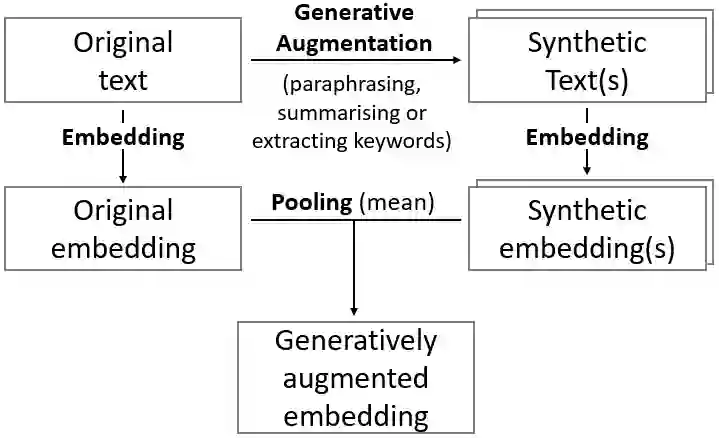
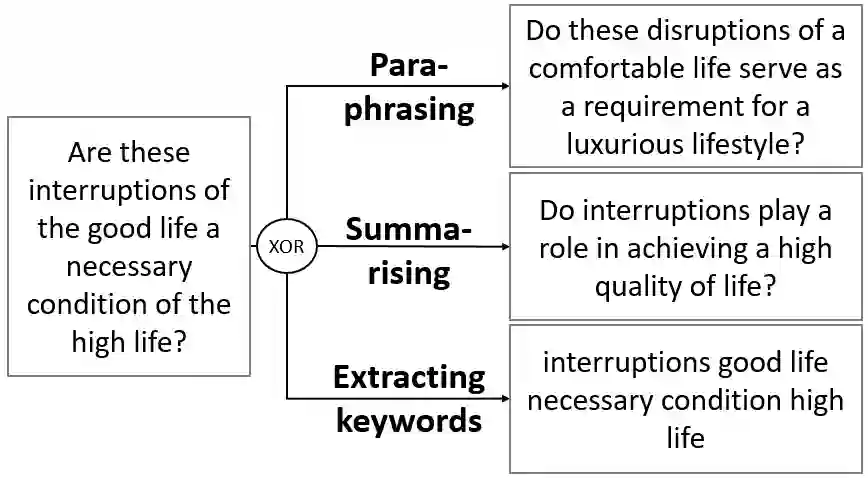
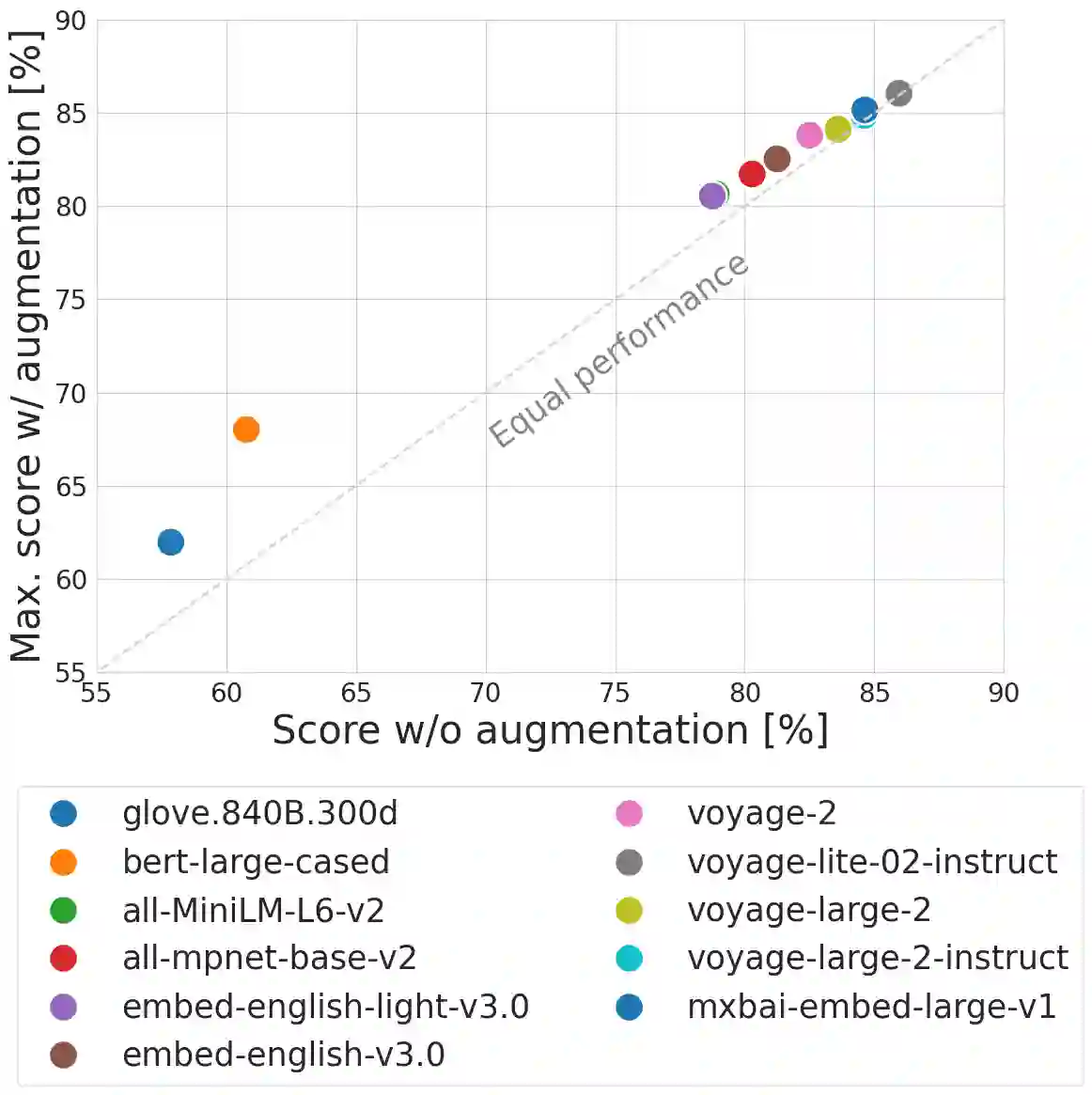
We propose an approach to enhance sentence embeddings by applying generative text models for data augmentation at inference time. Unlike conventional data augmentation that utilises synthetic training data, our approach does not require access to model parameters or the computational resources typically required for fine-tuning state-of-the-art models. Generatively Augmented Sentence Encoding uses diverse linguistic synthetic variants of input texts generated by paraphrasing, summarising, or extracting keywords, followed by pooling the original and synthetic embeddings. Experimental results on the Massive Text Embedding Benchmark for Semantic Textual Similarity (STS) demonstrate performance improvements across a range of embedding models using different generative models for augmentation. We find that generative augmentation leads to larger performance improvements for embedding models with lower baseline performance. These findings suggest that integrating generative augmentation at inference time adds semantic diversity and can enhance the robustness and generalizability of sentence embeddings for embedding models. Our results show that the degree to which generative augmentation can improve STS performance depends not only on the embedding model but also on the dataset. From a broader perspective, the approach allows trading training for inference compute.
翻译:我们提出了一种通过在推理时应用生成式文本模型进行数据增强来改进句子嵌入的方法。与使用合成训练数据的传统数据增强不同,我们的方法不需要访问模型参数或微调最先进模型通常所需的计算资源。生成增强句子编码利用通过复述、总结或关键词提取生成的输入文本的多样化语言合成变体,随后对原始嵌入与合成嵌入进行池化操作。在语义文本相似性的大规模文本嵌入基准测试上的实验结果表明,使用不同生成模型进行增强的一系列嵌入模型均实现了性能提升。我们发现,生成增强对于基线性能较低的嵌入模型能带来更大的性能改进。这些发现表明,在推理时集成生成增强增加了语义多样性,并能提升句子嵌入模型的鲁棒性和泛化能力。我们的结果显示,生成增强对语义文本相似性性能的改进程度不仅取决于嵌入模型,还取决于具体数据集。从更广泛的视角看,该方法实现了以推理计算替代训练计算的权衡。