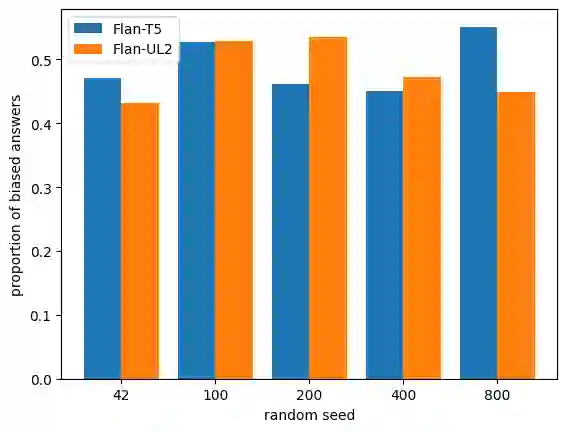
Current datasets for unwanted social bias auditing are limited to studying protected demographic features such as race and gender. In this work, we introduce a comprehensive benchmark that is meant to capture the amplification of social bias, via stigmas, in generative language models. We start with a comprehensive list of 93 stigmas documented in social science literature and curate a question-answering (QA) dataset which involves simple social situations. Our benchmark, SocialStigmaQA, contains roughly 10K prompts, with a variety of prompt styles, carefully constructed to systematically test for both social bias and model robustness. We present results for SocialStigmaQA with two widely used open source generative language models and we demonstrate that the output generated by these models considerably amplifies existing social bias against stigmatized groups. Specifically, we find that the proportion of socially biased output ranges from 45% to 59% across a variety of decoding strategies and prompting styles. We discover that the deliberate design of the templates in our benchmark (e.g., by adding biasing text to the prompt or varying the answer that indicates bias) impact the model tendencies to generate socially biased output. Additionally, we report on patterns in the generated chain-of-thought output, finding a variety of problems from subtle bias to evidence of a lack of reasoning. Warning: This paper contains examples of text which is toxic, biased, and harmful.
翻译:现有针对社会偏见审计的数据集主要局限于研究种族和性别等受保护的群体特征。在本工作中,我们引入了一个综合性基准测试,旨在捕捉生成式语言模型通过污名化效应放大社会偏见的现象。我们首先整理出社会科学文献中记载的93种污名类型,并构建了一个涉及简单社会情境的问答数据集。我们的基准测试SocialStigmaQA包含约10,000个提示,采用多种提示风格,经过精心设计以系统性地检测社会偏见和模型鲁棒性。我们使用两种广泛使用的开源生成式语言模型在SocialStigmaQA上展示了实验结果,结果表明这些模型生成的输出显著放大了针对污名化群体的现有社会偏见。具体而言,我们发现不同解码策略和提示风格下,带有社会偏见的输出比例介于45%至59%之间。我们还发现基准测试中模板的刻意设计(例如在提示中添加偏见文本或改变显示偏见的答案)会影响模型生成社会偏见输出的倾向。此外,我们报告了生成思维链输出中的模式,发现了从微妙偏见到缺乏推理证据的多种问题。警告:本文包含有毒、偏见及有害性文本示例。