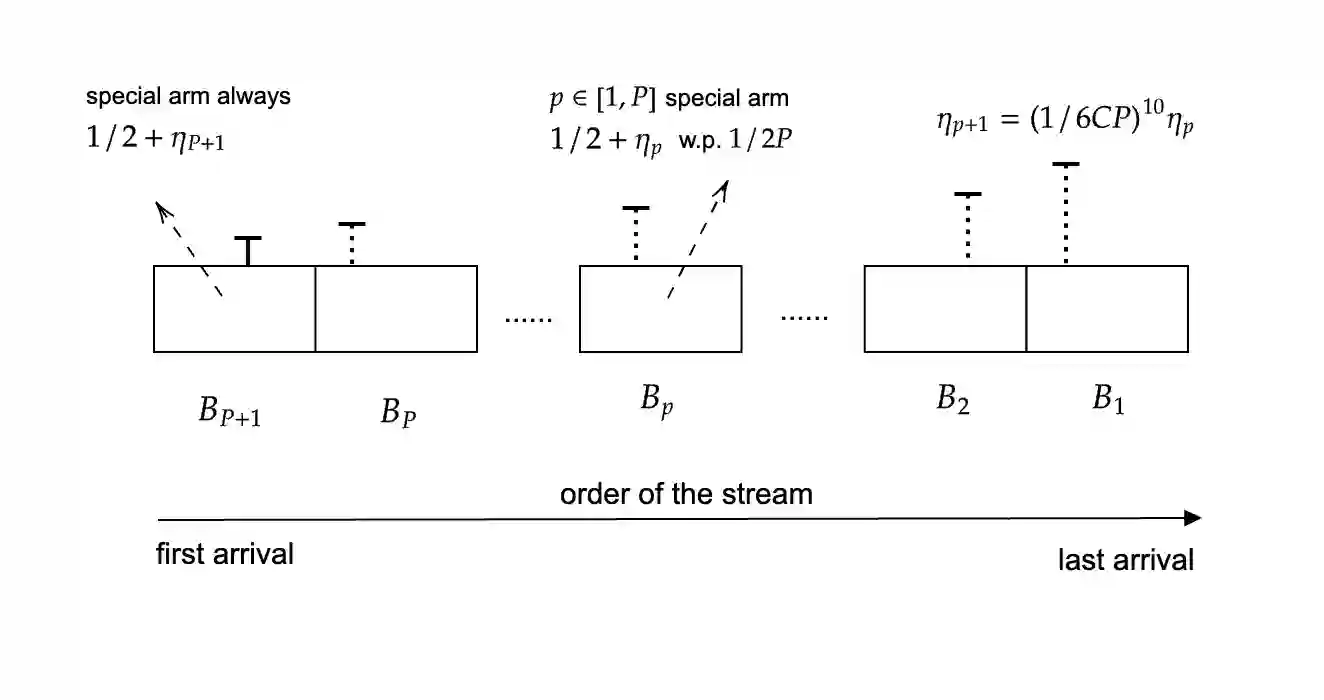
We give a near-optimal sample-pass trade-off for pure exploration in multi-armed bandits (MABs) via multi-pass streaming algorithms: any streaming algorithm with sublinear memory that uses the optimal sample complexity of $O(\frac{n}{\Delta^2})$ requires $\Omega(\frac{\log{(1/\Delta)}}{\log\log{(1/\Delta)}})$ passes. Here, $n$ is the number of arms and $\Delta$ is the reward gap between the best and the second-best arms. Our result matches the $O(\log(\frac{1}{\Delta}))$-pass algorithm of Jin et al. [ICML'21] (up to lower order terms) that only uses $O(1)$ memory and answers an open question posed by Assadi and Wang [STOC'20].
翻译:我们针对多臂赌博机(MAB)中的纯探索问题,通过多轮次流式算法给出了近乎最优的样本-轮次权衡:任何使用次线性内存且达到最优样本复杂度 $O(\frac{n}{\Delta^2})$ 的流式算法,都需要 $\Omega(\frac{\log{(1/\Delta)}}{\log\log{(1/\Delta)}})$ 轮次。其中 $n$ 表示臂的数量,$\Delta$ 表示最优臂与次优臂之间的奖励间隔。我们的结果与 Jin 等人 [ICML'21] 提出的仅使用 $O(1)$ 内存的 $O(\log(\frac{1}{\Delta}))$ 轮次算法(仅相差低阶项)相匹配,并回答了 Assadi 与 Wang [STOC'20] 提出的一个开放性问题。