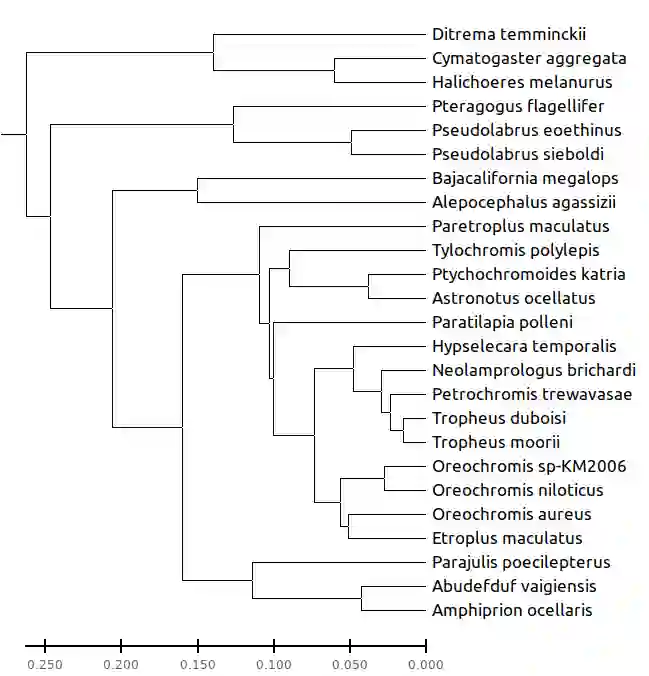
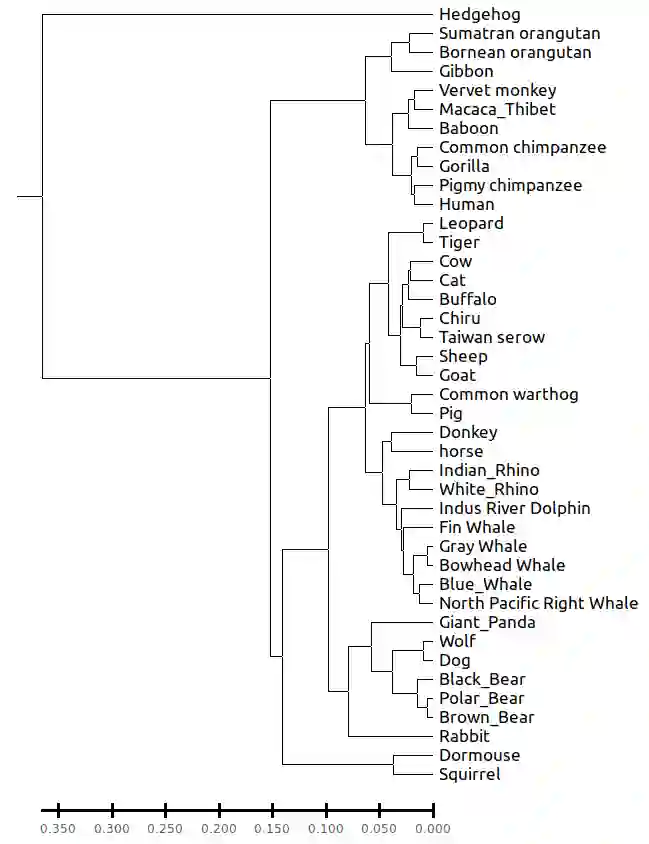
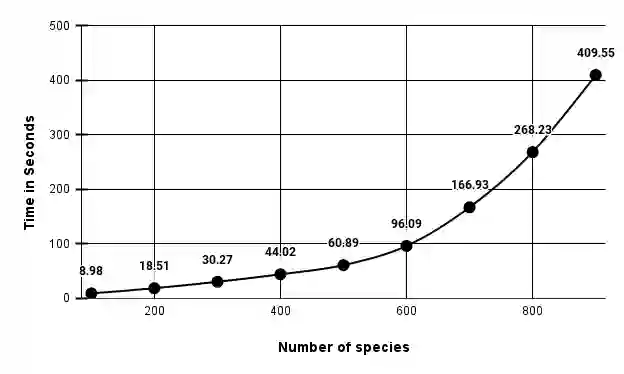
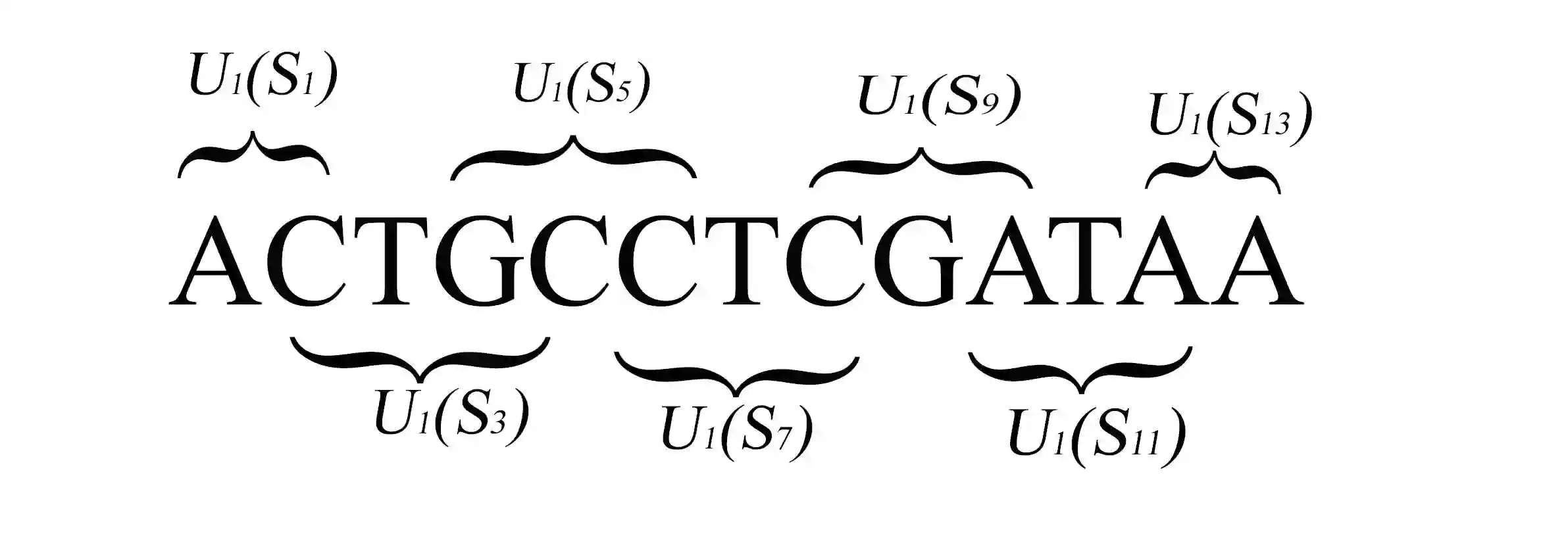We construct a compact vector representation on $\mathbb{R}^{24}$ of a DNA sequence of arbitrary length. Each component of this vector is obtained from a representative sequence, the elements of which are the values realized by a function $\Gamma$. The function $\Gamma$, so defined, acts on neighborhoods of arbitrary radius that are located at strategic positions within the DNA sequence. $\Gamma$ carries complete information about the local multiplicity of the nucleotides as a consequence of the uniqueness of prime factorisation of integer. The two parameters characterizing the radius and location of the neighbourhoods are fixed by comparing the phylogenetic tree we find through our algorithm with standard results for the $\beta$ -globin gene sequences of eleven different species. Remarkably, the time complexity for this similarity analysis turns out to be $\mathcal{O}(n)$. Using the values of the two fitting parameters so obtained, the method is further applied to analyze mitochondrial genome sequences.
翻译:我们构建了一个紧致的向量表示,将任意长度的DNA序列映射到$\mathbb{R}^{24}$空间。该向量的每个分量均从一条代表性序列中提取,该序列的元素由函数$\Gamma$的实现值构成。所定义的函数$\Gamma$作用于位于DNA序列内战略位置的任意半径邻域。由于整数质因数分解的唯一性,$\Gamma$携带了核苷酸局部多样性的完整信息。通过将我们的算法构建的系统发育树与十一个不同物种的$\beta$-珠蛋白基因序列的标准结果进行比对,我们确定了表征邻域半径和位置的两个参数。值得注意的是,该相似性分析的时间复杂度为$\mathcal{O}(n)$。利用由此获得的拟合参数值,该方法进一步应用于线粒体基因组序列的分析。