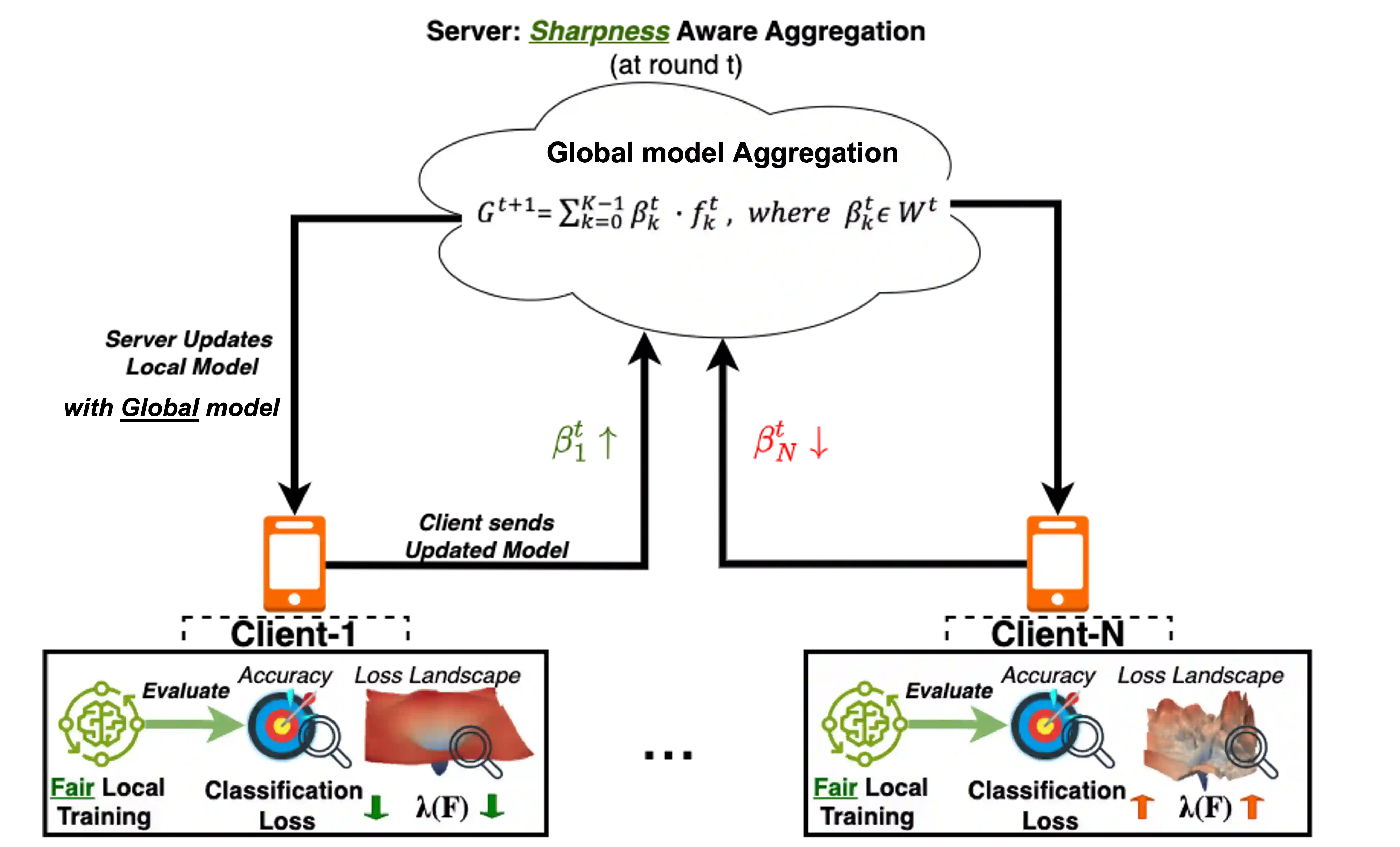
Modern human sensing applications often rely on data distributed across users and devices, where privacy concerns prevent centralized training. Federated Learning (FL) addresses this challenge by enabling collaborative model training without exposing raw data or attributes. However, achieving fairness in such settings remains difficult, as most human sensing datasets lack demographic labels, and FL's privacy guarantees limit the use of sensitive attributes. This paper introduces CurvFed: Curvature Aligned Federated Learning for Fairness without Demographics, a theoretically grounded framework that promotes fairness in FL without requiring any demographic or sensitive attribute information, a concept termed Fairness without Demographics (FWD), by optimizing the underlying loss landscape curvature. Building on the theory that equivalent loss landscape curvature corresponds to consistent model efficacy across sensitive attribute groups, CurvFed regularizes the top eigenvalue of the Fisher Information Matrix (FIM) as an efficient proxy for loss landscape curvature, both within and across clients. This alignment promotes uniform model behavior across diverse bias inducing factors, offering an attribute agnostic route to algorithmic fairness. CurvFed is especially suitable for real world human sensing FL scenarios involving single or multi user edge devices with unknown or multiple bias factors. We validated CurvFed through theoretical and empirical justifications, as well as comprehensive evaluations using three real world datasets and a deployment on a heterogeneous testbed of resource constrained devices. Additionally, we conduct sensitivity analyses on local training data volume, client sampling, communication overhead, resource costs, and runtime performance to demonstrate its feasibility for practical FL edge device deployment.
翻译:现代人类感知应用通常依赖于分布在用户和设备间的数据,隐私问题阻碍了集中式训练。联邦学习通过在不暴露原始数据或属性的情况下实现协作模型训练,应对了这一挑战。然而,在此类设置中实现公平性仍然困难,因为大多数人类感知数据集缺乏人口统计标签,且联邦学习的隐私保障限制了敏感属性的使用。本文提出CurvFed:无需人口统计信息的曲率对齐联邦学习公平性框架,这是一种基于理论的方法,通过优化底层损失函数景观的曲率,在无需任何人口统计或敏感属性信息的情况下促进联邦学习中的公平性,这一概念被称为"无需人口统计信息的公平性"。基于等价损失函数景观曲率对应敏感属性组间一致模型效能的原理,CurvFed将费舍尔信息矩阵的顶部特征值作为损失函数景观曲率的高效代理进行正则化,该正则化在客户端内部及客户端之间同时实施。这种对齐机制促进了不同偏差诱导因素间的统一模型行为,为算法公平性提供了属性无关的实现路径。CurvFed特别适用于涉及具有未知或多重偏差因素的单用户或多用户边缘设备的现实世界人类感知联邦学习场景。我们通过理论和实证论证验证了CurvFed的有效性,并使用三个真实世界数据集及在资源受限设备异构测试平台上的部署进行了全面评估。此外,我们对本地训练数据量、客户端采样、通信开销、资源成本和运行时性能进行了敏感性分析,以证明其在实用联邦学习边缘设备部署中的可行性。