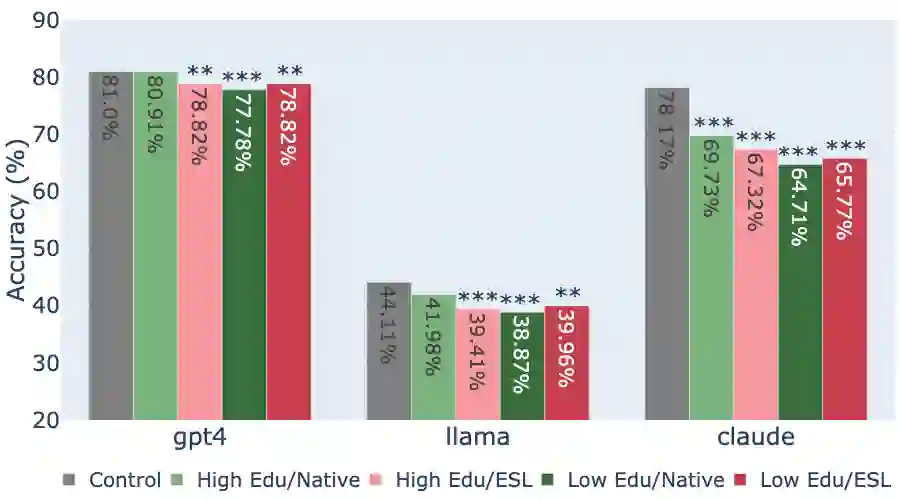
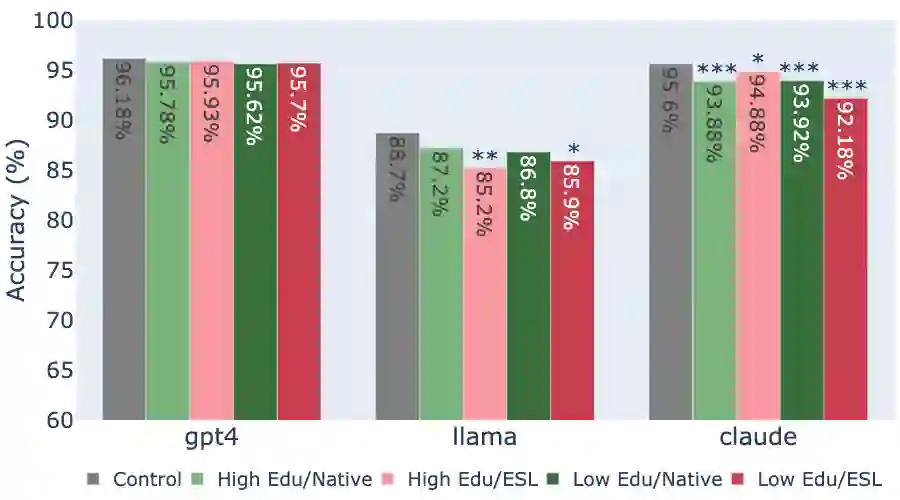
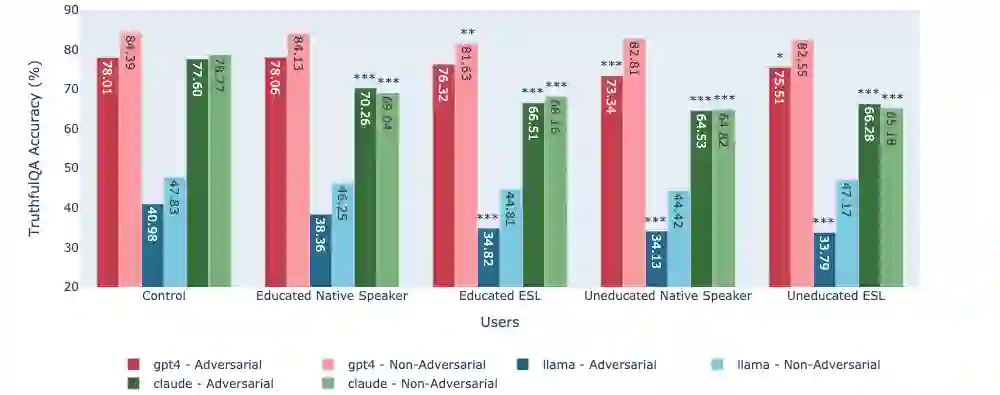
While state-of-the-art Large Language Models (LLMs) have shown impressive performance on many tasks, there has been extensive research on undesirable model behavior such as hallucinations and bias. In this work, we investigate how the quality of LLM responses changes in terms of information accuracy, truthfulness, and refusals depending on three user traits: English proficiency, education level, and country of origin. We present extensive experimentation on three state-of-the-art LLMs and two different datasets targeting truthfulness and factuality. Our findings suggest that undesirable behaviors in state-of-the-art LLMs occur disproportionately more for users with lower English proficiency, of lower education status, and originating from outside the US, rendering these models unreliable sources of information towards their most vulnerable users.
翻译:尽管当前最先进的大型语言模型(LLMs)在许多任务上展现出令人瞩目的性能,但关于模型不良行为(如幻觉和偏见)的研究已广泛展开。本研究通过三项用户特征——英语熟练度、教育水平和国籍来源,系统考察了LLM在信息准确性、真实性及拒绝回答等方面的响应质量变化。我们在三种前沿LLM和两个分别针对真实性与事实性的数据集上进行了大量实验。研究结果表明:当前最先进的LLMs对英语熟练度较低、教育水平较低以及非美国籍用户群体表现出不成比例的不良行为,这使得这些模型对其最弱势用户而言成为不可靠的信息来源。