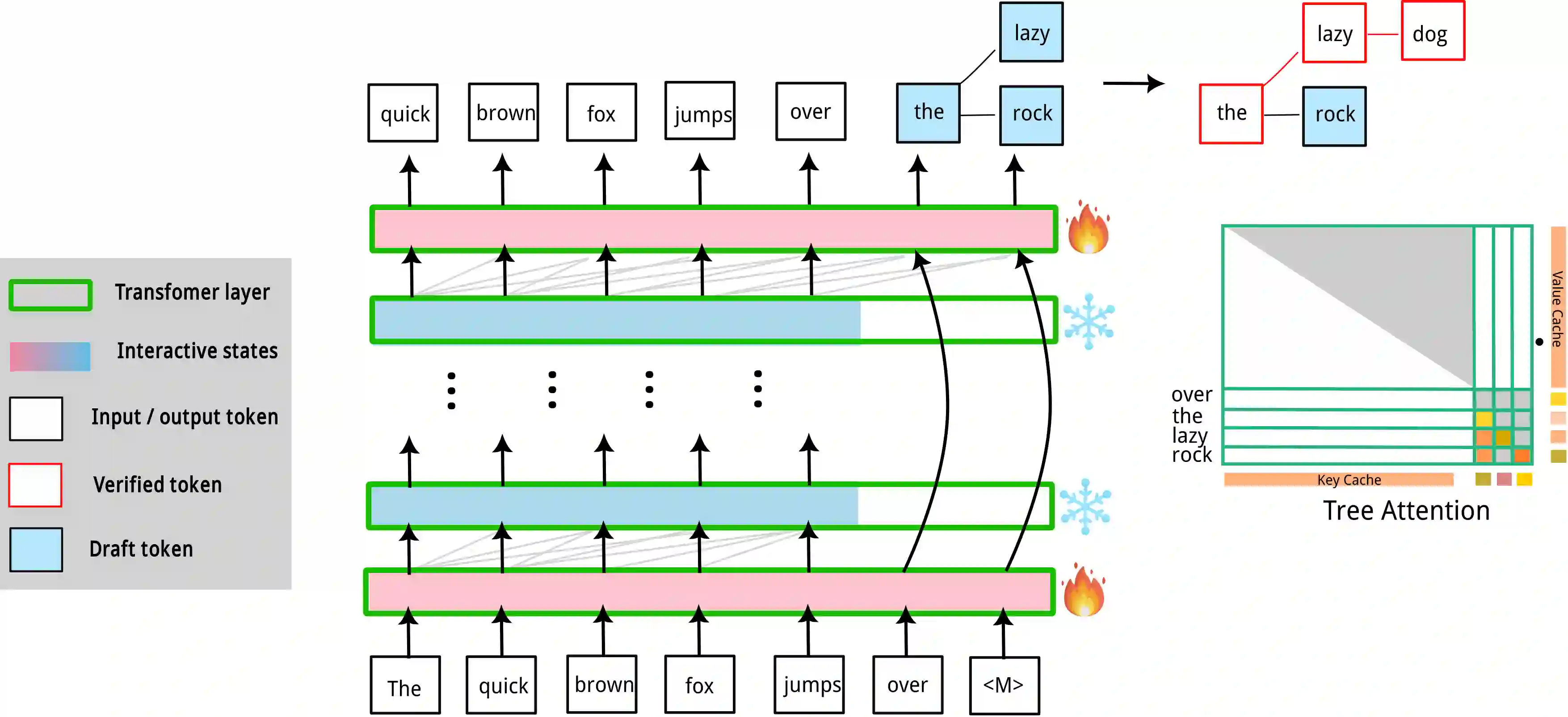
Speculative decoding (SD) has attracted a significant amount of research attention due to the substantial speedup it can achieve for LLM inference. However, despite the high speedups they offer, speculative decoding methods often achieve optimal performance on high-end devices or with a substantial GPU memory overhead. Given limited memory and the necessity of quantization, a high-performing model on a high-end GPU can slow down by up to 7 times. To this end, we propose Skippy Simultaneous Speculative Decoding (or S3D), a cost-effective self-speculative SD method based on simultaneous multi-token decoding and mid-layer skipping. When compared against recent effective open-source SD systems, our method has achieved one of the top performance-memory ratios while requiring minimal architecture changes and training data. Leveraging our memory efficiency, we created a smaller yet more effective SD model based on Phi-3. It is 1.4 to 2 times faster than the quantized EAGLE model and operates in half-precision while using less VRAM.
翻译:推测解码因其能为大语言模型推理带来显著加速而受到广泛研究关注。然而,尽管现有推测解码方法能提供较高的加速比,但其通常需在高性能设备上或消耗大量GPU内存才能达到最优性能。考虑到有限的内存和量化处理的必要性,在高性能GPU上表现优异的模型可能面临高达7倍的减速。为此,我们提出跳跃式同步推测解码(简称S3D),这是一种基于同步多令牌解码与中间层跳跃的高性价比自推测解码方法。与近期高效的开源推测解码系统相比,本方法在实现顶尖性能-内存比的同时,仅需最小的架构改动与训练数据。借助我们的内存效率优势,我们基于Phi-3构建了一个更小却更有效的推测解码模型。该模型在保持半精度运行且占用更少显存的情况下,其推理速度比量化版EAGLE模型快1.4至2倍。