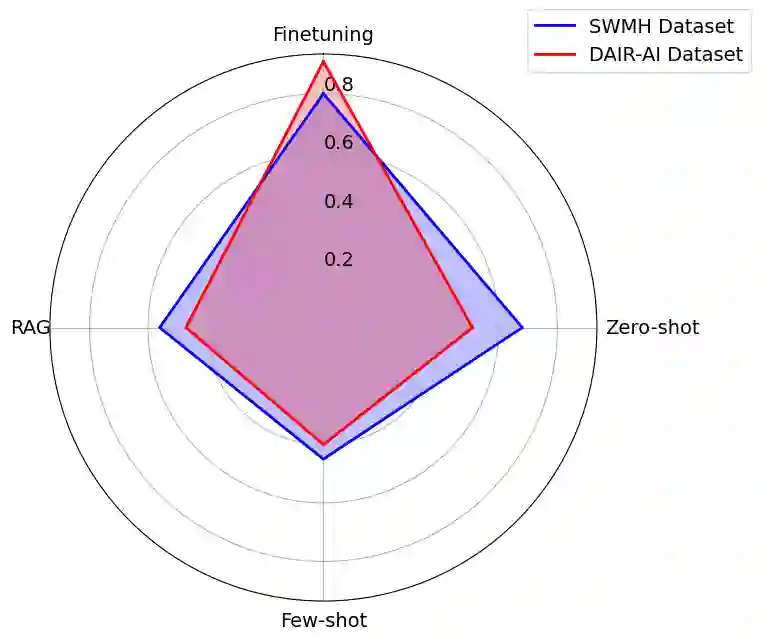
This study presents a systematic comparison of three approaches for the analysis of mental health text using large language models (LLMs): prompt engineering, retrieval augmented generation (RAG), and fine-tuning. Using LLaMA 3, we evaluate these approaches on emotion classification and mental health condition detection tasks across two datasets. Fine-tuning achieves the highest accuracy (91% for emotion classification, 80% for mental health conditions) but requires substantial computational resources and large training sets, while prompt engineering and RAG offer more flexible deployment with moderate performance (40-68% accuracy). Our findings provide practical insights for implementing LLM-based solutions in mental health applications, highlighting the trade-offs between accuracy, computational requirements, and deployment flexibility.
翻译:本研究系统比较了利用大型语言模型(LLMs)分析心理健康文本的三种方法:提示工程、检索增强生成(RAG)和微调。使用LLaMA 3模型,我们在两个数据集上评估了这些方法在情绪分类和心理健康状况检测任务上的表现。微调方法取得了最高的准确率(情绪分类91%,心理健康状况检测80%),但需要大量的计算资源和大型训练集;而提示工程和RAG则提供了更灵活的部署方式,性能适中(准确率40-68%)。我们的研究结果为在心理健康应用中实施基于LLM的解决方案提供了实用见解,强调了准确率、计算资源需求和部署灵活性之间的权衡。