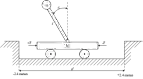
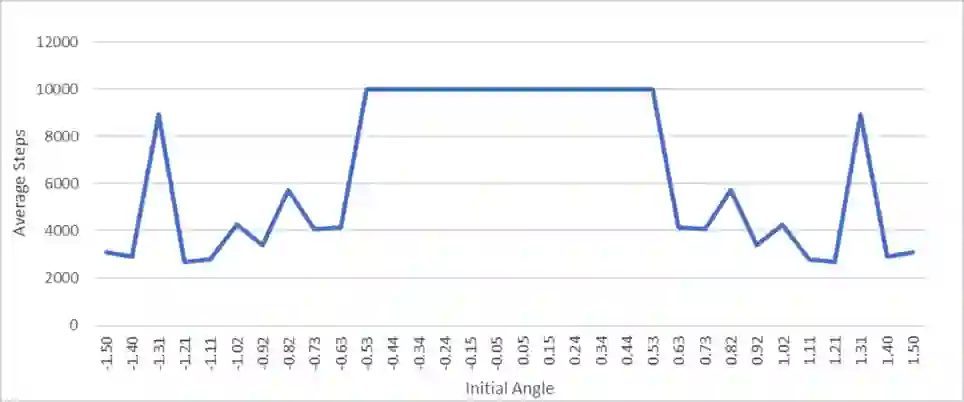
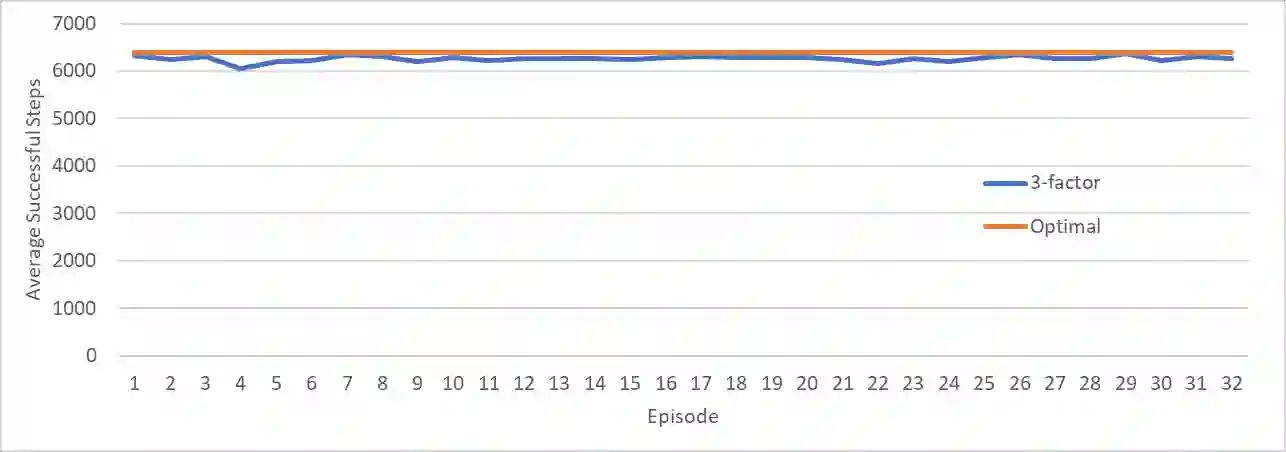
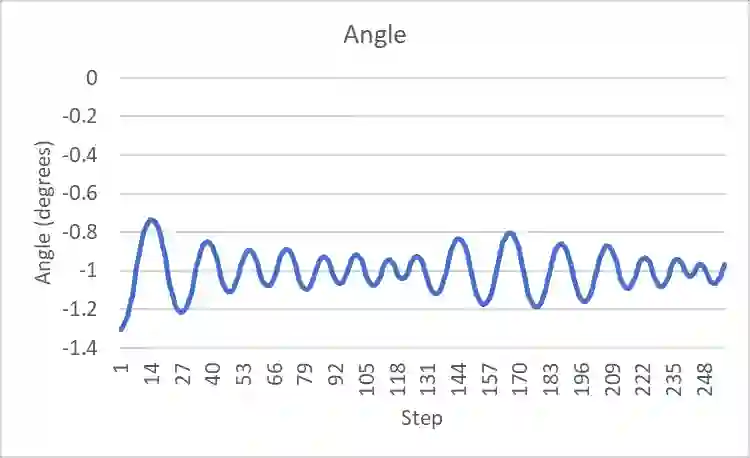
An agent employing reinforcement learning takes inputs (state variables) from an environment and performs actions that affect the environment in order to achieve some objective. Rewards (positive or negative) guide the agent toward improved future actions. This paper builds on prior clustering neural network research by constructing an agent with biologically plausible neo-Hebbian three-factor synaptic learning rules, with a reward signal as the third factor (in addition to pre- and post-synaptic spikes). The classic cart-pole problem (balancing an inverted pendulum) is used as a running example throughout the exposition. Simulation results demonstrate the efficacy of the approach, and the proposed method may eventually serve as a low-level component of a more general method.
翻译:采用强化学习的智能体从环境中获取输入(状态变量)并执行影响环境的动作,以实现特定目标。奖励信号(正或负)引导智能体改进未来动作。本文在先前聚类神经网络研究的基础上,构建了一个具有生物合理性新赫布型三因子突触学习规则的智能体,其中奖励信号作为第三因子(除突触前和突触后脉冲外)。经典的推车-杆子问题(倒立摆平衡)作为贯穿全文的运行示例。仿真结果证明了该方法的有效性,该方法最终可作为更通用方法中的低层级组件。