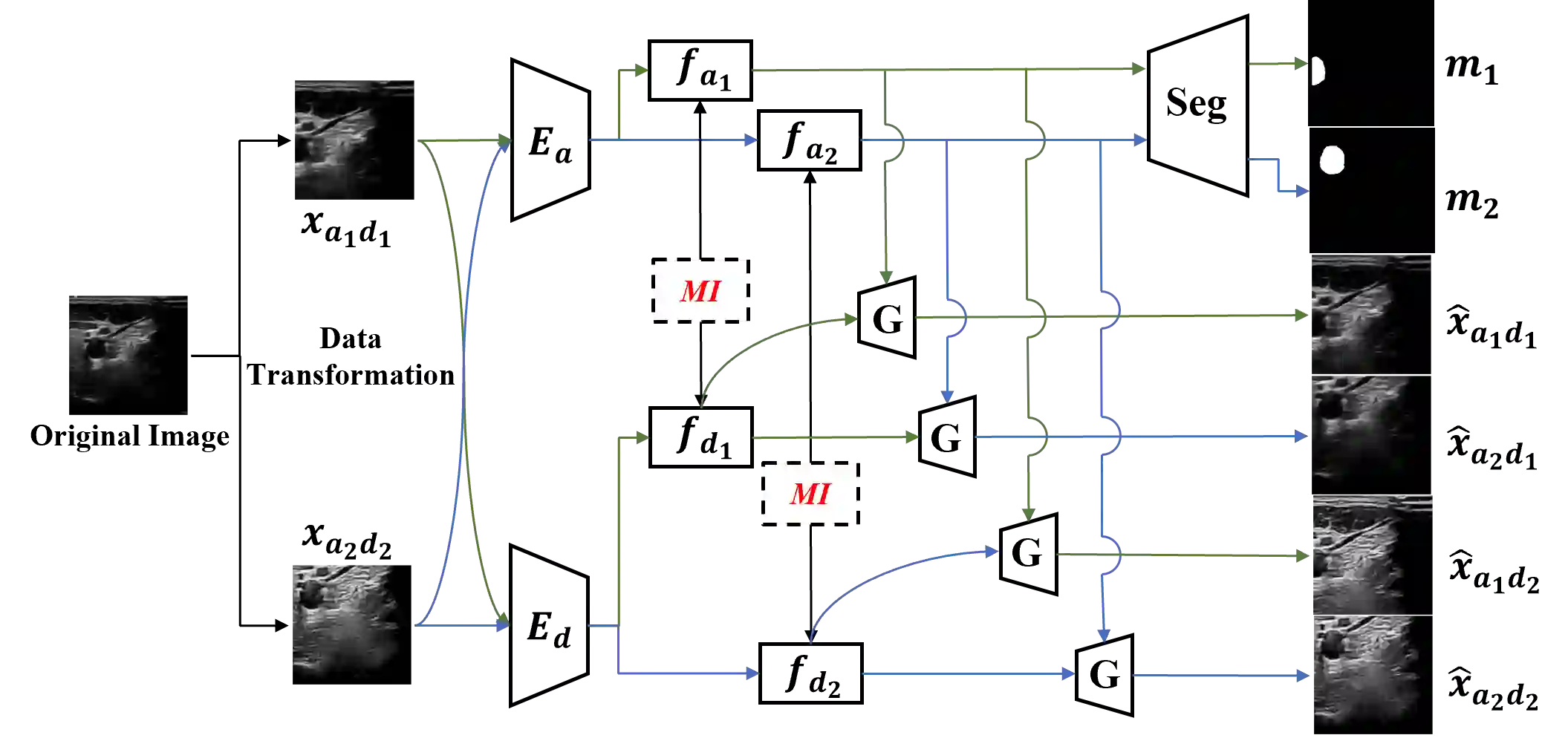
Generalization capabilities of learning-based medical image segmentation across domains are currently limited by the performance degradation caused by the domain shift, particularly for ultrasound (US) imaging. The quality of US images heavily relies on carefully tuned acoustic parameters, which vary across sonographers, machines, and settings. To improve the generalizability on US images across domains, we propose MI-SegNet, a novel mutual information (MI) based framework to explicitly disentangle the anatomical and domain feature representations; therefore, robust domain-independent segmentation can be expected. Two encoders are employed to extract the relevant features for the disentanglement. The segmentation only uses the anatomical feature map for its prediction. In order to force the encoders to learn meaningful feature representations a cross-reconstruction method is used during training. Transformations, specific to either domain or anatomy are applied to guide the encoders in their respective feature extraction task. Additionally, any MI present in both feature maps is punished to further promote separate feature spaces. We validate the generalizability of the proposed domain-independent segmentation approach on several datasets with varying parameters and machines. Furthermore, we demonstrate the effectiveness of the proposed MI-SegNet serving as a pre-trained model by comparing it with state-of-the-art networks.
翻译:基于学习的医学图像分割在跨领域时因领域偏移导致的性能下降,其泛化能力受到限制,尤其在超声成像中尤甚。超声图像质量高度依赖于精心调整的声学参数,而这些参数会因操作者、机器和设备设置的不同而变化。为提升超声图像在跨领域中的泛化性,我们提出MI-SegNet——一种基于互信息(MI)的新型框架,能够显式分离解剖特征与领域特征表示,从而有望实现鲁棒的领域无关分割。该框架采用两个编码器分别提取用于特征解耦的相关信息。分割任务仅使用解剖特征图进行预测。为强制编码器学习有意义的特征表示,训练过程中引入跨重建方法。通过施加特定于领域或解剖结构的变换,引导编码器完成各自的特征提取任务。此外,两个特征图中存在的任何互信息均被惩罚,以进一步促进特征空间分离。我们在多个包含不同参数和机器的数据集上验证了所提领域无关分割方法的泛化性,并通过与最先进网络的比较,展示了MI-SegNet作为预训练模型的有效性。