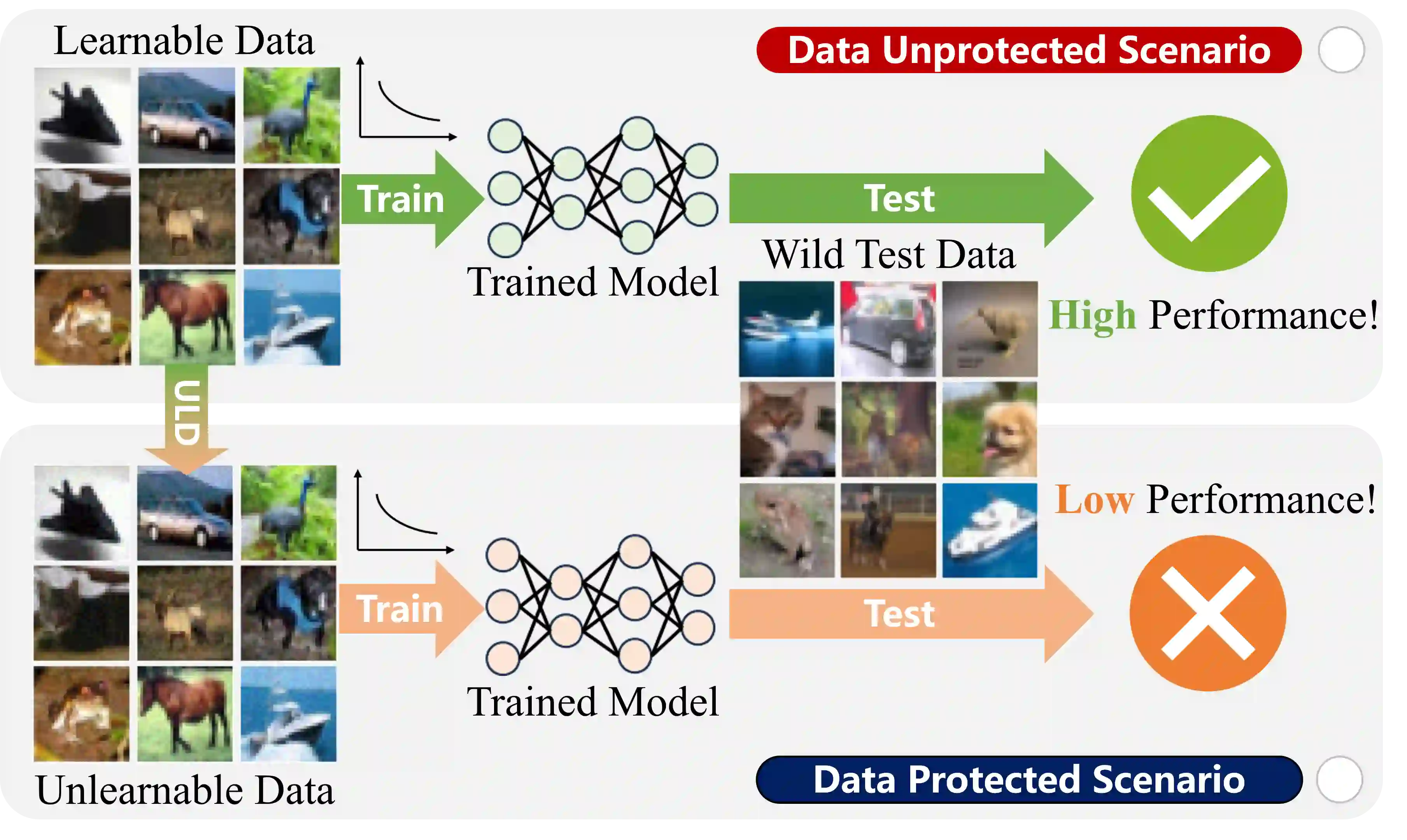
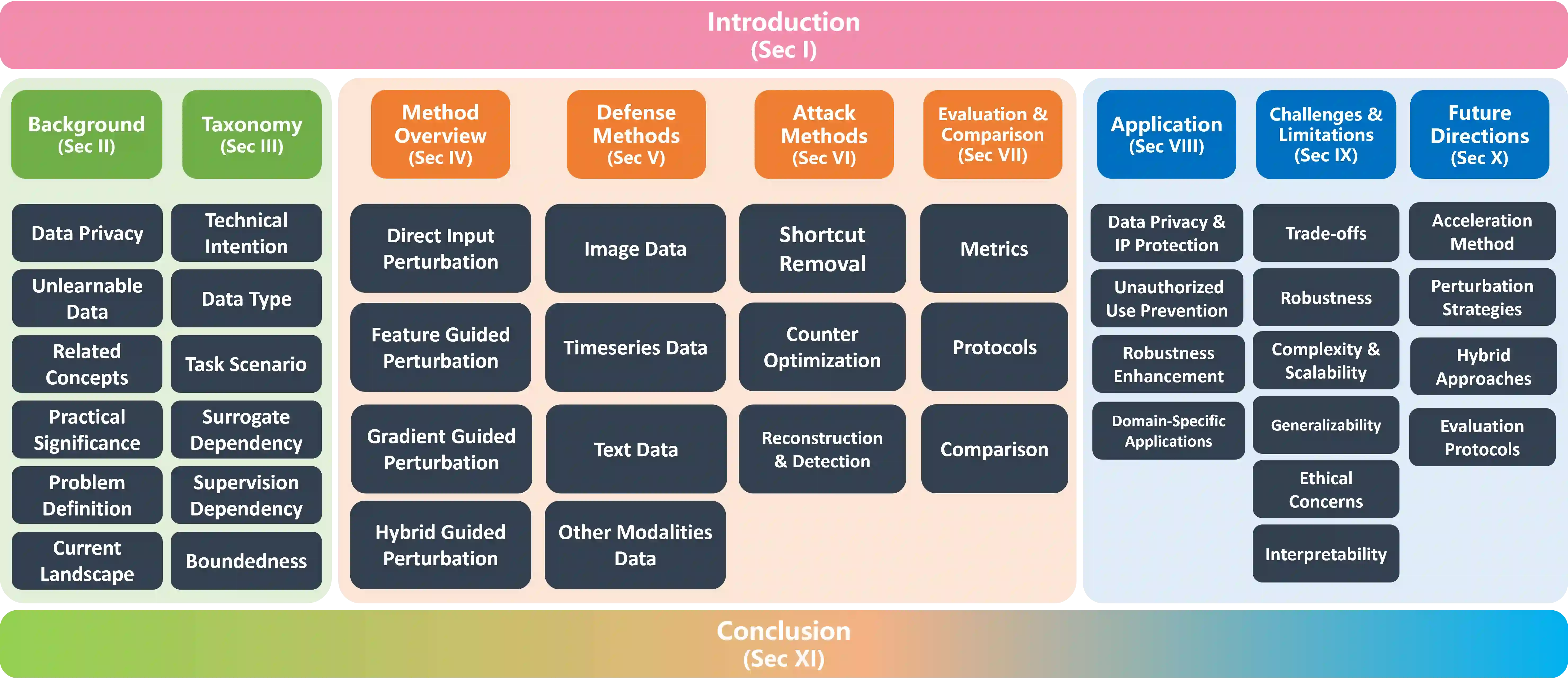
Unlearnable data (ULD) has emerged as an innovative defense technique to prevent machine learning models from learning meaningful patterns from specific data, thus protecting data privacy and security. By introducing perturbations to the training data, ULD degrades model performance, making it difficult for unauthorized models to extract useful representations. Despite the growing significance of ULD, existing surveys predominantly focus on related fields, such as adversarial attacks and machine unlearning, with little attention given to ULD as an independent area of study. This survey fills that gap by offering a comprehensive review of ULD, examining unlearnable data generation methods, public benchmarks, evaluation metrics, theoretical foundations and practical applications. We compare and contrast different ULD approaches, analyzing their strengths, limitations, and trade-offs related to unlearnability, imperceptibility, efficiency and robustness. Moreover, we discuss key challenges, such as balancing perturbation imperceptibility with model degradation and the computational complexity of ULD generation. Finally, we highlight promising future research directions to advance the effectiveness and applicability of ULD, underscoring its potential to become a crucial tool in the evolving landscape of data protection in machine learning.
翻译:不可学习数据作为一种创新的防御技术,旨在防止机器学习模型从特定数据中学习有意义的模式,从而保护数据隐私与安全。通过对训练数据引入扰动,不可学习数据能够降低模型性能,使未经授权的模型难以提取有效的特征表示。尽管不可学习数据的重要性日益凸显,现有综述主要集中于对抗攻击和机器遗忘等相关领域,而鲜少将其作为一个独立研究方向进行系统探讨。本综述填补了这一空白,对不可学习数据进行了全面回顾,涵盖不可学习数据生成方法、公共基准测试、评估指标、理论基础与实际应用。我们对比分析了不同的不可学习数据方法,探讨其在不可学习性、不可感知性、效率与鲁棒性等方面的优势、局限性与权衡关系。此外,我们讨论了关键挑战,例如如何在扰动不可感知性与模型性能退化之间取得平衡,以及不可学习数据生成的计算复杂度问题。最后,我们展望了未来有前景的研究方向,以推动不可学习数据在效能与适用性方面的发展,强调其有望成为机器学习数据保护领域演进过程中的关键工具。