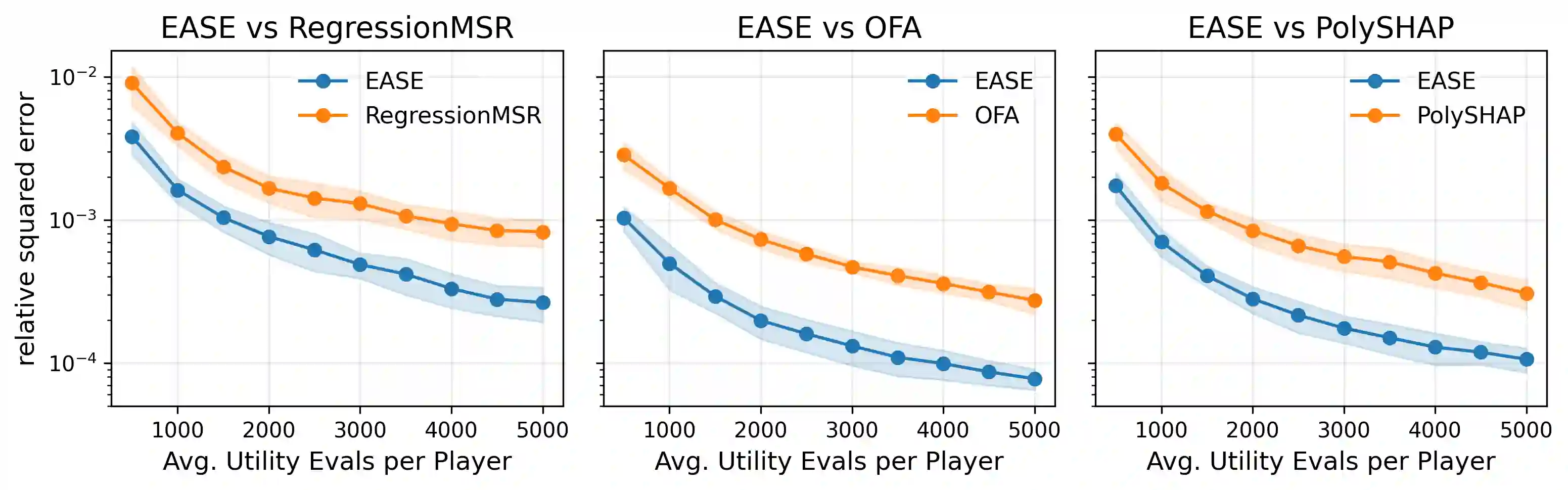
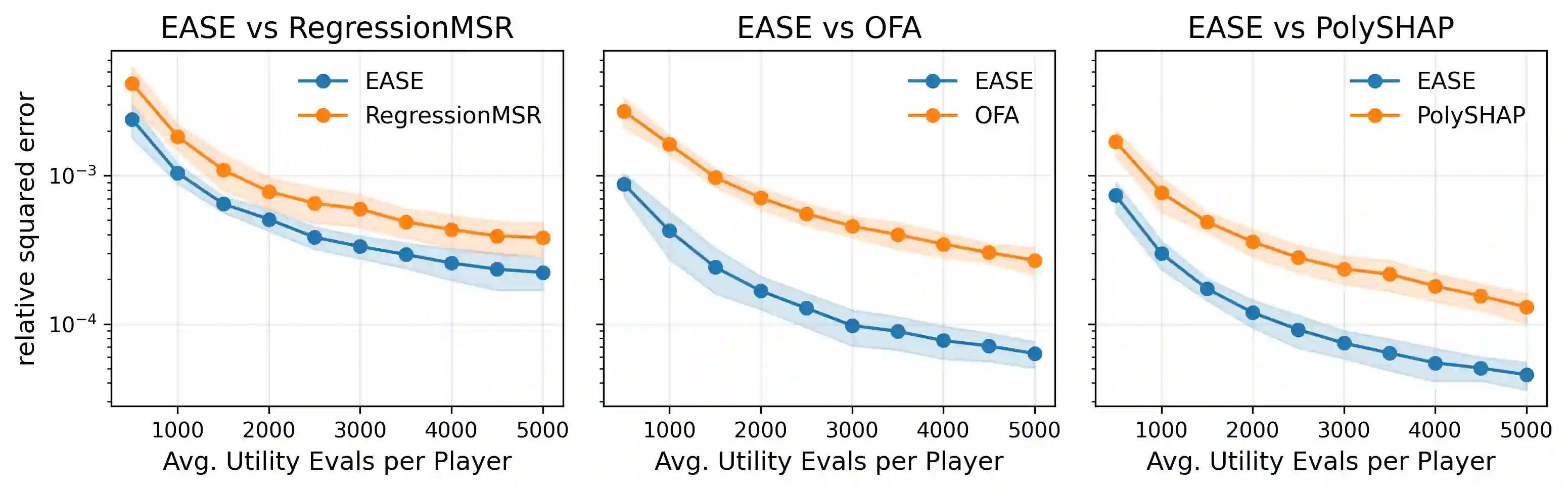
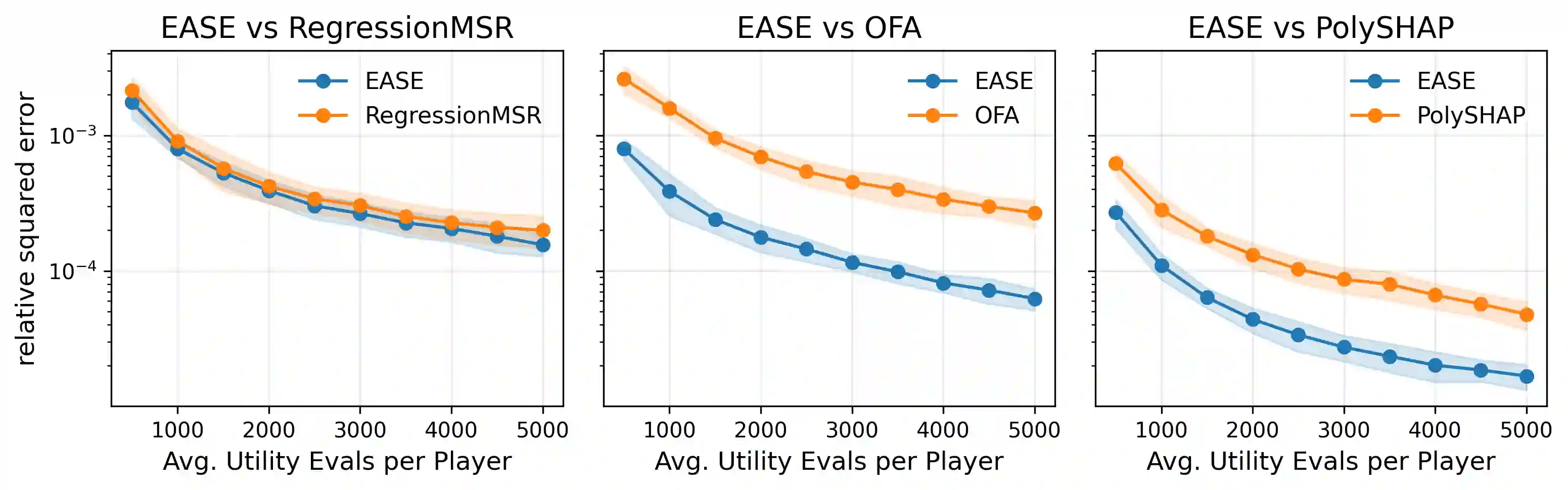
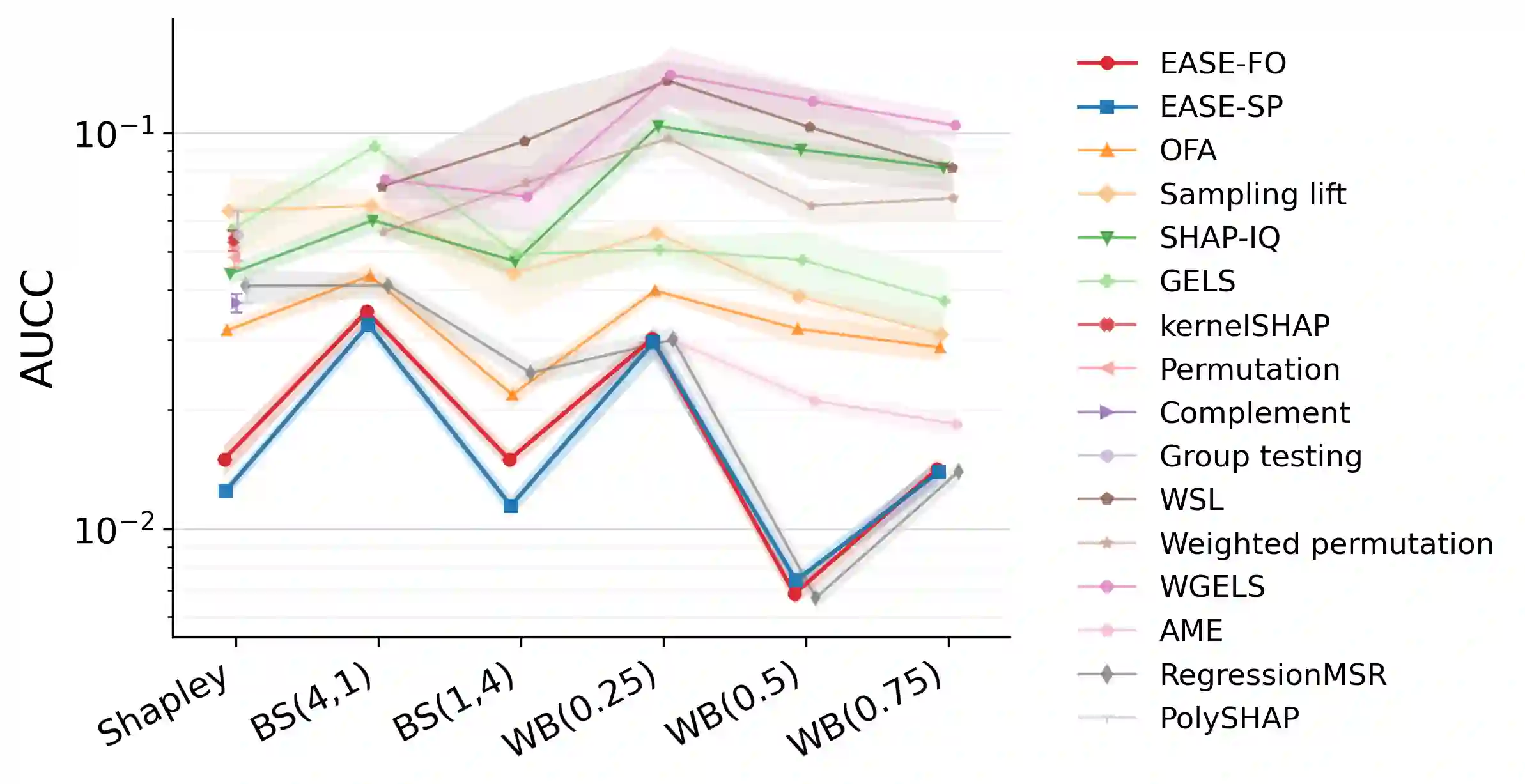
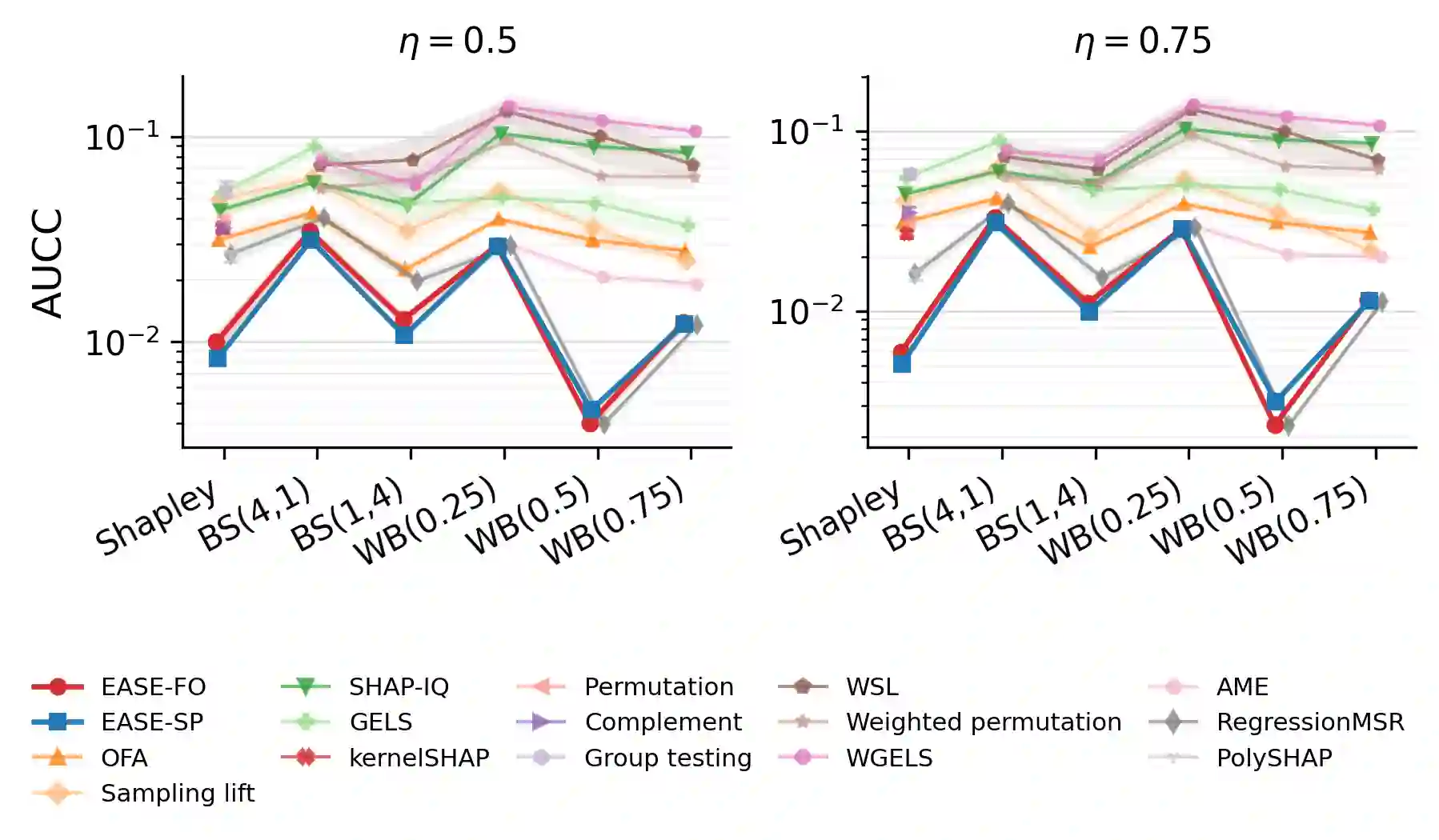
Probabilistic values, including Shapley values and semivalues, provide a model-agnostic framework to attribute the behavior of a black-box model to data points or features, with a wide range of applications including explainable artificial intelligence and data valuation. However, their exact computation requires utility evaluations over exponentially many coalitions, making Monte Carlo approximation essential in modern machine learning applications. Existing estimators are often developed through different identification strategies, including weighted averages, self-normalized weighting, regression adjustment, and weighted least squares. Our key observation is that these seemingly distinct constructions share a common first-order error structure, in which the leading term is an augmented inverse-probability weighted influence term determined by the sampling law and a working surrogate function. This first-order representation yields an explicit expression for the leading mean squared error (MSE), which characterizes how the sampling law and the surrogate jointly determine statistical efficiency. Guided by this criterion, we propose an Efficiency-Aware Surrogate-adjusted Estimator (EASE) that directly chooses the sampling law and surrogate to minimize the first-order MSE. We demonstrate that EASE consistently outperforms state-of-the-art estimators for various probabilistic values.
翻译:概率价值(包括Shapley值和半值)提供了一种模型无关的框架,用于将黑箱模型的行为归因于数据点或特征,在可解释人工智能和数据估值等领域具有广泛应用。然而,其精确计算需要对指数级数量的联盟进行效用评估,这使得蒙特卡洛近似成为现代机器学习应用中的必要条件。现有估计器通常通过不同的识别策略开发,包括加权平均、自归一化加权、回归调整和加权最小二乘。我们的关键观察是,这些看似不同的构造共享一个共同的一阶误差结构,其中主导项是由采样律和工作替代函数确定的增广逆概率加权影响项。这一阶表示给出了主导均方误差(MSE)的显式表达式,刻画了采样律和替代函数如何共同决定统计有效性。在此准则指导下,我们提出了一种有效性感知的替代调整估计器(EASE),直接选择采样律和替代函数以最小化一阶均方误差。我们证明,EASE在各种概率价值的估计中始终优于最先进的估计器。