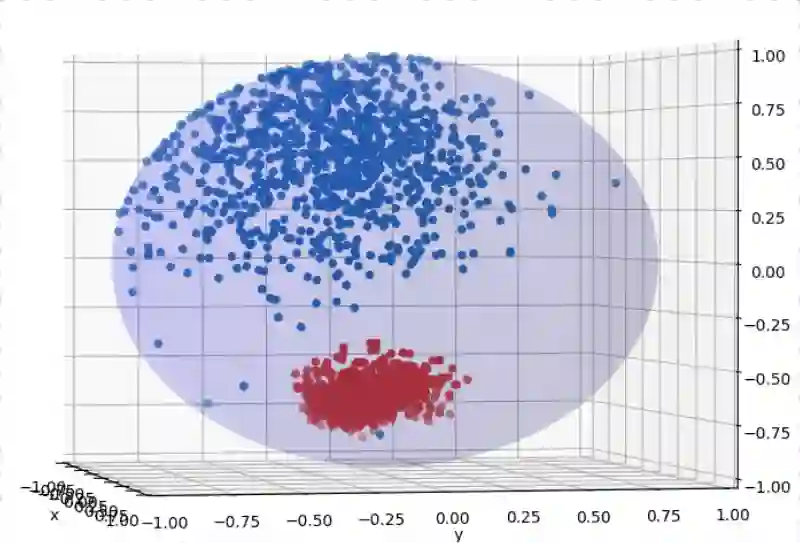
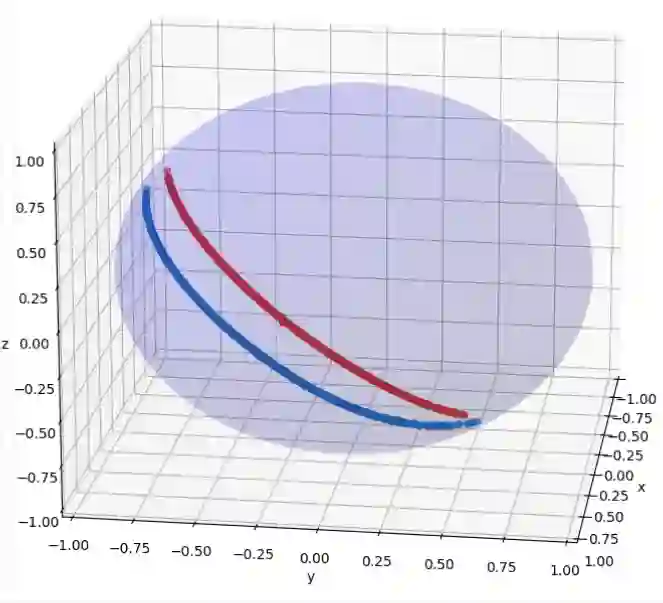
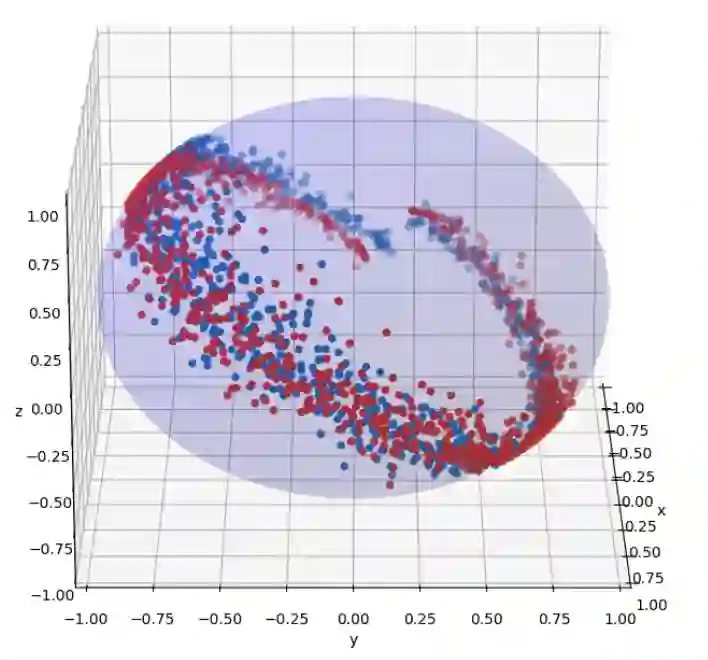
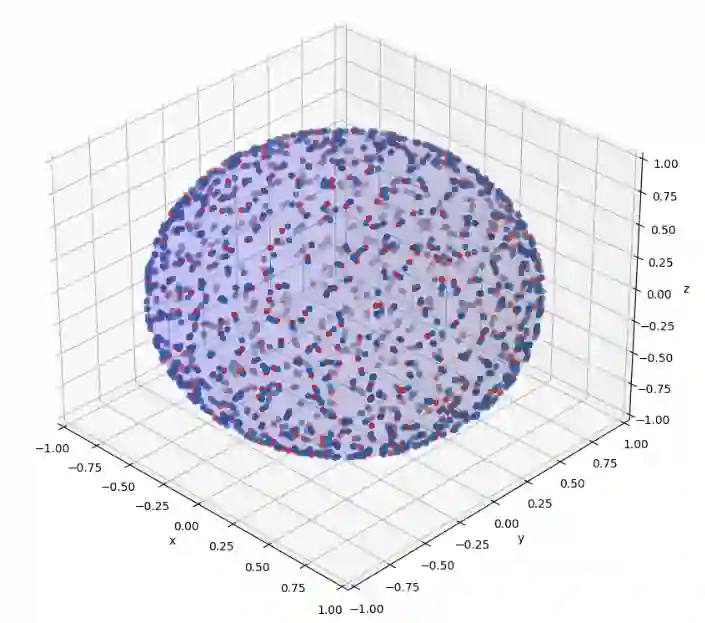
Multi-modal contrastive models such as CLIP achieve state-of-the-art performance in zero-shot classification by embedding input images and texts on a joint representational space. Recently, a modality gap has been reported in two-encoder contrastive models like CLIP, meaning that the image and text embeddings reside in disjoint areas of the latent space. Previous studies suggest that this gap exists due to 1) the cone effect, 2) mismatched pairs in the dataset, and 3) insufficient training. We show that, even when accounting for all these factors, and even when using the same modality, the contrastive loss actually creates a gap during training. As a result, We propose that the modality gap is inherent to the two-encoder contrastive loss and rename it the contrastive gap. We present evidence that attributes this contrastive gap to low uniformity in CLIP space, resulting in embeddings that occupy only a small portion of the latent space. To close the gap, we adapt the uniformity and alignment properties of unimodal contrastive loss to the multi-modal setting and show that simply adding these terms to the CLIP loss distributes the embeddings more uniformly in the representational space, closing the gap. In our experiments, we show that the modified representational space achieves better performance than default CLIP loss in downstream tasks such as zero-shot image classification and multi-modal arithmetic.
翻译:诸如CLIP等多模态对比学习模型通过将输入图像与文本嵌入到联合表征空间中,在零样本分类任务上取得了最先进的性能。近期研究发现,在CLIP这类双编码器对比模型中存在模态鸿沟现象,即图像与文本嵌入向量潜居于潜在空间中互不相交的区域。先前研究将此归因于:1)锥体效应,2)数据集中不匹配的配对样本,以及3)训练不充分。本文证明,即使排除所有这些因素,甚至在使用相同模态时,对比损失函数本身就会在训练过程中产生间隙。因此我们认为,模态鸿沟是双编码器对比损失函数的内在特性,并将其重新命名为对比学习间隙。我们提供的证据表明,该间隙可归因于CLIP空间中的低均匀性,导致嵌入向量仅占据潜在空间的极小部分。为消除此间隙,我们将单模态对比损失的均匀性与对齐性准则适配到多模态场景,并证明只需将这些项添加到CLIP损失函数中,即可使嵌入向量在表征空间中更均匀分布,从而消除间隙。实验表明,改进后的表征空间在零样本图像分类和多模态算术等下游任务中,均优于原始CLIP损失函数所获得的表现。