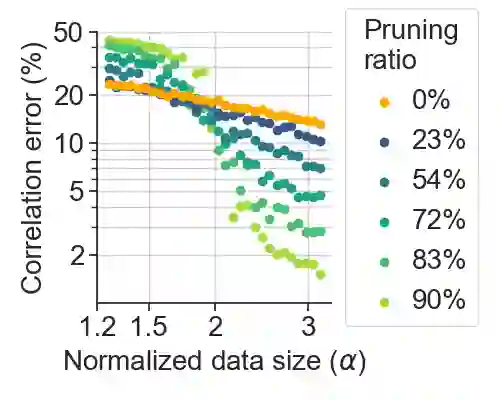
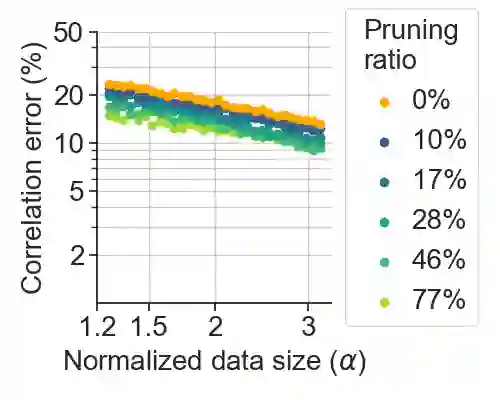
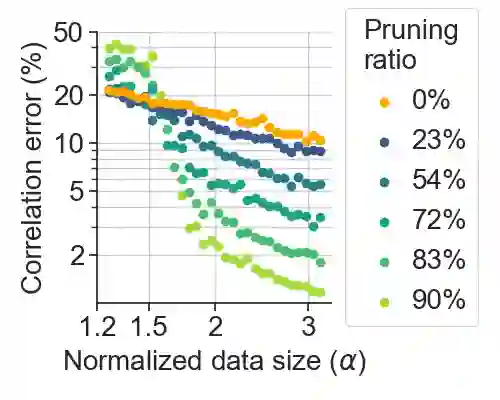
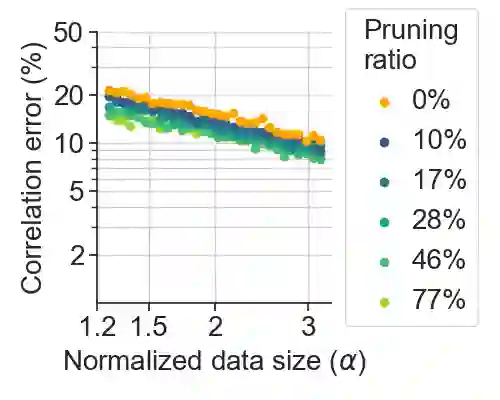
Deep learning has been able to outperform humans in terms of classification accuracy in many tasks. However, to achieve robustness to adversarial perturbations, the best methodologies require to perform adversarial training on a much larger training set that has been typically augmented using generative models (e.g., diffusion models). Our main objective in this work, is to reduce these data requirements while achieving the same or better accuracy-robustness trade-offs. We focus on data pruning, where some training samples are removed based on the distance to the model classification boundary (i.e., margin). We find that the existing approaches that prune samples with low margin fails to increase robustness when we add a lot of synthetic data, and explain this situation with a perceptron learning task. Moreover, we find that pruning high margin samples for better accuracy increases the harmful impact of mislabeled perturbed data in adversarial training, hurting both robustness and accuracy. We thus propose PUMA, a new data pruning strategy that computes the margin using DeepFool, and prunes the training samples of highest margin without hurting performance by jointly adjusting the training attack norm on the samples of lowest margin. We show that PUMA can be used on top of the current state-of-the-art methodology in robustness, and it is able to significantly improve the model performance unlike the existing data pruning strategies. Not only PUMA achieves similar robustness with less data, but it also significantly increases the model accuracy, improving the performance trade-off.
翻译:深度学习在许多任务中已能在分类精度上超越人类。然而,为获得对对抗性扰动的鲁棒性,最佳方法需在通常使用生成模型(如扩散模型)增强的更大训练集上执行对抗训练。本研究的主要目标是降低数据需求,同时实现相同或更优的精度-鲁棒性权衡。我们聚焦于数据剪枝,即根据样本与模型分类边界之间的距离(即间隔)移除部分训练样本。我们发现,现有低间隔样本剪枝方法在添加大量合成数据时无法提升鲁棒性,并通过感知机学习任务解释了这一现象。此外,我们发现为提升精度而剪枝高间隔样本会加剧对抗训练中错误标注扰动数据的有害影响,从而损害鲁棒性与精度。为此,我们提出PUMA——一种新的数据剪枝策略:利用DeepFool计算样本间隔,剪除最高间隔的训练样本,同时联合调整最低间隔样本上的训练攻击范数以保持性能。研究表明,PUMA可应用于当前最先进的鲁棒性方法之上,且与现有数据剪枝策略不同,它能显著提升模型性能。PUMA不仅能用更少数据实现相似的鲁棒性,还能大幅提高模型精度,改善性能权衡。