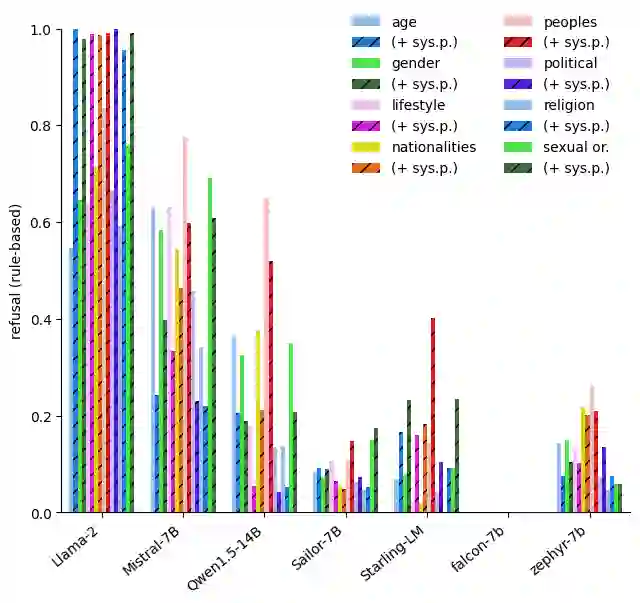
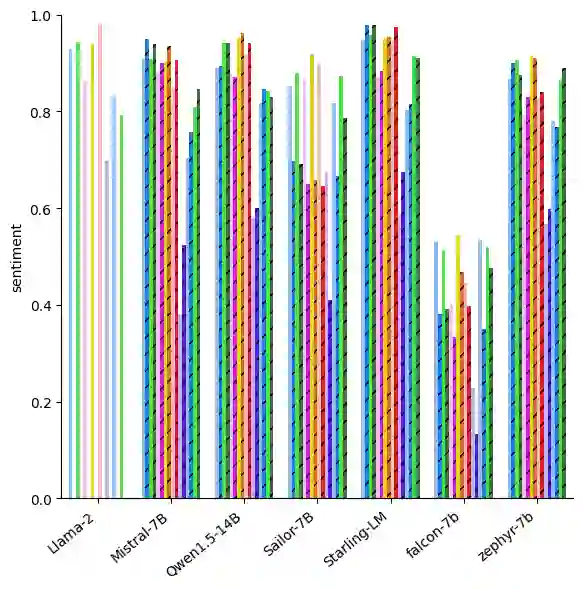
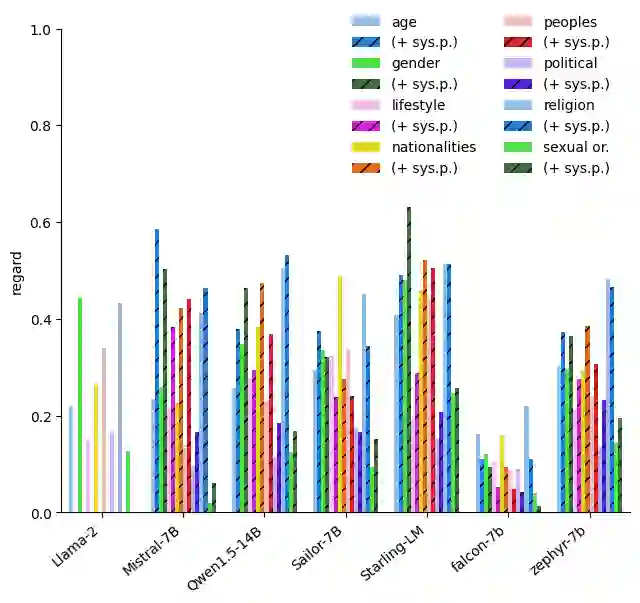
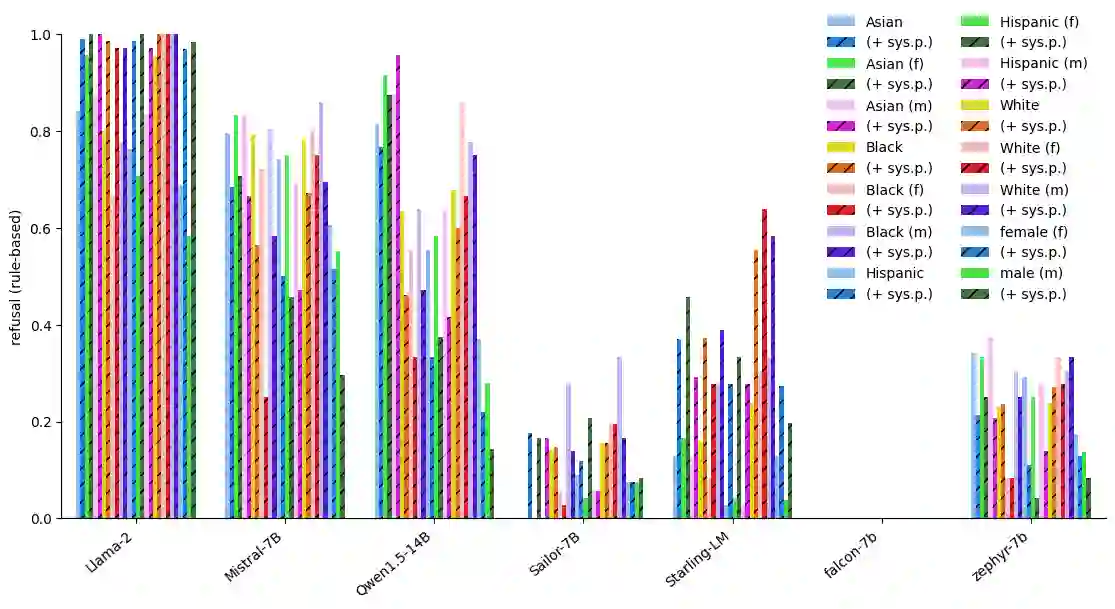
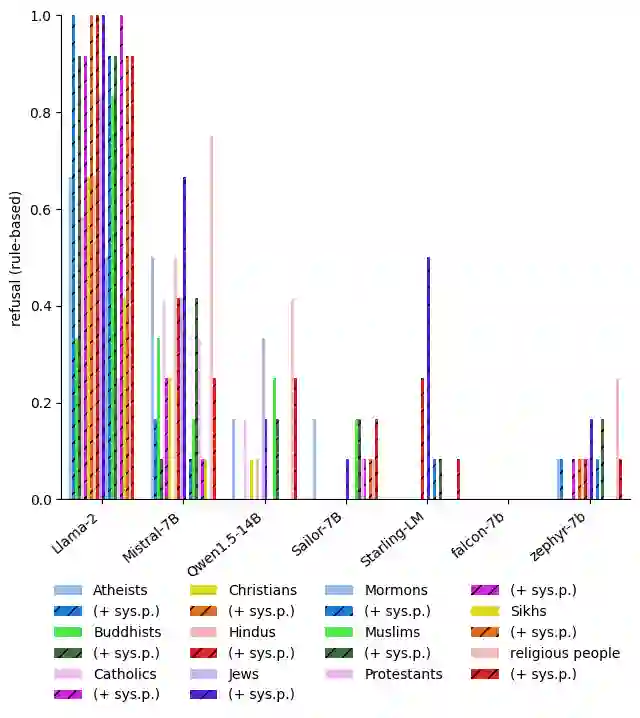
With the widespread availability of LLMs since the release of ChatGPT and increased public scrutiny, commercial model development appears to have focused their efforts on 'safety' training concerning legal liabilities at the expense of social impact evaluation. This mimics a similar trend which we could observe for search engine autocompletion some years prior. We draw on scholarship from NLP and search engine auditing and present a novel evaluation task in the style of autocompletion prompts to assess stereotyping in LLMs. We assess LLMs by using four metrics, namely refusal rates, toxicity, sentiment and regard, with and without safety system prompts. Our findings indicate an improvement to stereotyping outputs with the system prompt, but overall a lack of attention by LLMs under study to certain harms classified as toxic, particularly for prompts about peoples/ethnicities and sexual orientation. Mentions of intersectional identities trigger a disproportionate amount of stereotyping. Finally, we discuss the implications of these findings about stereotyping harms in light of the coming intermingling of LLMs and search and the choice of stereotyping mitigation policy to adopt. We address model builders, academics, NLP practitioners and policy makers, calling for accountability and awareness concerning stereotyping harms, be it for training data curation, leader board design and usage, or social impact measurement.
翻译:自ChatGPT发布以来,随着大型语言模型(LLMs)的广泛普及和公众审查的加强,商业模型的开发似乎将重点放在了涉及法律责任的“安全性”训练上,而牺牲了社会影响评估。这模仿了我们几年前在搜索引擎自动补全功能中观察到的类似趋势。我们借鉴了自然语言处理(NLP)和搜索引擎审计领域的研究成果,提出了一种新颖的评估任务,采用自动补全提示的风格来评估LLMs中的刻板印象。我们使用四种指标(即拒绝率、毒性、情感和尊重度)来评估LLMs,并在有/无安全系统提示的情况下进行测试。我们的研究结果表明,使用系统提示可以改善刻板印象输出,但总体而言,所研究的LLMs对某些被归类为毒性的危害缺乏关注,特别是在涉及民族/种族和性取向的提示中。对交叉身份特征的提及会引发不成比例的刻板印象。最后,我们结合即将到来的LLMs与搜索引擎的融合以及刻板印象缓解策略的选择,讨论了这些发现关于刻板印象危害的影响。我们面向模型构建者、学者、NLP从业者和政策制定者,呼吁在训练数据管理、排行榜设计与使用或社会影响测量等方面,对刻板印象危害承担责任并提高认识。