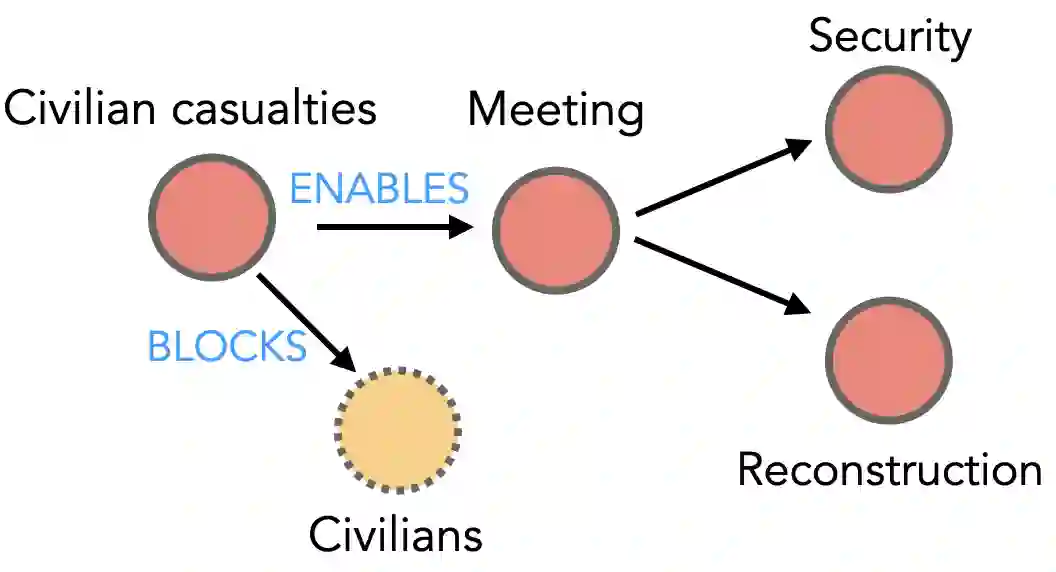
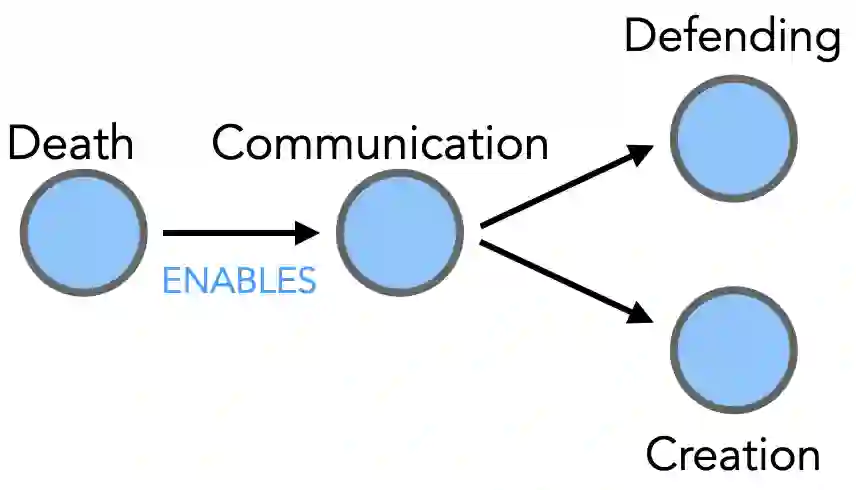
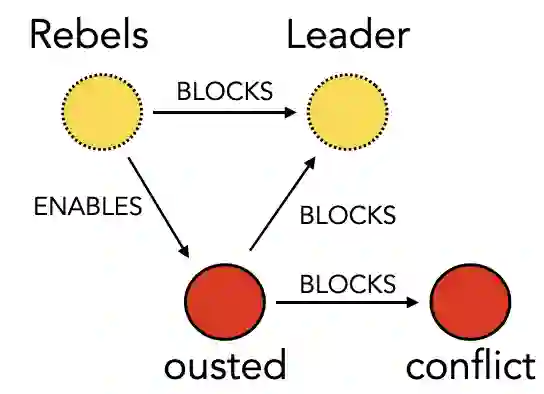
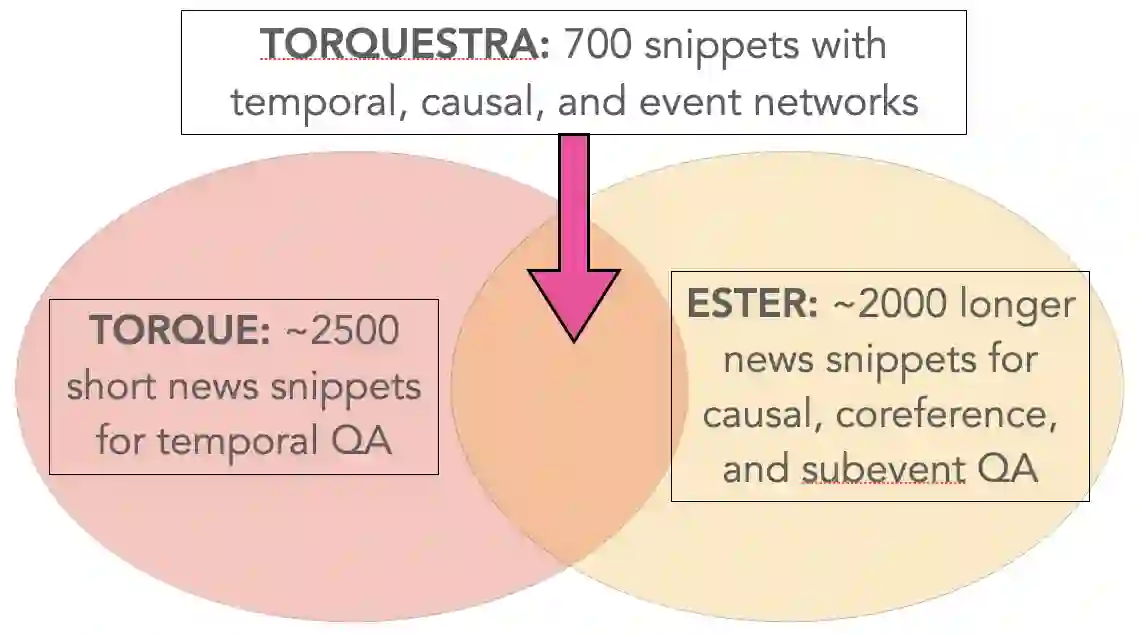
Making sense of familiar yet new situations typically involves making generalizations about causal schemas, stories that help humans reason about event sequences. Reasoning about events includes identifying cause and effect relations shared across event instances, a process we refer to as causal schema induction. Statistical schema induction systems may leverage structural knowledge encoded in discourse or the causal graphs associated with event meaning, however resources to study such causal structure are few in number and limited in size. In this work, we investigate how to apply schema induction models to the task of knowledge discovery for enhanced search of English-language news texts. To tackle the problem of data scarcity, we present Torquestra, a manually curated dataset of text-graph-schema units integrating temporal, event, and causal structures. We benchmark our dataset on three knowledge discovery tasks, building and evaluating models for each. Results show that systems that harness causal structure are effective at identifying texts sharing similar causal meaning components rather than relying on lexical cues alone. We make our dataset and models available for research purposes.
翻译:理解熟悉却又新颖的情境通常需要对因果关系图式进行泛化,这些图式是帮助人类推理事件序列的故事。对事件的推理包括识别跨事件实例共享的因果关系,我们将这一过程称为因果关系图式归纳。统计图式归纳系统可以利用话语或与事件意义相关的因果图中编码的结构化知识,然而用于研究此类因果结构的资源数量稀少且规模有限。在本工作中,我们研究如何将图式归纳模型应用于知识发现任务,以增强对英文新闻文本的搜索能力。为解决数据稀缺问题,我们提出了Torquestra数据集,这是一个人工标注的文本-图-图式单元集合,整合了时间结构、事件结构和因果结构。我们在三项知识发现任务上对该数据集进行基准测试,为每项任务构建并评估模型。结果表明,利用因果结构的系统在识别共享相似因果意义成分的文本方面效果显著,而非仅依赖词汇线索。我们公开数据集和模型以供研究使用。