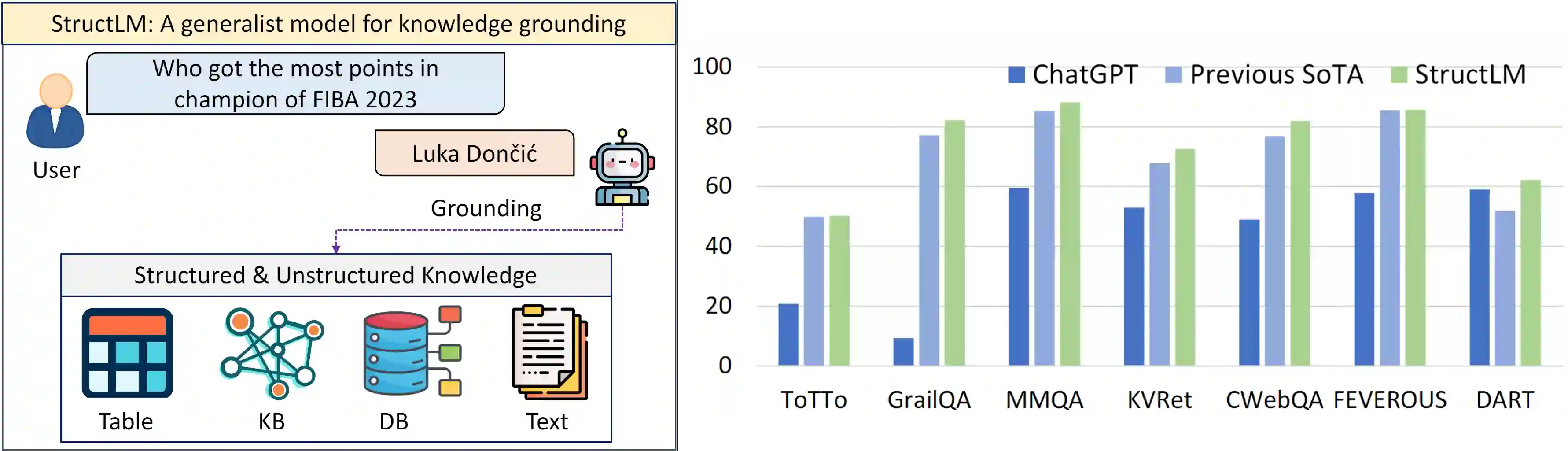
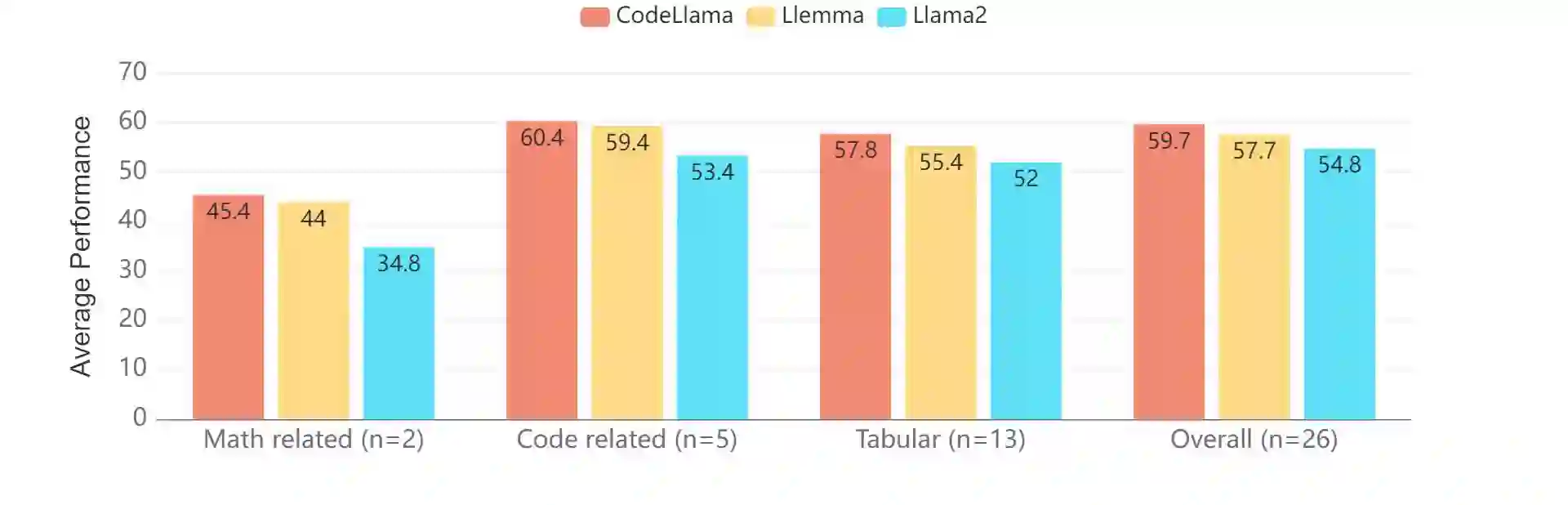
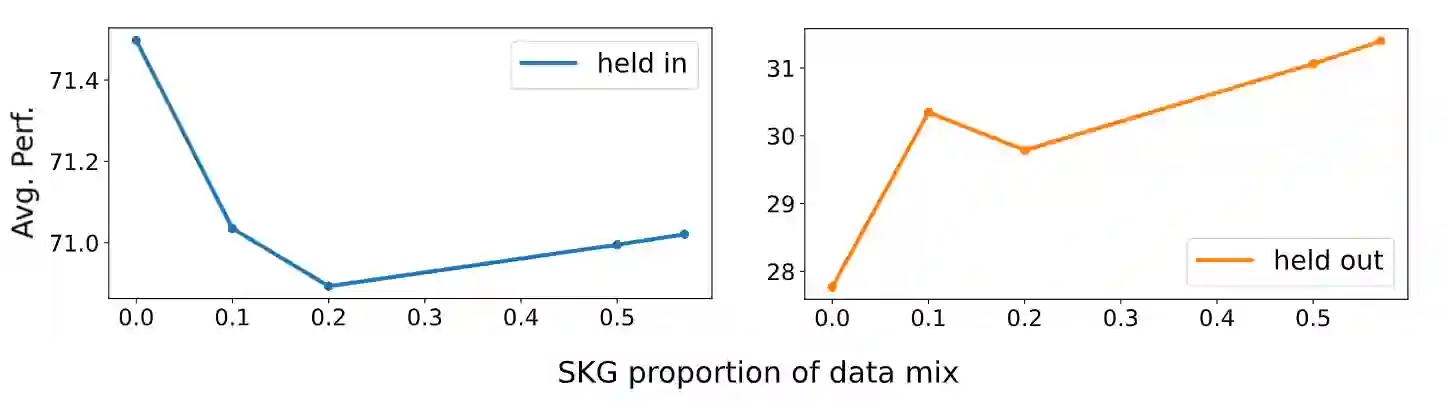
Structured data sources, such as tables, graphs, and databases, are ubiquitous knowledge sources. Despite the demonstrated capabilities of large language models (LLMs) on plain text, their proficiency in interpreting and utilizing structured data remains limited. Our investigation reveals a notable deficiency in LLMs' ability to process structured data, e.g., ChatGPT lags behind state-of-the-art (SoTA) model by an average of 35%. To augment the Structured Knowledge Grounding (SKG) capabilities in LLMs, we have developed a comprehensive instruction tuning dataset comprising 1.1 million examples. Utilizing this dataset, we train a series of models, referred to as StructLM, based on the Mistral and the CodeLlama model family, ranging from 7B to 34B parameters. Our StructLM series surpasses task-specific models on 16 out of 18 evaluated datasets and establishes new SoTA performance on 8 SKG tasks. Furthermore, StructLM demonstrates strong generalization across 6 novel held-out SKG tasks, outperforming TableLlama by an average of 35\% and Flan-UL2 20B by an average of 10\%. Contrary to expectations, we observe that scaling model size offers marginal benefits, with StructLM-34B showing only slight improvements over StructLM-7B. This suggests that structured knowledge grounding is still a challenging task and requires more innovative design to push to a new level.
翻译:结构化数据源(如表格、图表和数据库)是普遍存在的知识来源。尽管大语言模型在纯文本处理方面展现了强大能力,但其在解释和利用结构化数据方面的熟练度仍十分有限。我们的研究揭示了LLMs在结构化数据处理方面存在显著缺陷——例如ChatGPT的性能平均落后于当前最先进模型35%。为了增强LLMs的结构化知识融合能力,我们构建了包含110万样本的综合性指令微调数据集。基于该数据集,我们在Mistral和CodeLlama模型家族(参数规模从7B到34B)上训练了系列模型,称为StructLM。我们的StructLM系列在18个评估数据集中的16个上超越了任务专用模型,并在8个SKG任务上创造了新的最先进性能。此外,StructLM在6个全新保留的SKG任务上展现出强大的泛化能力,平均性能比TableLlama高出35%,比Flan-UL2 20B高出10%。与预期相反,我们发现增大模型规模带来的收益有限——StructLM-34B相比StructLM-7B仅有微弱提升。这表明结构化知识融合仍是一项具有挑战性的任务,需要更创新的设计来将其推向新高度。