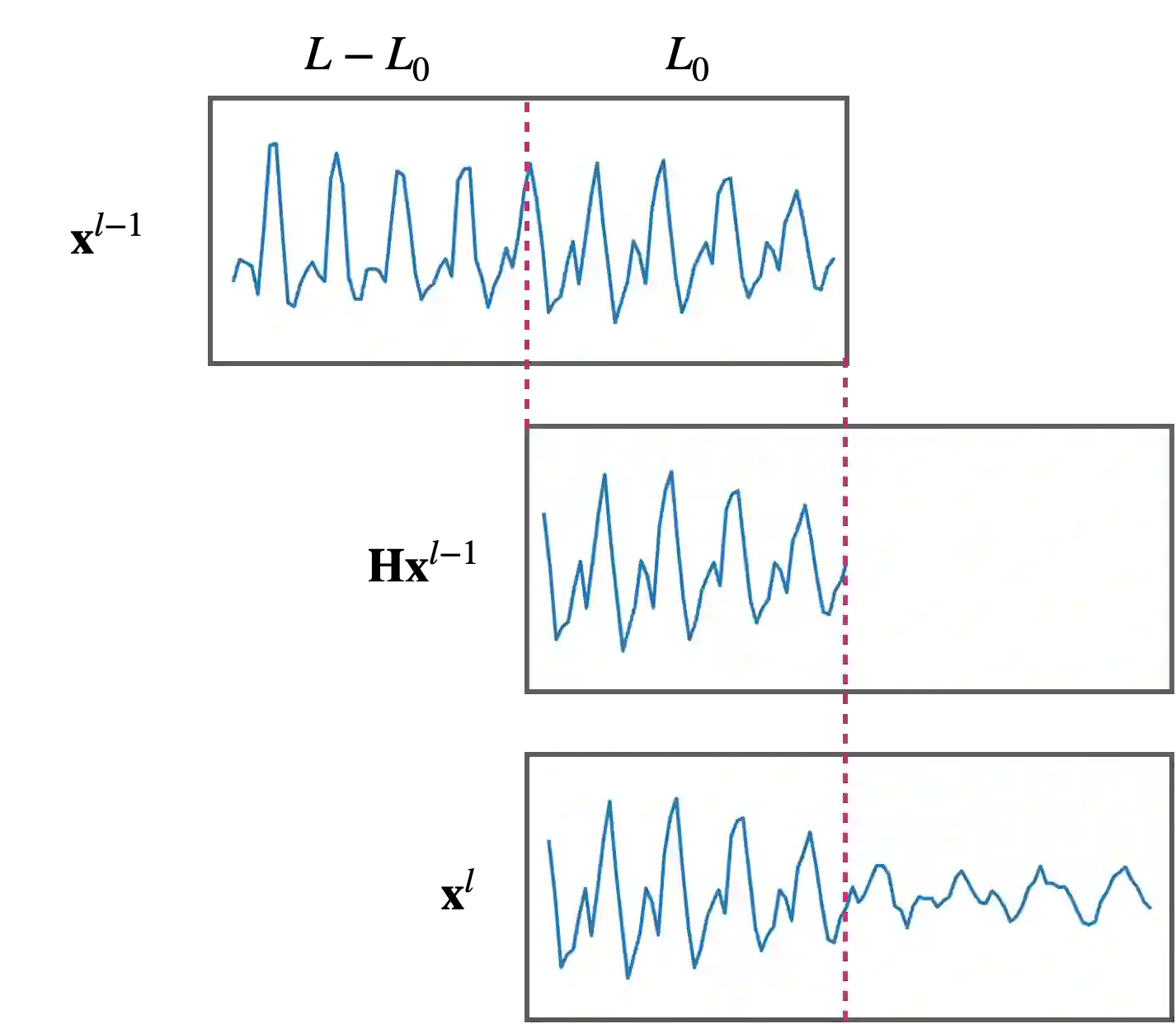
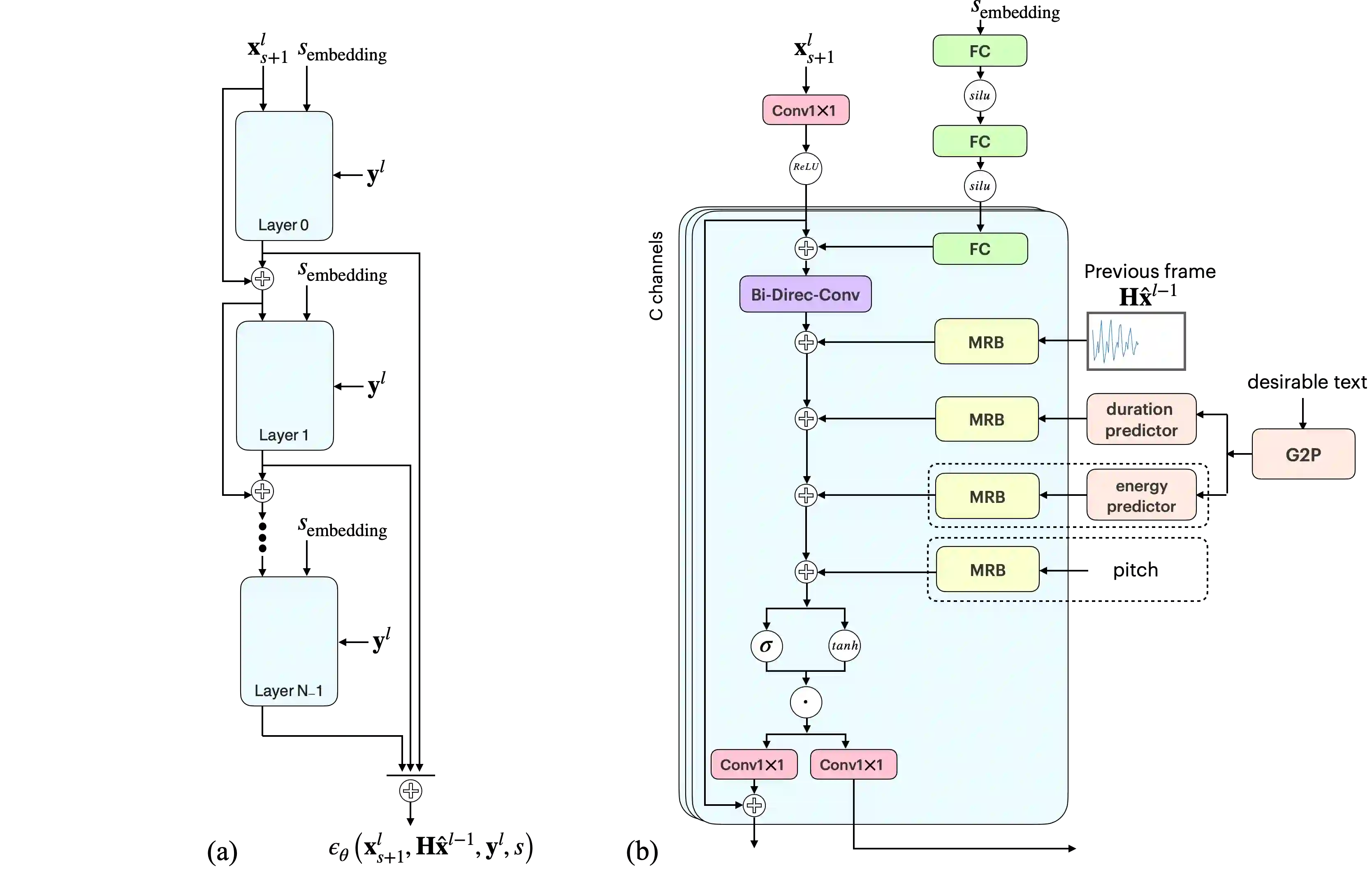
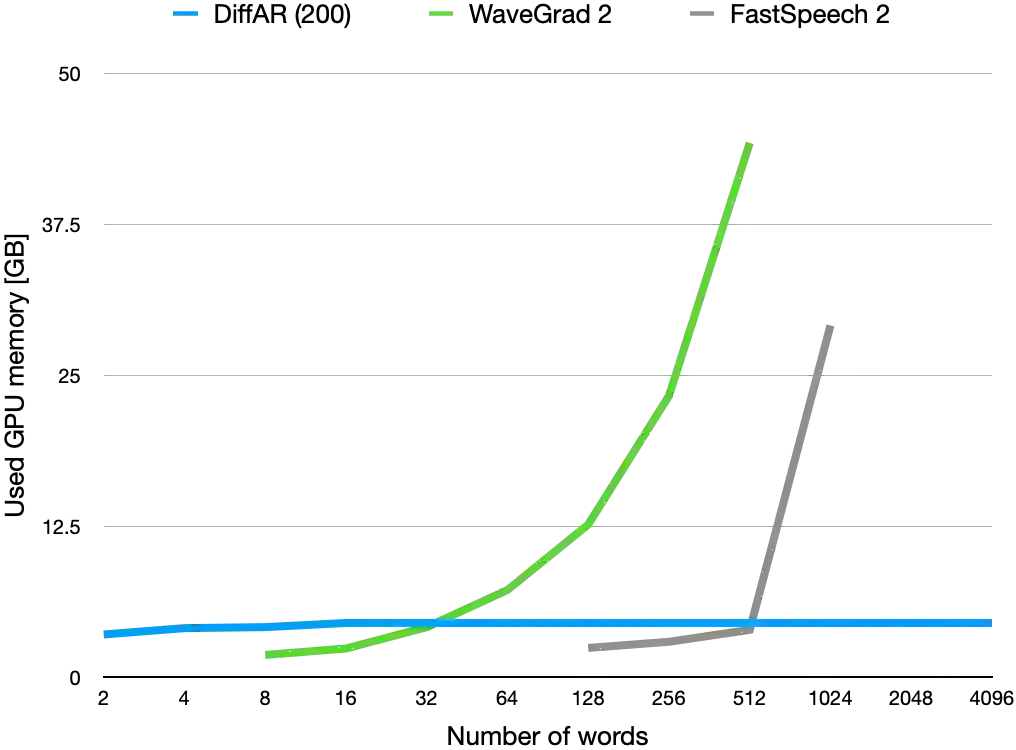
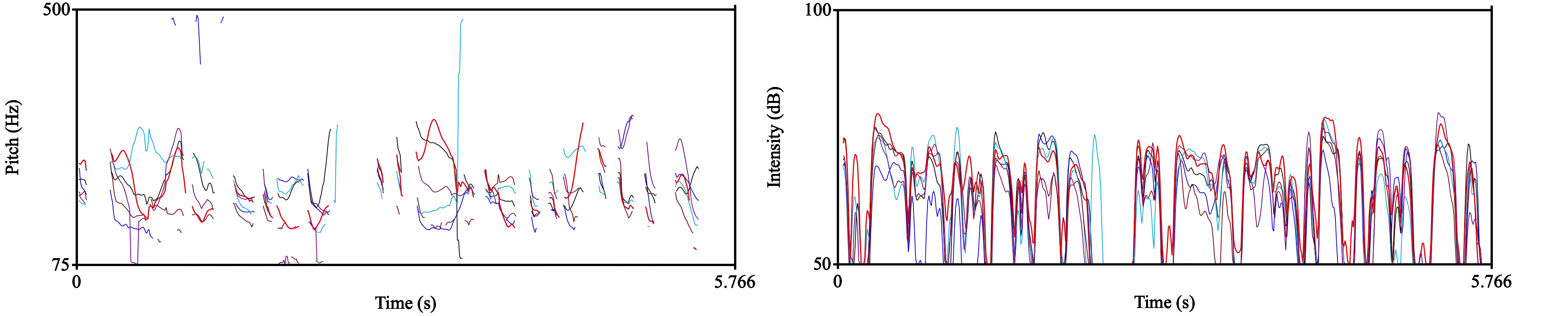Diffusion models have recently been shown to be relevant for high-quality speech generation. Most work has been focused on generating spectrograms, and as such, they further require a subsequent model to convert the spectrogram to a waveform (i.e., a vocoder). This work proposes a diffusion probabilistic end-to-end model for generating a raw speech waveform. The proposed model is autoregressive, generating overlapping frames sequentially, where each frame is conditioned on a portion of the previously generated one. Hence, our model can effectively synthesize an unlimited speech duration while preserving high-fidelity synthesis and temporal coherence. We implemented the proposed model for unconditional and conditional speech generation, where the latter can be driven by an input sequence of phonemes, amplitudes, and pitch values. Working on the waveform directly has some empirical advantages. Specifically, it allows the creation of local acoustic behaviors, like vocal fry, which makes the overall waveform sounds more natural. Furthermore, the proposed diffusion model is stochastic and not deterministic; therefore, each inference generates a slightly different waveform variation, enabling abundance of valid realizations. Experiments show that the proposed model generates speech with superior quality compared with other state-of-the-art neural speech generation systems.
翻译:扩散模型近期已被证明适用于高质量语音生成。现有研究多聚焦于声谱图生成,因而需要额外模型将声谱图转换为波形(即声码器)。本文提出一种用于生成原始语音波形的扩散概率端到端模型。该模型采用自回归架构,通过顺序生成重叠帧,其中每一帧的条件依赖于先前生成帧的部分信息。由此,模型可在保持高保真合成与时间连贯性的同时,有效合成任意长度的语音。我们实现了无条件与条件语音生成两种模式,后者可通过输入音素、振幅及音高序列进行驱动。直接对波形建模具有若干实证优势:其一,可生成局部声学行为(如气泡音),使整体波形听感更自然;其二,所提出的扩散模型具有随机性而非确定性特征,因此每次推理都会生成略有差异的波形变体,从而产生丰富的有效实现。实验表明,与当前最先进的神经语音生成系统相比,本模型生成的语音具有更优质量。