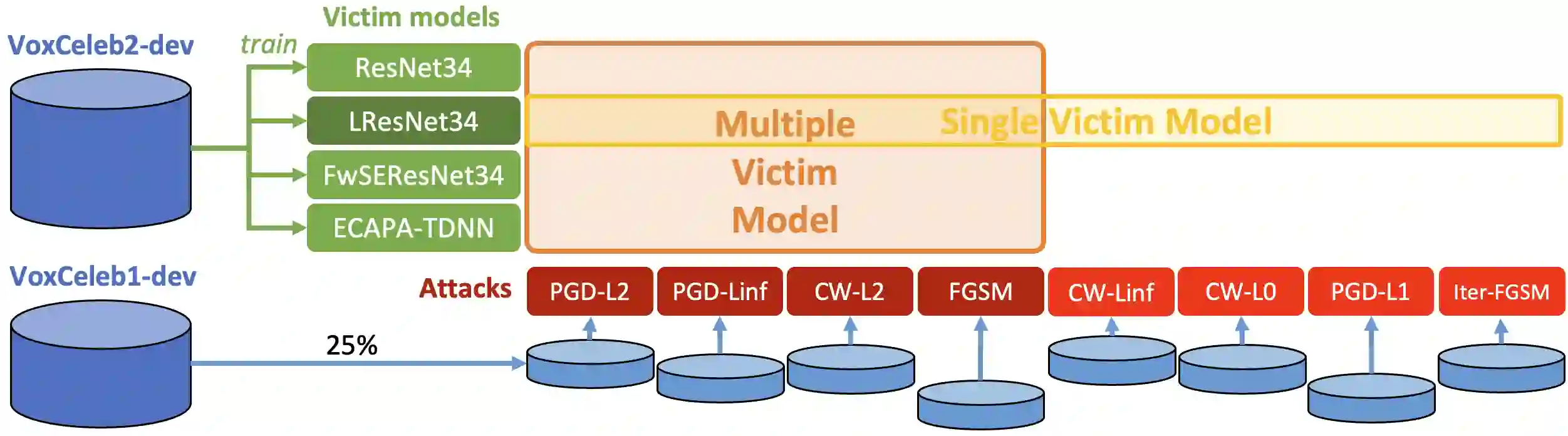
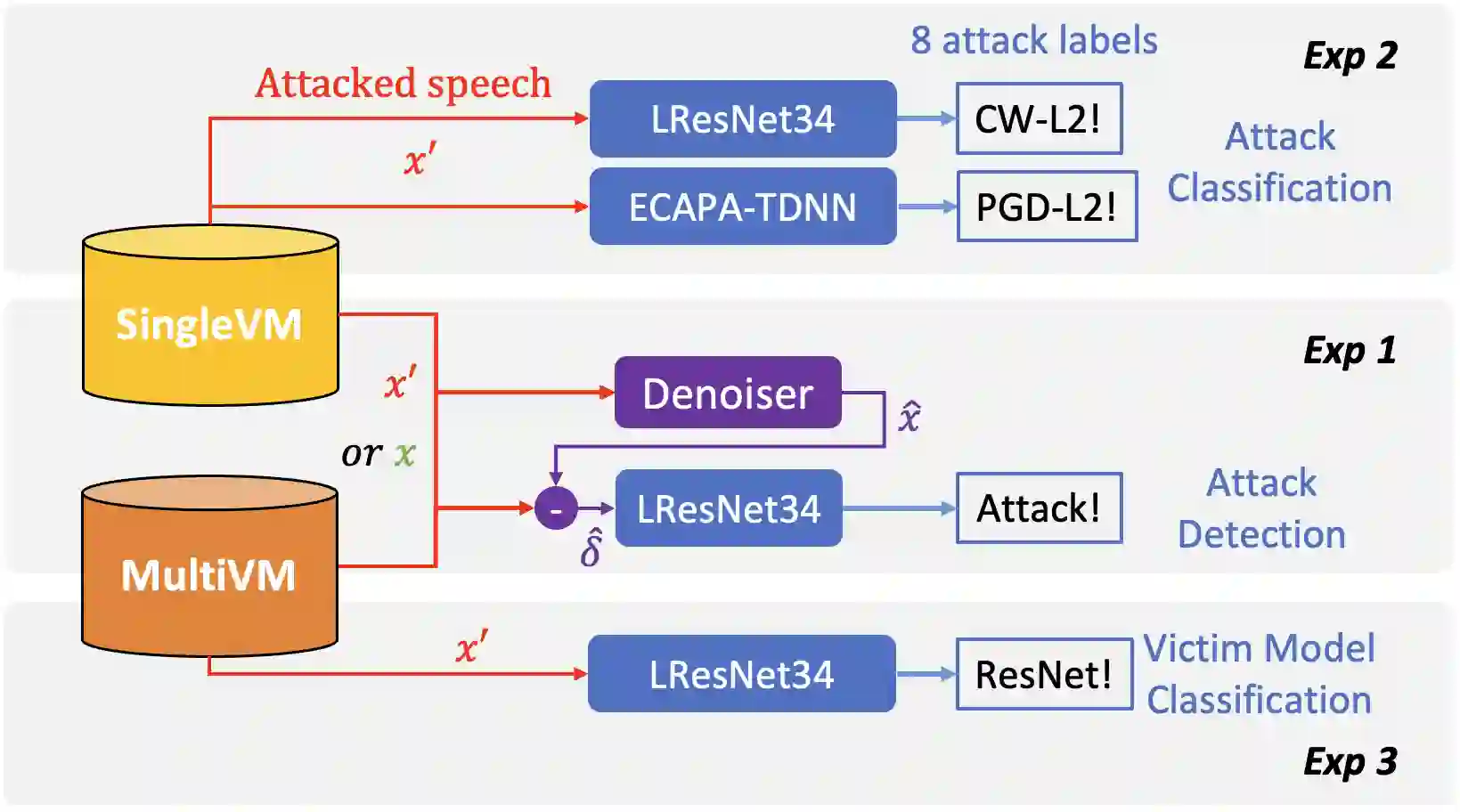
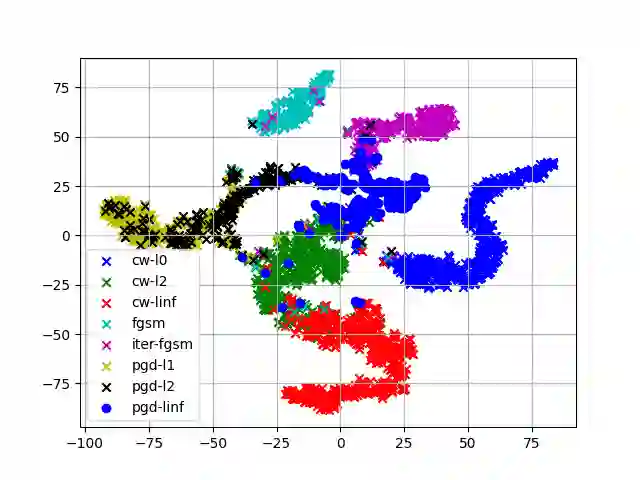
Adversarial examples have proven to threaten speaker identification systems, and several countermeasures against them have been proposed. In this paper, we propose a method to detect the presence of adversarial examples, i.e., a binary classifier distinguishing between benign and adversarial examples. We build upon and extend previous work on attack type classification by exploring new architectures. Additionally, we introduce a method for identifying the victim model on which the adversarial attack is carried out. To achieve this, we generate a new dataset containing multiple attacks performed against various victim models. We achieve an AUC of 0.982 for attack detection, with no more than a 0.03 drop in performance for unknown attacks. Our attack classification accuracy (excluding benign) reaches 86.48% across eight attack types using our LightResNet34 architecture, while our victim model classification accuracy reaches 72.28% across four victim models.
翻译:对抗样本已被证明能威胁说话人识别系统,目前已提出多种针对该威胁的防御措施。本文提出一种检测对抗样本存在性的方法,即构建区分良性样本与对抗样本的二分类器。我们通过探索新架构,在攻击类型分类的既有工作基础上进行扩展与深化。此外,我们提出一种识别对抗攻击目标受害模型的方法。为此,我们构建了一个包含针对不同受害模型实施的多类攻击的新型数据集。在攻击检测任务中,我们实现了0.982的AUC值,且对未知攻击的性能下降不超过0.03。基于所提出的LightResNet34架构,我们在八种攻击类型(不含良性样本)上的攻击分类准确率达86.48%,而在四种受害模型上的受害模型分类准确率达72.28%。