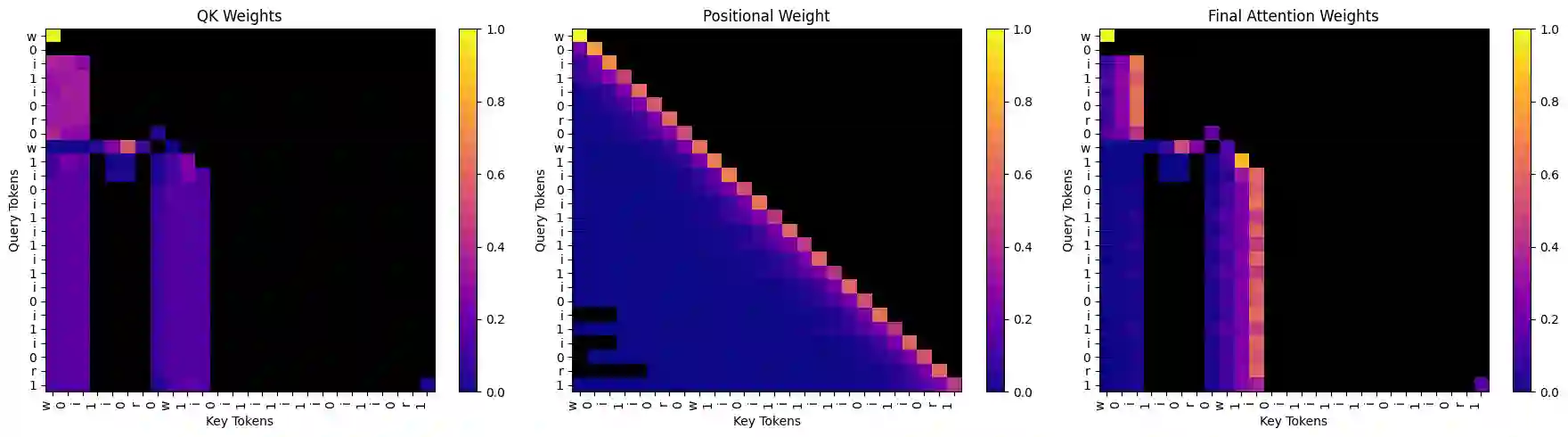
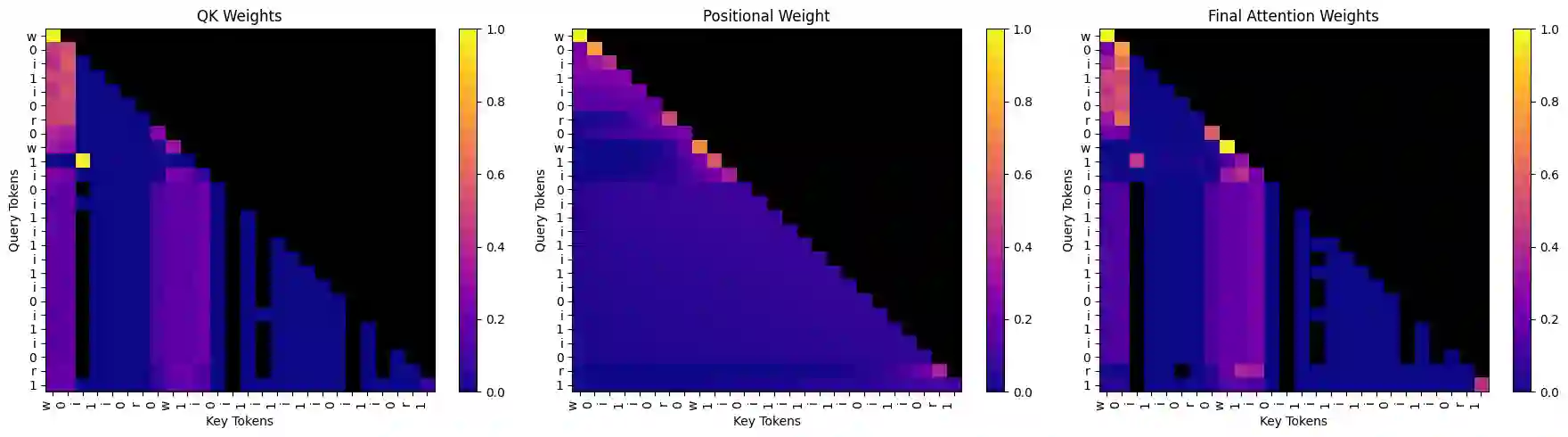
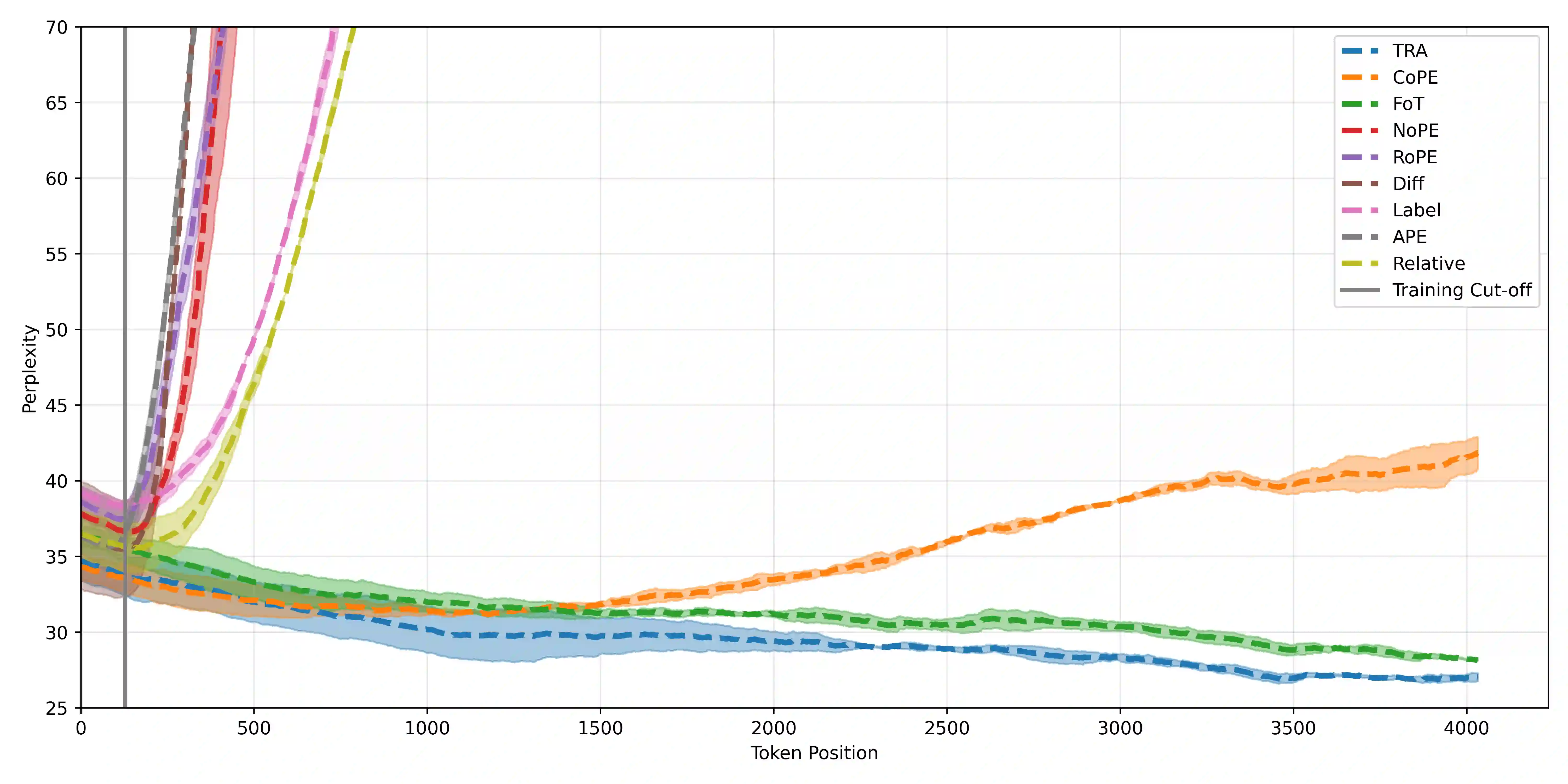
Transformers struggle with length generalisation, displaying poor performance even on basic tasks. We test whether these limitations can be explained through two key failures of the self-attention mechanism. The first is the inability to fully remove irrelevant information. The second is tied to position, even if the dot product between a key and query is highly negative (i.e. an irrelevant key) learned positional biases may unintentionally up-weight such information - dangerous when distances become out of distribution. Put together, these two failure cases lead to compounding generalisation difficulties. We test whether they can be mitigated through the combination of a) selective sparsity - completely removing irrelevant keys from the attention softmax and b) contextualised relative distance - distance is only considered as between the query and the keys that matter. We show how refactoring the attention mechanism with these two mitigations in place can substantially improve generalisation capabilities of decoder only transformers.
翻译:Transformer模型在长度泛化方面存在困难,即使在基础任务上也表现不佳。我们通过自注意力机制的两个关键缺陷来检验这些局限性的成因:首先是无法完全消除无关信息;其次是与位置相关的偏差问题——即使键与查询的点积呈现高度负值(即无关键),已学习的位置偏置仍可能无意中放大此类信息的权重,当距离超出训练分布范围时将引发严重问题。这两种失效模式共同导致了叠加的泛化困难。我们验证了通过以下两种缓解策略的组合能否改善该问题:a) 选择性稀疏化——将无关键从注意力softmax函数中完全移除;b) 上下文相关相对距离——仅考虑查询与关键键之间的距离。研究表明,通过重构包含这两种改进措施的注意力机制,能够显著提升仅解码器架构Transformer的泛化能力。