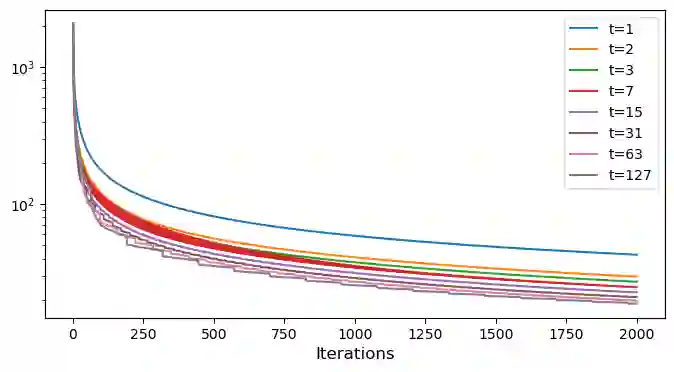
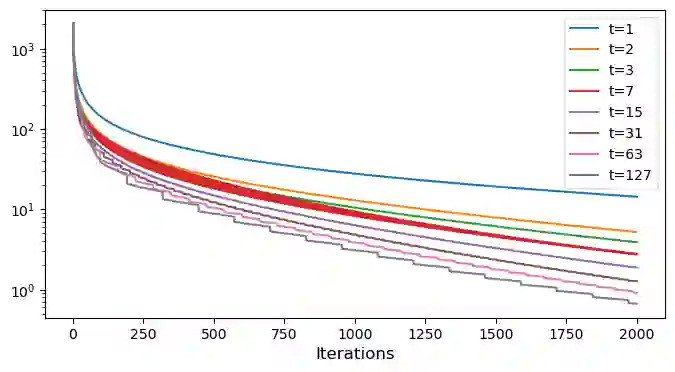
This work establishes provably faster convergence rates for gradient descent in smooth convex optimization via a computer-assisted analysis technique. Our theory allows nonconstant stepsize policies with frequent long steps potentially violating descent by analyzing the overall effect of many iterations at once rather than the typical one-iteration inductions used in most first-order method analyses. We show that long steps, which may increase the objective value in the short term, lead to provably faster convergence in the long term. A conjecture towards proving a faster $O(1/T\log T)$ rate for gradient descent is also motivated along with simple numerical validation.
翻译:本研究通过计算机辅助分析技术,为光滑凸优化中的梯度下降建立了可证明的更快的收敛速度。我们的理论允许使用非常数步长策略,其中频繁采用可能违反下降性的长步长,其分析思路是同时考虑多次迭代的整体效应,而非典型一阶方法分析中常用的逐次迭代归纳法。我们证明,虽然长步长可能在短期内增加目标函数值,但长期来看可导致理论保证的更快收敛。此外,本文还提出了关于证明梯度下降达到更优$O(1/T\log T)$速率的猜想,并辅以简单数值验证。