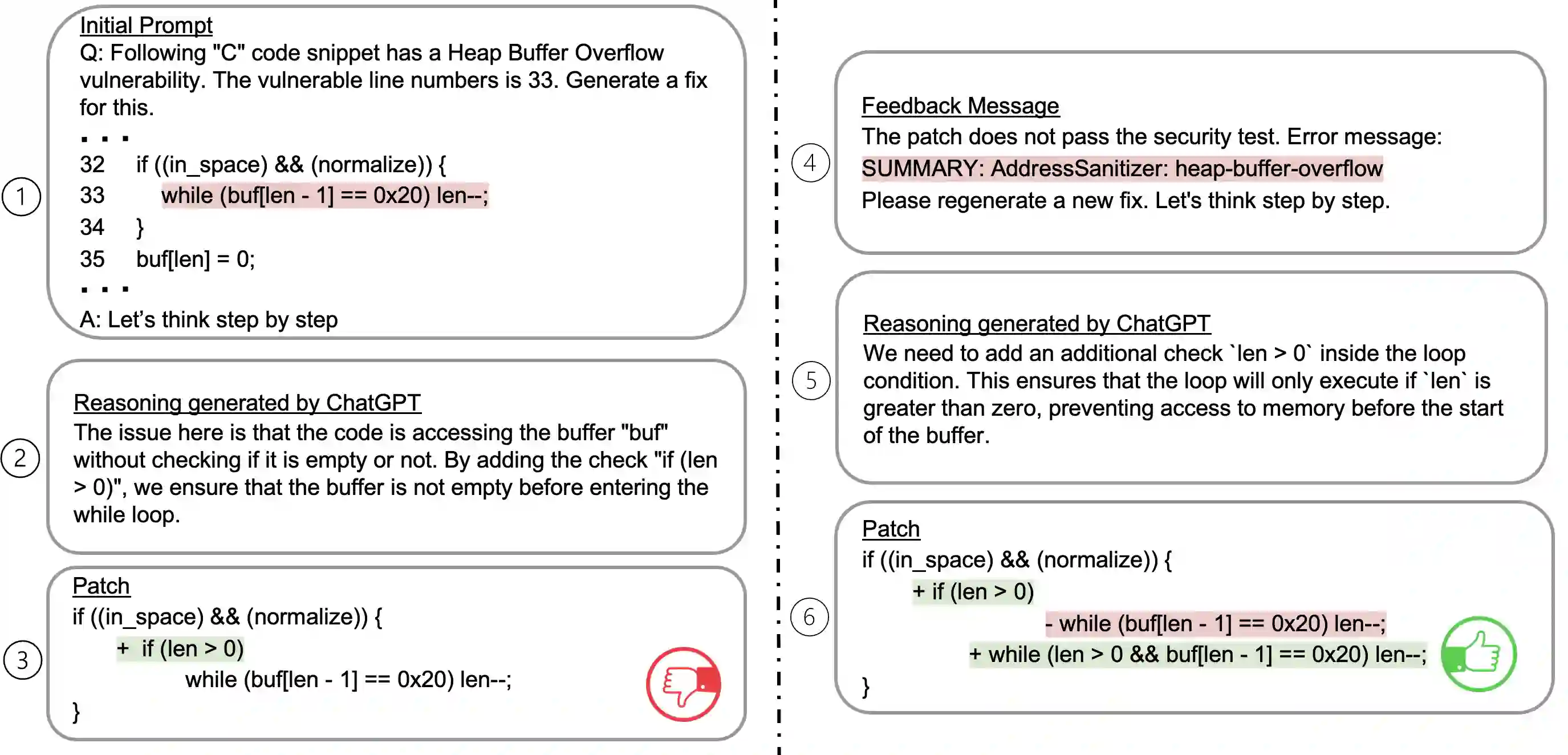
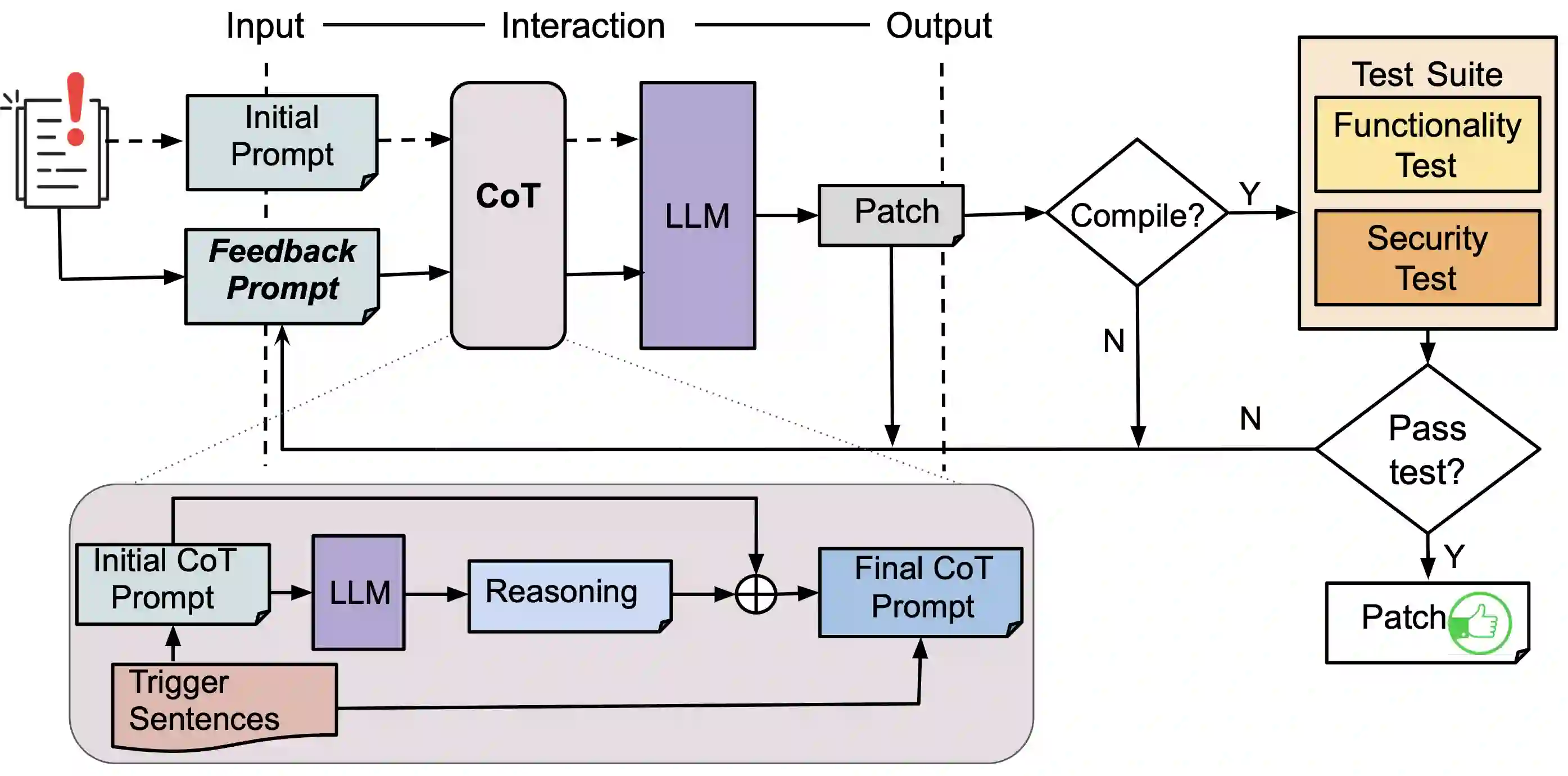
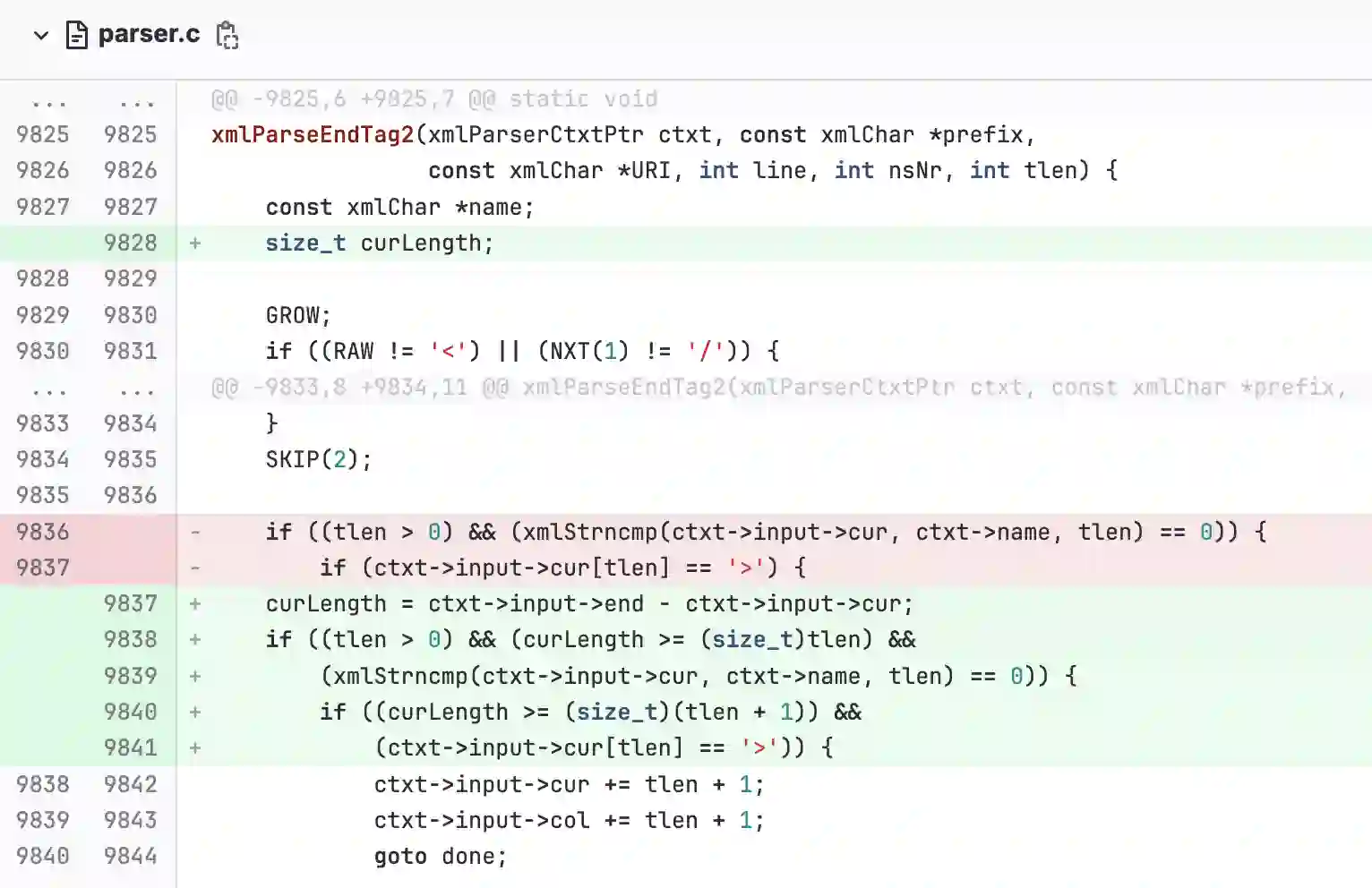
Recent work in automated program repair (APR) proposes the use of reasoning and patch validation feedback to reduce the semantic gap between the LLMs and the code under analysis. The idea has been shown to perform well for general APR, but its effectiveness in other particular contexts remains underexplored. In this work, we assess the impact of reasoning and patch validation feedback to LLMs in the context of vulnerability repair, an important and challenging task in security. To support the evaluation, we present VRpilot, an LLM-based vulnerability repair technique based on reasoning and patch validation feedback. VRpilot (1) uses a chain-of-thought prompt to reason about a vulnerability prior to generating patch candidates and (2) iteratively refines prompts according to the output of external tools (e.g., compiler, code sanitizers, test suite, etc.) on previously-generated patches. To evaluate performance, we compare VRpilot against the state-of-the-art vulnerability repair techniques for C and Java using public datasets from the literature. Our results show that VRpilot generates, on average, 14% and 7.6% more correct patches than the baseline techniques on C and Java, respectively. We show, through an ablation study, that reasoning and patch validation feedback are critical. We report several lessons from this study and potential directions for advancing LLM-empowered vulnerability repair
翻译:自动化程序修复(APR)领域的最新研究提出利用推理与补丁验证反馈来缩小大型语言模型(LLM)与待分析代码之间的语义鸿沟。该思路在通用APR任务中已表现出良好性能,但其在其他特定场景中的有效性仍有待深入探索。本研究在安全领域重要且富有挑战性的漏洞修复任务背景下,系统评估了推理与补丁验证反馈对LLM的影响。为支撑评估工作,我们提出了VRpilot——一种基于推理与补丁验证反馈的LLM漏洞修复技术。VRpilot具备两大特征:(1)在生成补丁候选方案前,采用思维链提示对漏洞进行推理分析;(2)依据外部工具(如编译器、代码净化器、测试套件等)对历史生成补丁的反馈结果,迭代优化提示策略。为评估性能,我们使用文献中的公开数据集,将VRpilot与当前最先进的C语言及Java漏洞修复技术进行对比。实验结果表明:在C语言和Java数据集上,VRpilot平均分别比基线技术多生成14%和7.6%的正确补丁。通过消融实验,我们验证了推理机制与补丁验证反馈的关键作用。本研究总结出若干重要发现,并为推进LLM赋能的漏洞修复技术提出了潜在发展方向。