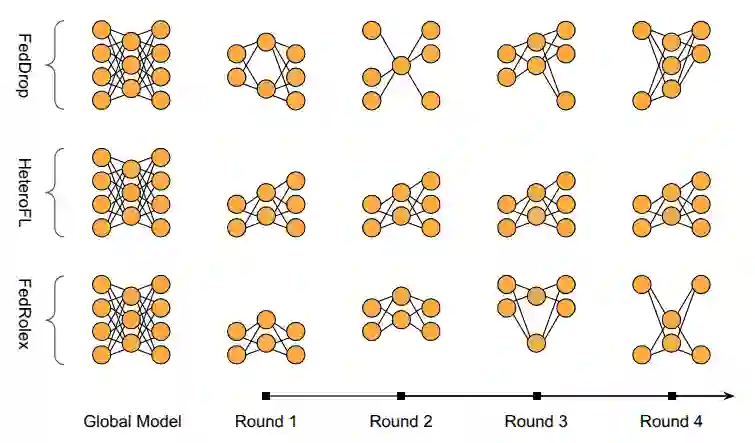
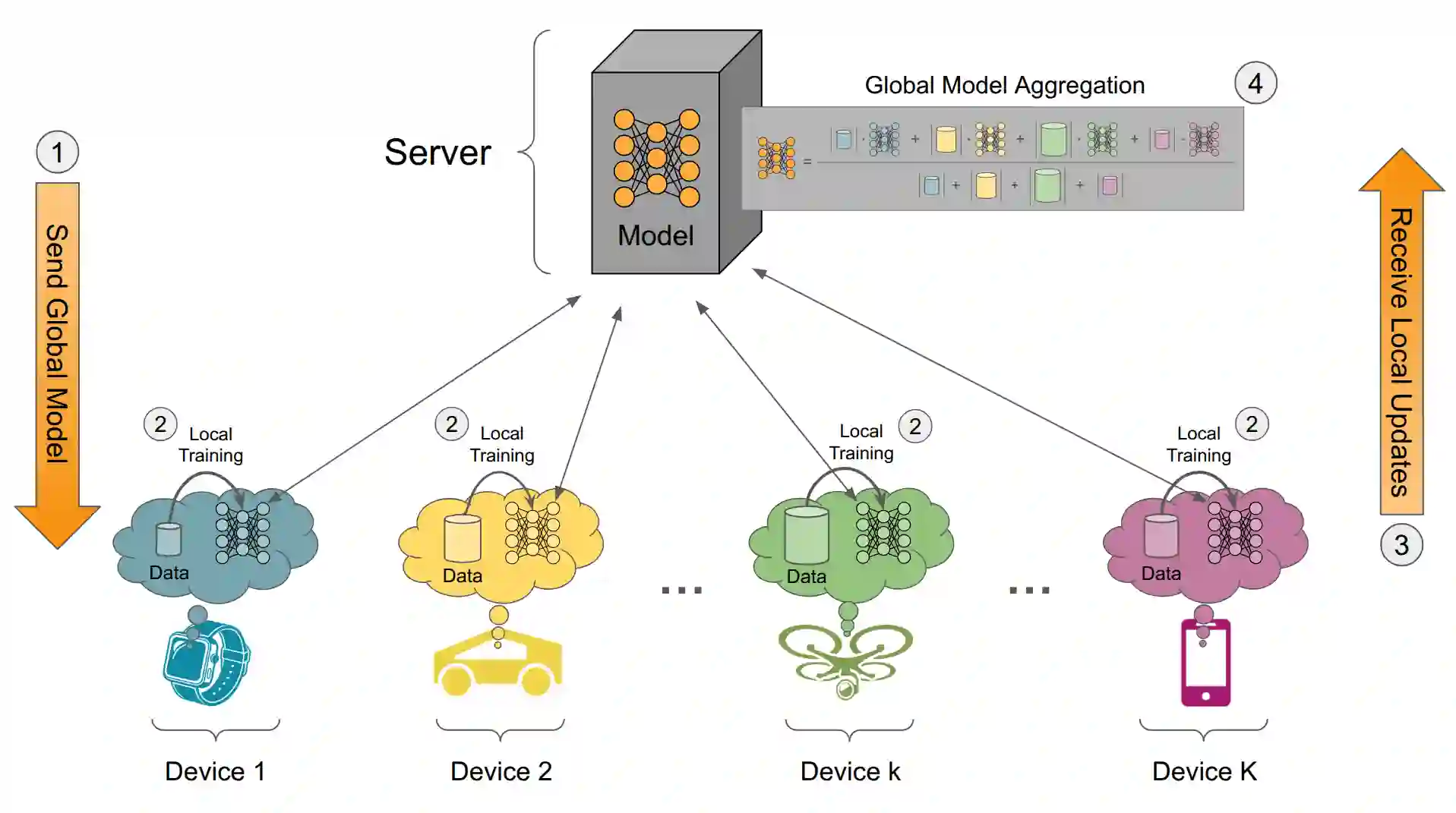
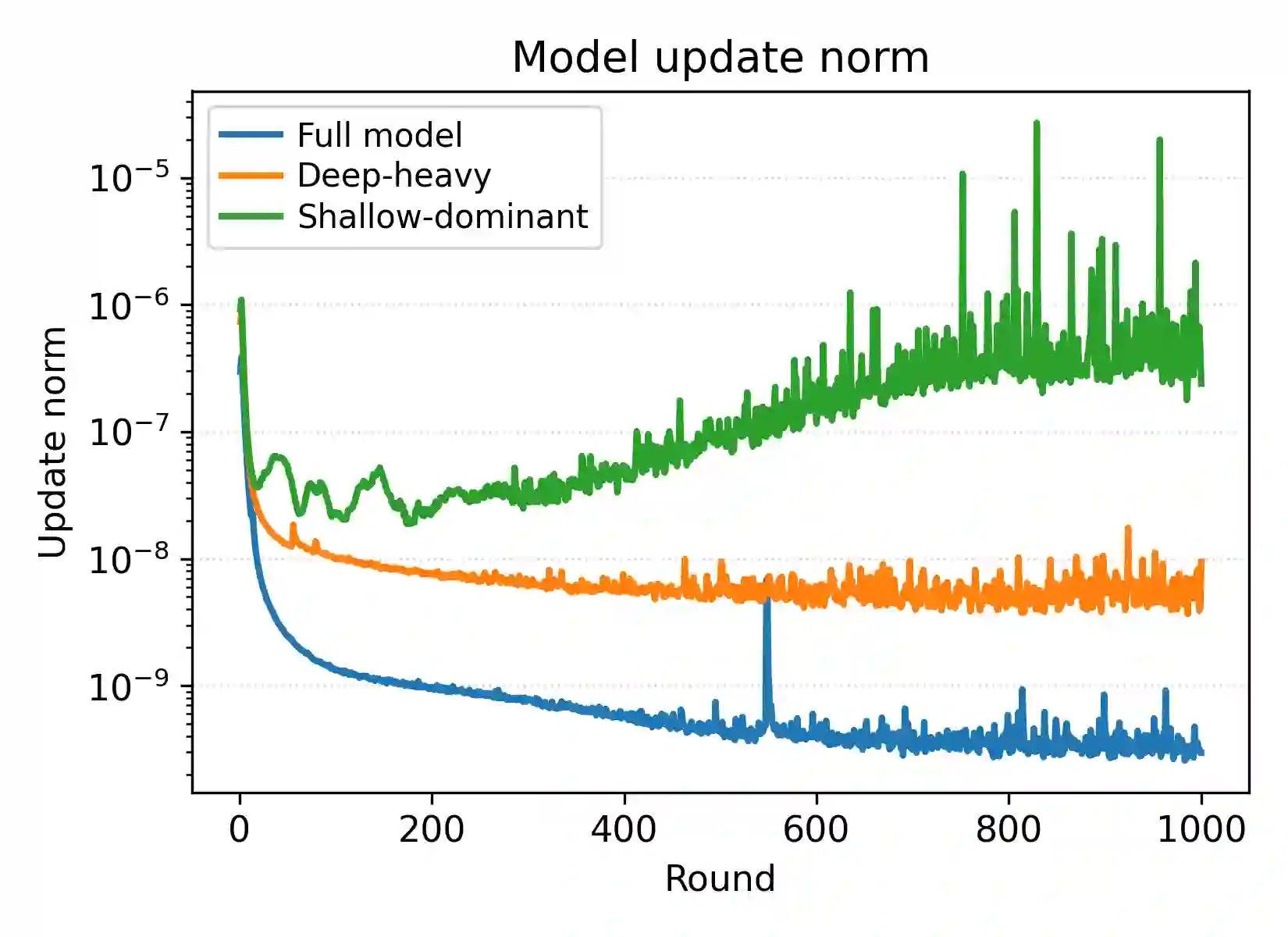
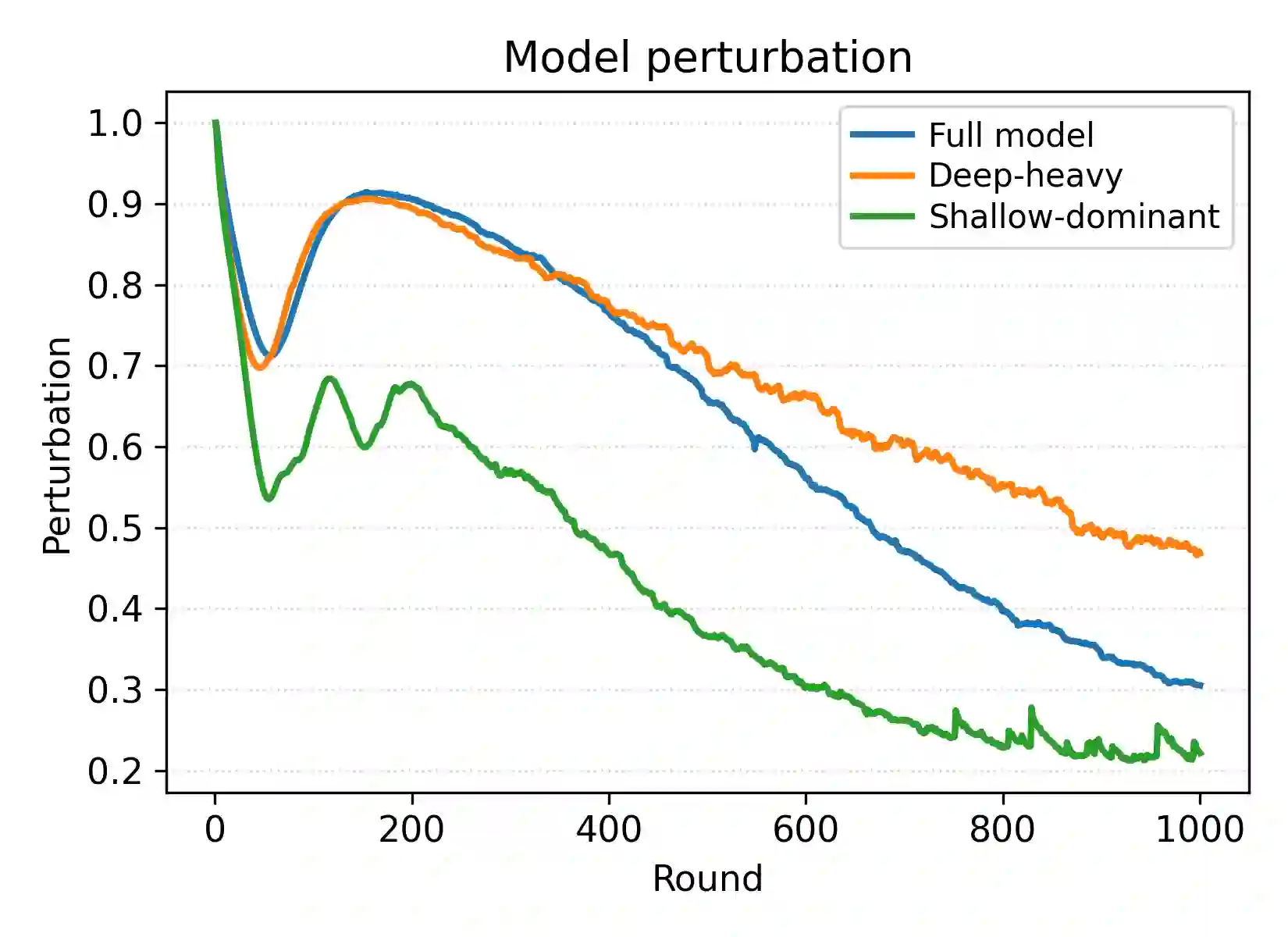
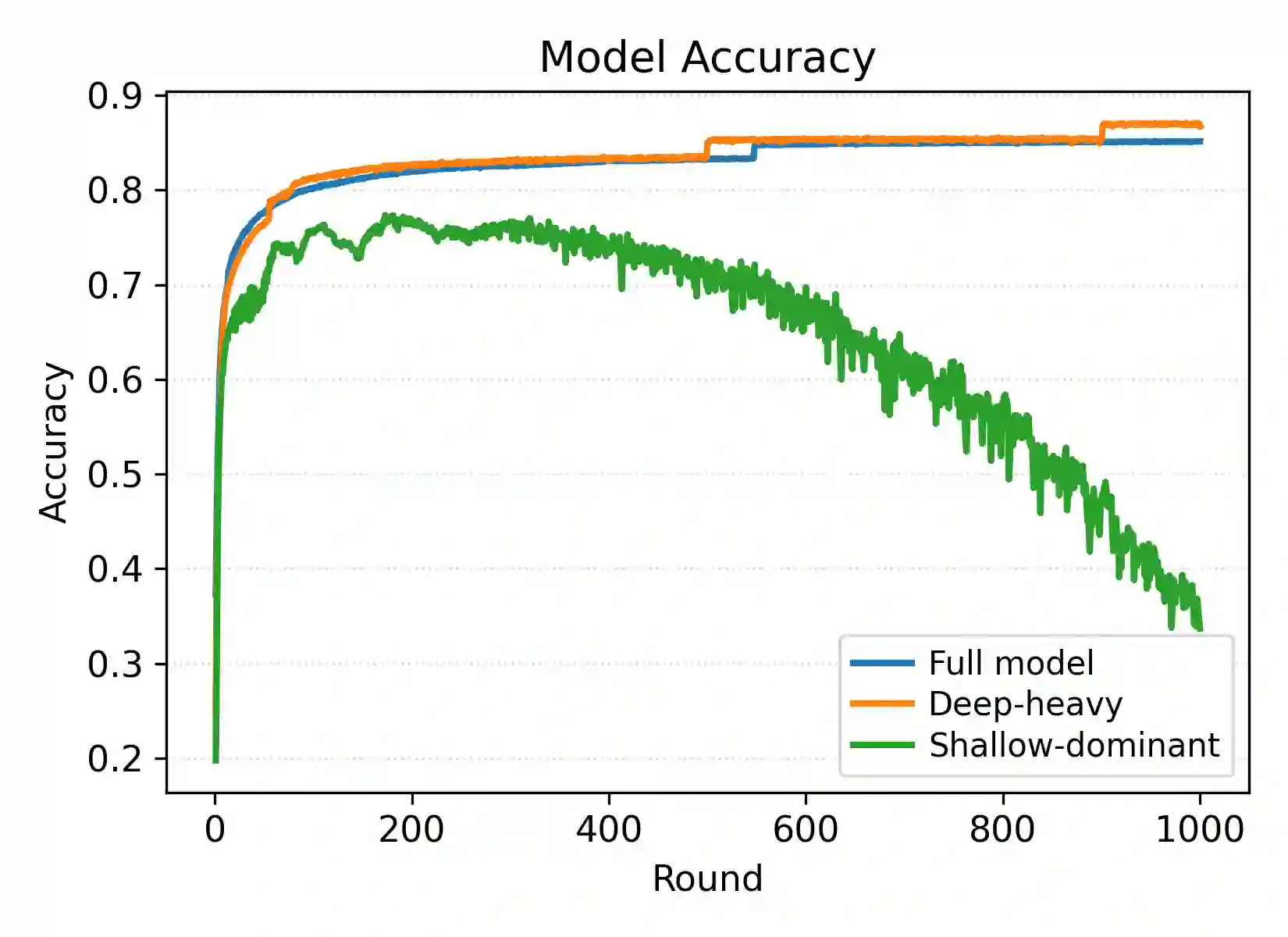
Federated Learning (FL) has gained significant attention in distributed machine learning by enabling collaborative model training across decentralized system while preserving data privacy. Although extensive research has addressed statistical data heterogeneity, FL still faces several challenges, including high communication and computation overheads and severe device heterogeneity, which require further investigation. Prior work has addressed these issues through sub-model training and partial parameter training. However, such methods often suffer from inconsistent parameter distributions across clients, inaccurate global loss estimation, and increased bias and variance. Guided by our empirical analysis, we propose FedPLT (Federated Learning with Partial Layer Training), an innovative and structured partial parameter training approach that exhibits training behavior similar to full model training while assigning client-specific portions of the model according to their communication and computational capabilities. In addition, we evaluate the performance of FedPLT when combined with optimal client sampling under communication constraints. We show that this integration improves FL performance by reducing sampling variance under the same communication budget. Through extensive experiments, we demonstrate that FedPLT achieves performance comparable to, or even surpassing, that of full-model training (i.e., FedAvg), while requiring significantly fewer trainable parameters per client. Moreover, FedPLT outperforms existing methods in highly heterogeneous environments, effectively adapts to client resource constraints, and reduces the number of straggling clients. In particular, FedPLT reduces the number of trainable parameters by 71%-82% while achieving performance on par with full-model training.
翻译:联邦学习(Federated Learning, FL)通过在去中心化系统中实现协作模型训练并保护数据隐私,在分布式机器学习领域获得了广泛关注。尽管已有大量研究解决了统计异构性这一数据分布问题,但联邦学习仍面临通信与计算开销大、设备异构性强等若干挑战,亟需进一步探索。已有工作通过子模型训练和部分参数训练尝试解决上述问题,然而这类方法常导致客户端参数分布不一致、全局损失估计不准确以及偏差与方差增大。基于实证分析的引导,我们提出FedPLT(基于部分层训练的联邦学习),一种创新且结构化的部分参数训练方法。该方法在展现出与全模型训练相似训练行为的同时,根据客户端的通信与计算能力为其分配模型特定部分。此外,我们评估了FedPLT在通信约束下与最优客户端采样策略结合时的性能。研究表明,该集成方法通过降低相同通信预算下的采样方差,有效提升了联邦学习性能。通过大量实验验证,FedPLT在显著减少每个客户端可训练参数量的前提下,达到了与全模型训练(即FedAvg)相媲美甚至更优的性能。具体而言,FedPLT在保持与全模型训练相同性能水平的情况下,将可训练参数量减少了71%-82%,并在高异构环境中优于现有方法,能有效适应客户端资源限制并减少掉队客户端数量。