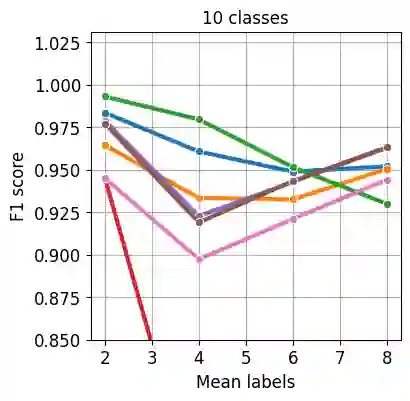
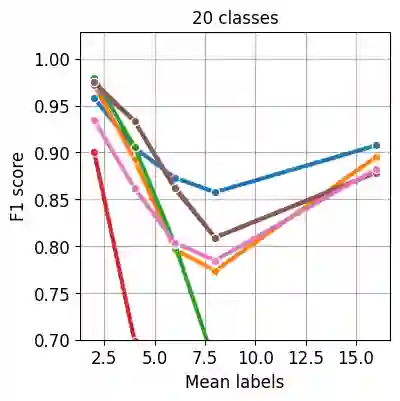
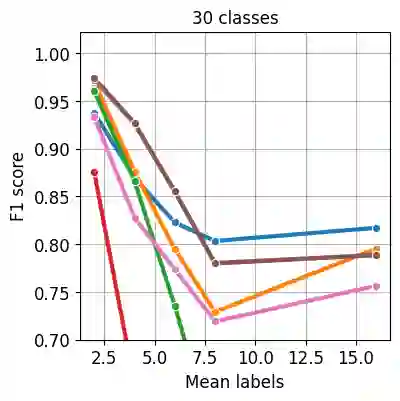
Nowadays artificial neural network models achieve remarkable results in many disciplines. Functions mapping the representation provided by the model to the probability distribution are the inseparable aspect of deep learning solutions. Although softmax is a commonly accepted probability mapping function in the machine learning community, it cannot return sparse outputs and always spreads the positive probability to all positions. In this paper, we propose r-softmax, a modification of the softmax, outputting sparse probability distribution with controllable sparsity rate. In contrast to the existing sparse probability mapping functions, we provide an intuitive mechanism for controlling the output sparsity level. We show on several multi-label datasets that r-softmax outperforms other sparse alternatives to softmax and is highly competitive with the original softmax. We also apply r-softmax to the self-attention module of a pre-trained transformer language model and demonstrate that it leads to improved performance when fine-tuning the model on different natural language processing tasks.
翻译:当前人工神经网络模型在许多学科中取得了显著成果。将模型提供的表示映射为概率分布的函数是深度学习解决方案中不可或缺的环节。尽管softmax是机器学习社区广泛认可的概率映射函数,但它无法返回稀疏输出,且总会将正概率分配给所有位置。本文提出r-softmax——对softmax的改进版本,可输出具有可控稀疏率的稀疏概率分布。与现有稀疏概率映射函数不同,我们提供了一种直观的机制来控制输出稀疏程度。在多个多标签数据集上的实验表明,r-softmax优于其他稀疏化softmax替代方案,并与原始softmax具有高度竞争力。我们还将r-softmax应用于预训练Transformer语言模型的自注意力模块,证明在针对不同自然语言处理任务微调模型时,该方法能提升性能。