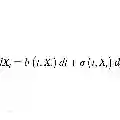In this work, we systematically benchmark two recently developed deep density methods for nonlinear filtering. We model the filtering density of a discretely observed stochastic differential equation through the associated Fokker--Planck equation, coupled with Bayesian updates at discrete observation times. The two filters: the deep splitting filter and the deep backward stochastic differential equation filter, are both based on Feynman--Kac formulas, Euler--Maruyama discretizations and neural networks. The two methods are extended to logarithmic formulations providing sound, robust, and positivity-preserving density approximations in increasing state dimension. Comparing to the classical bootstrap particle filter and an ensemble Kalman filter, we benchmark the methods on numerous examples. In the low-dimensional examples the particle filters work well, but when we scale up to a partially observed $100$-dimensional Lorenz-96 model, the particle-based methods fail and the logarithmic deep backward stochastic differential equation filter prevails. In terms of computational efficiency, the deep density methods reduce inference time by roughly two to five orders of magnitude relative to the particle-based filters.
翻译:本研究系统性地基准测试了两种近期发展的用于非线性滤波的深度密度方法。我们通过关联的福克-普朗克方程,结合离散观测时刻的贝叶斯更新,对离散观测随机微分方程的滤波密度进行建模。这两种滤波器——深度分裂滤波器与深度倒向随机微分方程滤波器——均基于费恩曼-卡克公式、欧拉-丸山离散化及神经网络。我们将这两种方法扩展至对数形式,从而在状态维度递增时提供稳健、保正的密度逼近。相较于经典的自举粒子滤波器和集合卡尔曼滤波器,我们在大量实例中进行了方法基准测试。在低维例子中,粒子滤波器表现良好;但当扩展至部分观测的100维洛伦兹-96模型时,基于粒子的方法失效,而对数深度倒向随机微分方程滤波器则胜出。在计算效率方面,深度密度方法相较于基于粒子的滤波器,将推理时间减少了约二至五个数量级。