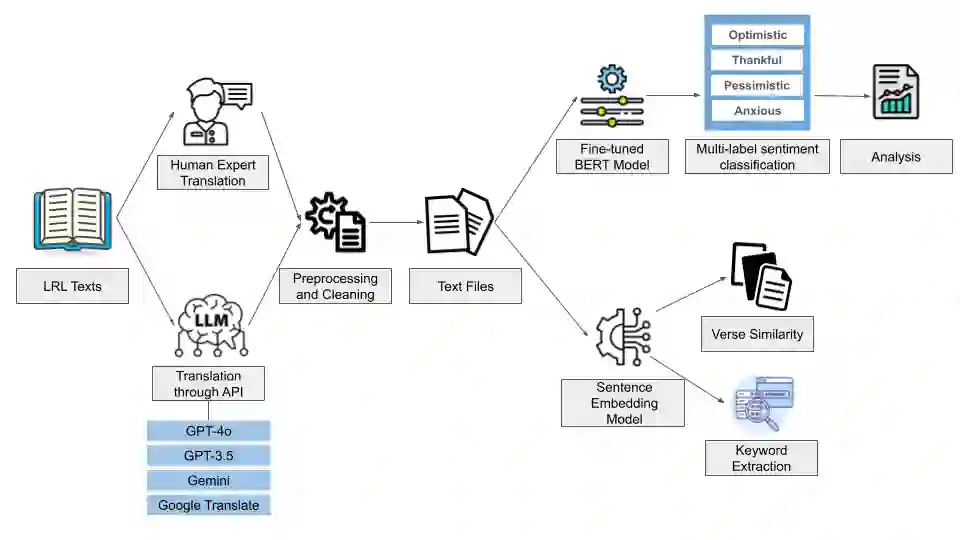
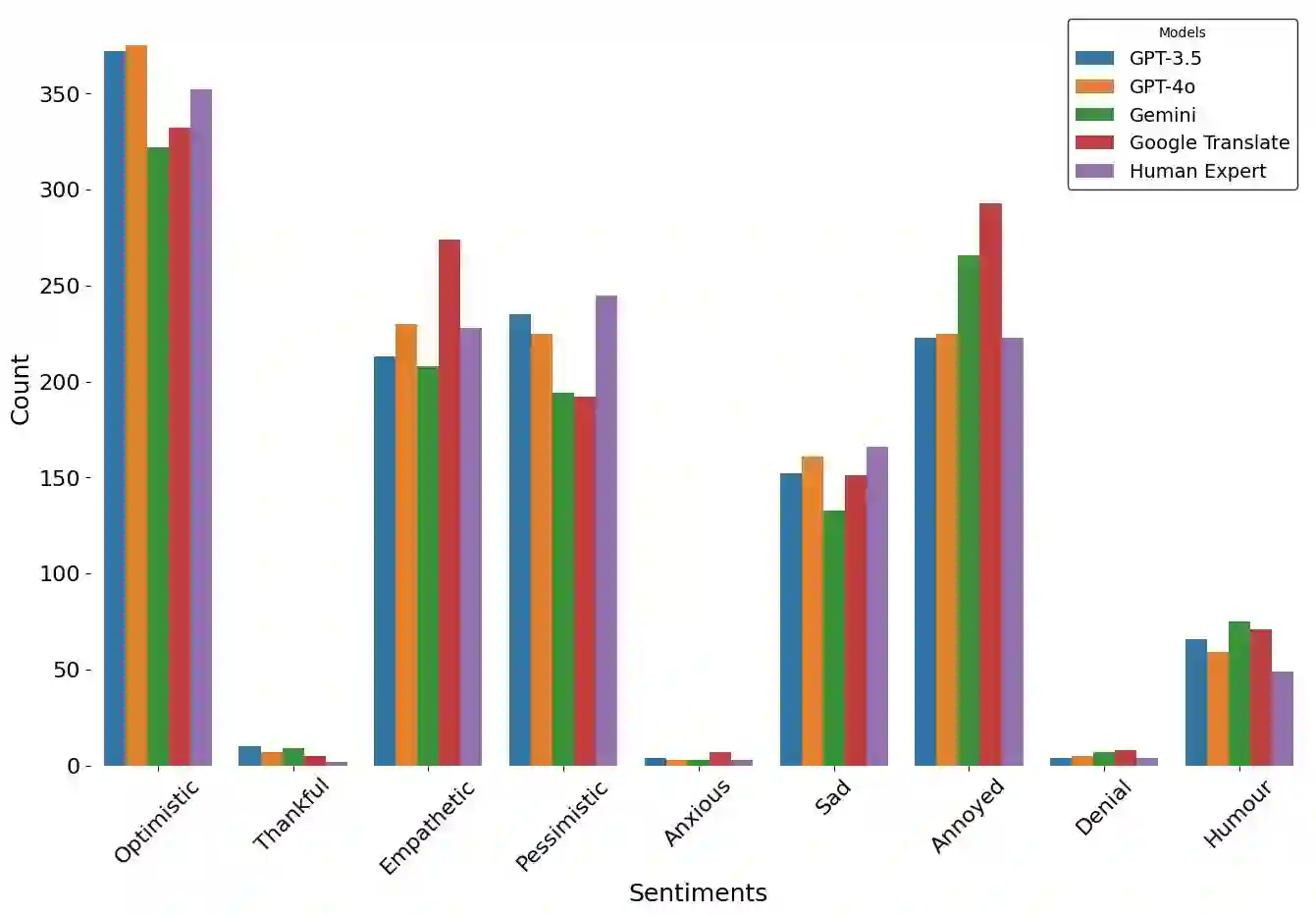
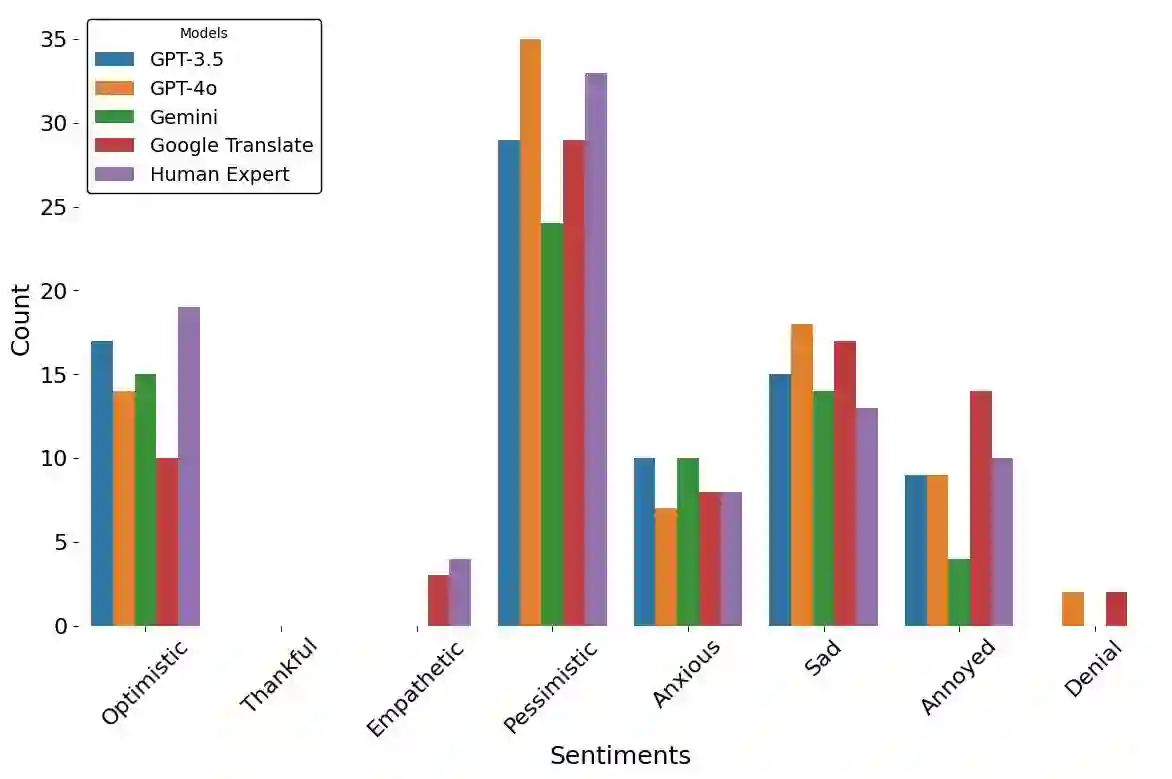
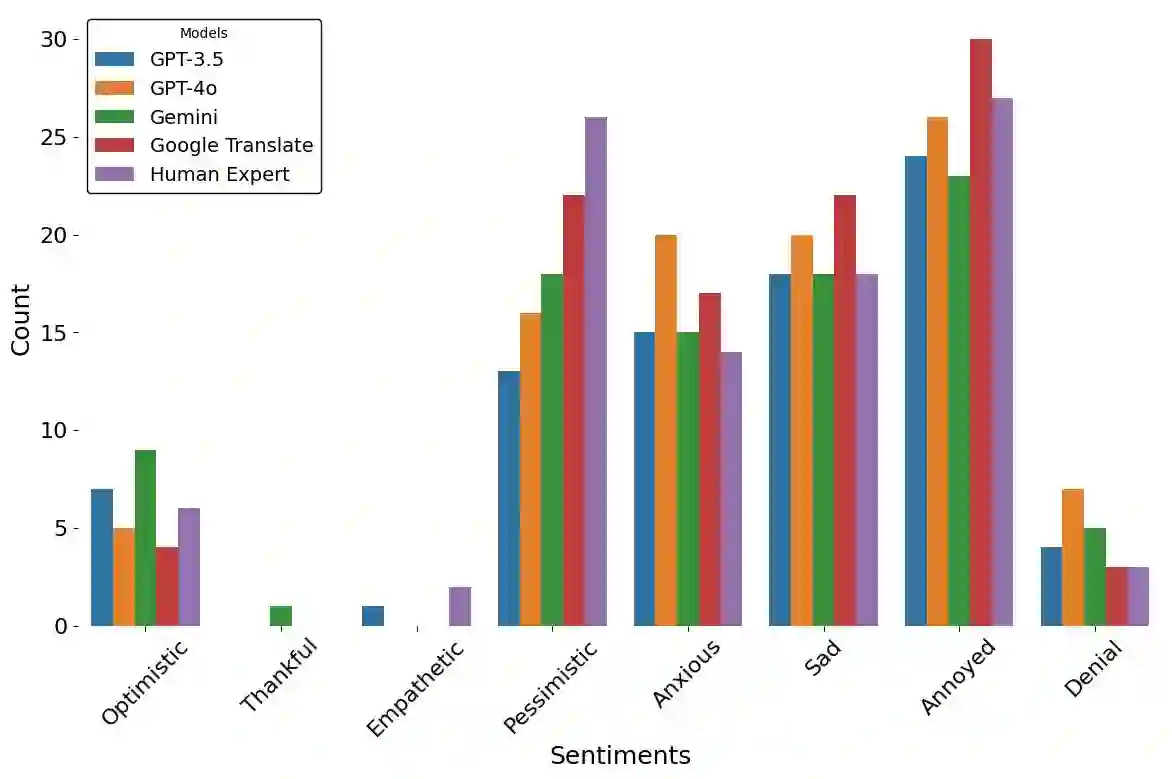
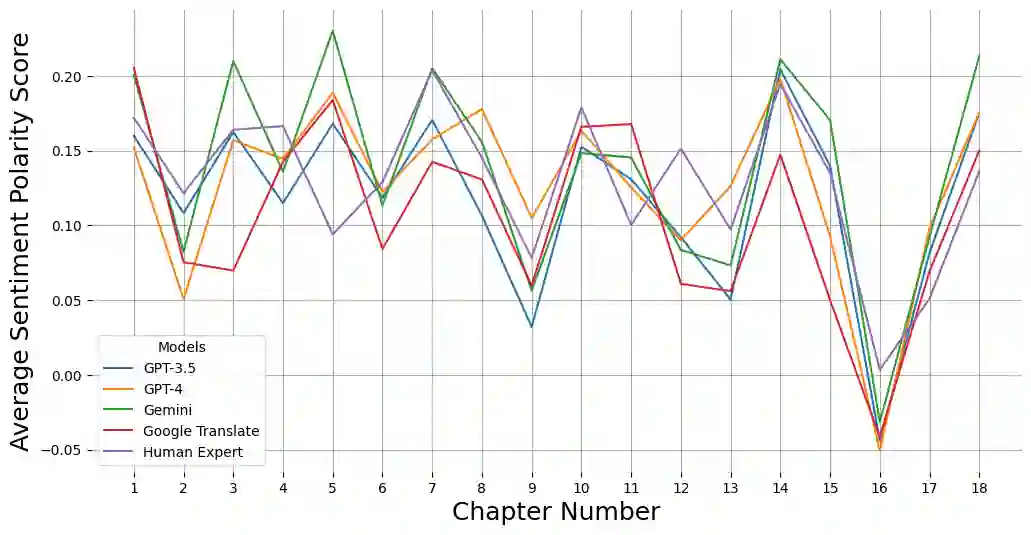
Large Language models (LLMs) have been prominent for language translation, including low-resource languages. There has been limited study about the assessment of the quality of translations generated by LLMs, including Gemini, GPT and Google Translate. In this study, we address this limitation by using semantic and sentiment analysis of selected LLMs for Indian languages, including Sanskrit, Telugu and Hindi. We select prominent texts that have been well translated by experts and use LLMs to generate their translations to English, and then we provide a comparison with selected expert (human) translations. Our findings suggest that while LLMs have made significant progress in translation accuracy, challenges remain in preserving sentiment and semantic integrity, especially in figurative and philosophical contexts. The sentiment analysis revealed that GPT-4o and GPT-3.5 are better at preserving the sentiments for the Bhagavad Gita (Sanskrit-English) translations when compared to Google Translate. We observed a similar trend for the case of Tamas (Hindi-English) and Maha P (Telugu-English) translations. GPT-4o performs similarly to GPT-3.5 in the translation in terms of sentiments for the three languages. We found that LLMs are generally better at translation for capturing sentiments when compared to Google Translate.
翻译:大型语言模型(LLM)在语言翻译领域表现突出,包括低资源语言翻译。然而,针对LLM(如Gemini、GPT系列)及谷歌翻译生成译文质量的评估研究仍较为有限。本研究通过语义分析与情感分析,评估了LLM在梵语、泰卢固语和印地语等选定印度语言翻译中的表现。我们选取专家优质译本的经典文本,使用LLM将其译为英文,并与专家(人工)译本进行对比。研究发现:尽管LLM在翻译准确性方面取得显著进展,但在保持情感与语义完整性方面仍存在挑战,尤其在比喻性与哲学性语境中。情感分析表明,在《薄伽梵歌》(梵语-英语)翻译中,GPT-4o与GPT-3.5在情感保留方面优于谷歌翻译。在《Tamas》(印地语-英语)与《Maha P》(泰卢固语-英语)翻译中也观察到相似趋势。就三种语言翻译的情感保持而言,GPT-4o与GPT-3.5表现相当。总体而言,LLM在翻译中捕捉情感的能力普遍优于谷歌翻译。