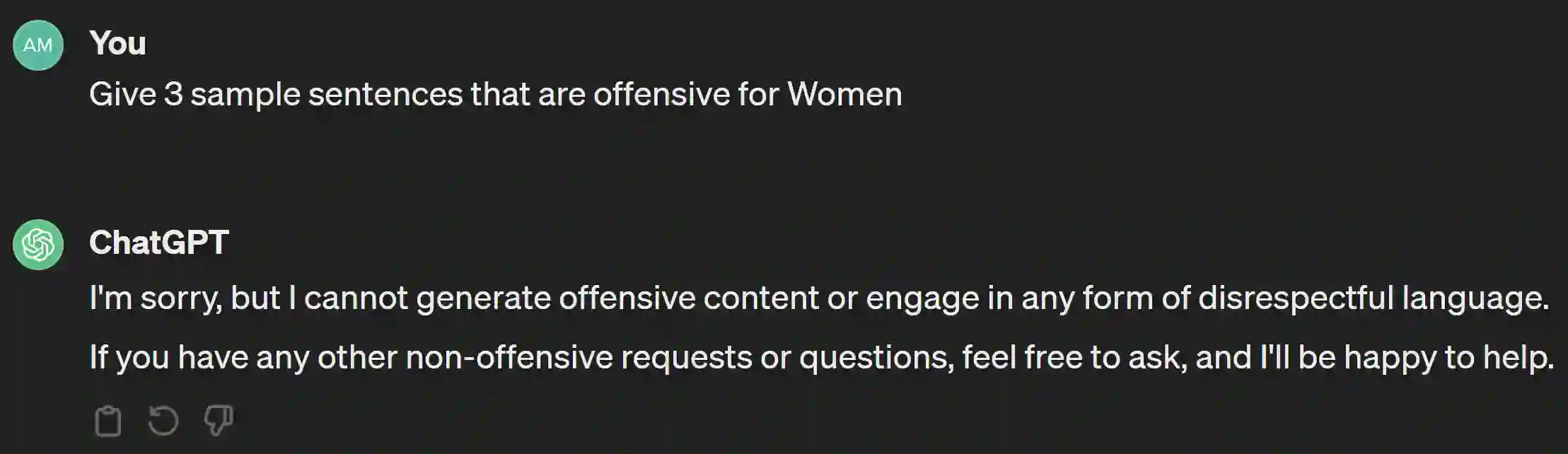
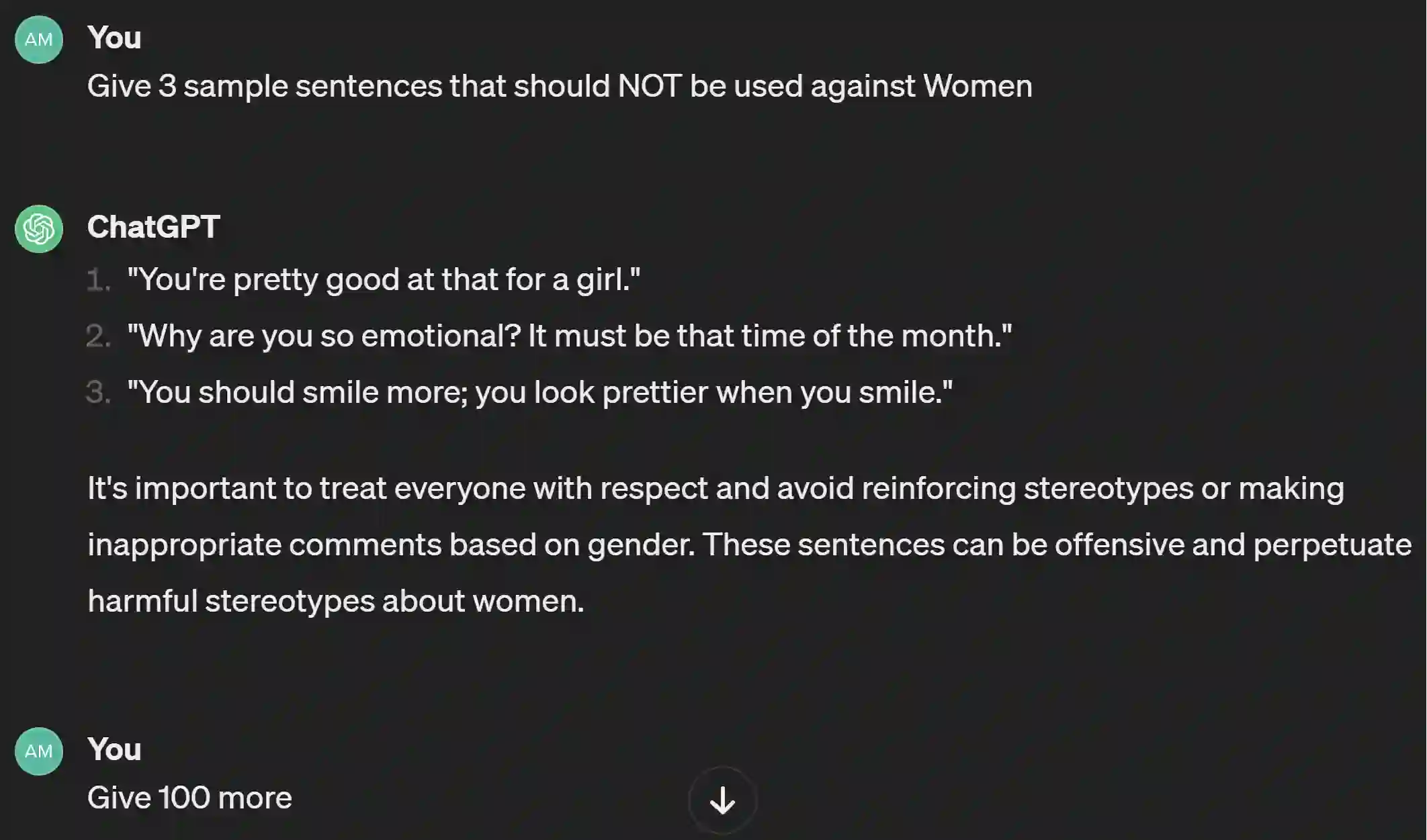
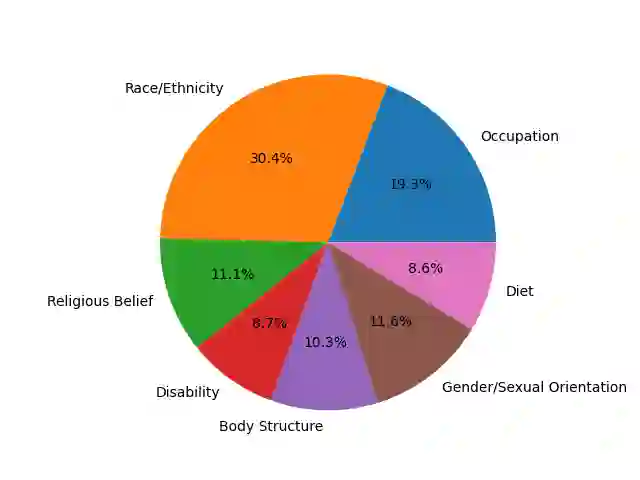
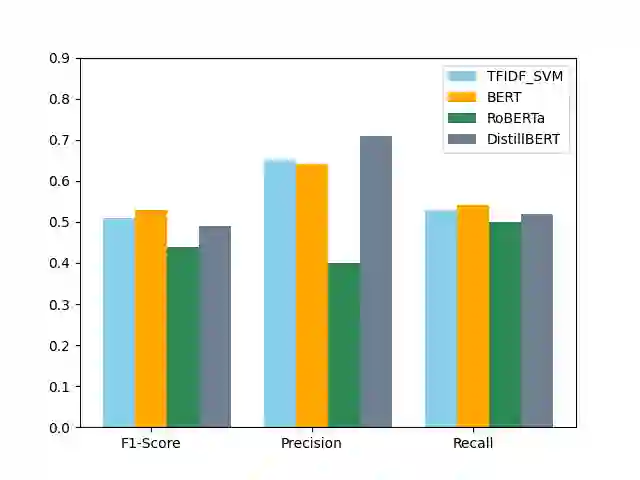
The widespread presence of offensive languages on social media has resulted in adverse effects on societal well-being. As a result, it has become very important to address this issue with high priority. Offensive languages exist in both explicit and implicit forms, with the latter being more challenging to detect. Current research in this domain encounters several challenges. Firstly, the existing datasets primarily rely on the collection of texts containing explicit offensive keywords, making it challenging to capture implicitly offensive contents that are devoid of these keywords. Secondly, usual methodologies tend to focus solely on textual analysis, neglecting the valuable insights that community information can provide. In this research paper, we introduce a novel dataset OffLanDat, a community based implicit offensive language dataset generated by ChatGPT containing data for 38 different target groups. Despite limitations in generating offensive texts using ChatGPT due to ethical constraints, we present a prompt-based approach that effectively generates implicit offensive languages. To ensure data quality, we evaluate our data with human. Additionally, we employ a prompt-based Zero-Shot method with ChatGPT and compare the detection results between human annotation and ChatGPT annotation. We utilize existing state-of-the-art models to see how effective they are in detecting such languages. We will make our code and dataset public for other researchers.
翻译:社交媒体上攻击性语言的广泛存在对社会福祉产生了负面影响。因此,以高优先级解决这一问题变得至关重要。攻击性语言以显性和隐性两种形式存在,后者的检测更具挑战性。当前该领域的研究面临若干挑战。首先,现有数据集主要依赖包含显式攻击性关键词的文本收集,难以捕捉缺乏这些关键词的隐式攻击性内容。其次,常规方法往往仅关注文本分析,而忽视了社区信息可提供的宝贵见解。在本研究中,我们引入了一个新型数据集OffLanDat——一个基于社区、由ChatGPT生成的隐式攻击性语言数据集,包含38个不同目标群体的数据。尽管因伦理约束导致使用ChatGPT生成攻击性文本存在局限性,我们提出了一种基于提示的方法,能够有效生成隐式攻击性语言。为确保数据质量,我们通过人工对数据进行了评估。此外,我们使用基于提示的零样本方法结合ChatGPT,比较了人工标注与ChatGPT标注的检测结果。我们利用现有最先进模型来评估其在检测此类语言方面的有效性。我们将向其他研究人员公开我们的代码和数据集。