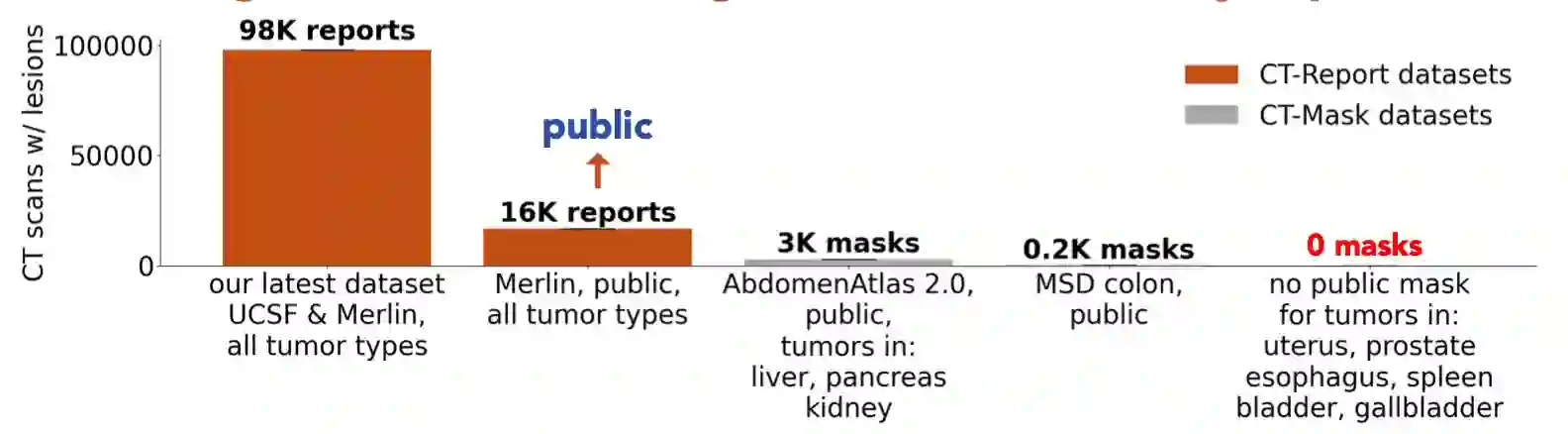
Early tumor detection save lives. Each year, more than 300 million computed tomography (CT) scans are performed worldwide, offering a vast opportunity for effective cancer screening. However, detecting small or early-stage tumors on these CT scans remains challenging, even for experts. Artificial intelligence (AI) models can assist by highlighting suspicious regions, but training such models typically requires extensive tumor masks--detailed, voxel-wise outlines of tumors manually drawn by radiologists. Drawing these masks is costly, requiring years of effort and millions of dollars. In contrast, nearly every CT scan in clinical practice is already accompanied by medical reports describing the tumor's size, number, appearance, and sometimes, pathology results--information that is rich, abundant, and often underutilized for AI training. We introduce R-Super, which trains AI to segment tumors that match their descriptions in medical reports. This approach scales AI training with large collections of readily available medical reports, substantially reducing the need for manually drawn tumor masks. When trained on 101,654 reports, AI models achieved performance comparable to those trained on 723 masks. Combining reports and masks further improved sensitivity by +13% and specificity by +8%, surpassing radiologists in detecting five of the seven tumor types. Notably, R-Super enabled segmentation of tumors in the spleen, gallbladder, prostate, bladder, uterus, and esophagus, for which no public masks or AI models previously existed. This study challenges the long-held belief that large-scale, labor-intensive tumor mask creation is indispensable, establishing a scalable and accessible path toward early detection across diverse tumor types. We plan to release our trained models, code, and dataset at https://github.com/MrGiovanni/R-Super
翻译:早期肿瘤检测能够挽救生命。全球每年进行超过3亿次计算机断层扫描(CT),这为有效的癌症筛查提供了巨大机遇。然而,在这些CT扫描中检测小型或早期肿瘤仍然具有挑战性,即使对于专家而言也是如此。人工智能模型可以通过高亮显示可疑区域来提供协助,但训练此类模型通常需要大量的肿瘤掩码——即由放射科医师手动绘制的详细、体素级肿瘤轮廓。绘制这些掩码成本高昂,需要数年努力和数百万美元。相比之下,临床实践中几乎每份CT扫描都附有描述肿瘤大小、数量、外观以及有时包含病理结果的医学报告——这些信息丰富、大量,但在人工智能训练中往往未得到充分利用。我们提出了R-Super,它训练人工智能根据医学报告中的描述分割肿瘤。这种方法利用大量现成的医学报告集合扩展人工智能训练,显著减少了对人工绘制肿瘤掩码的需求。当使用101,654份报告进行训练时,人工智能模型达到了与使用723个掩码训练相当的性能。结合报告和掩码进一步将灵敏度提高了+13%,特异性提高了+8%,在七种肿瘤类型中有五种的检测效果超过了放射科医师。值得注意的是,R-Super实现了对脾脏、胆囊、前列腺、膀胱、子宫和食道肿瘤的分割,而这些部位此前没有公开的掩码或人工智能模型。这项研究挑战了长期以来认为大规模、劳动密集型的肿瘤掩码创建不可或缺的观点,为跨多种肿瘤类型的早期检测建立了一条可扩展且易于实现的路径。我们计划在https://github.com/MrGiovanni/R-Super 发布我们训练的模型、代码和数据集。