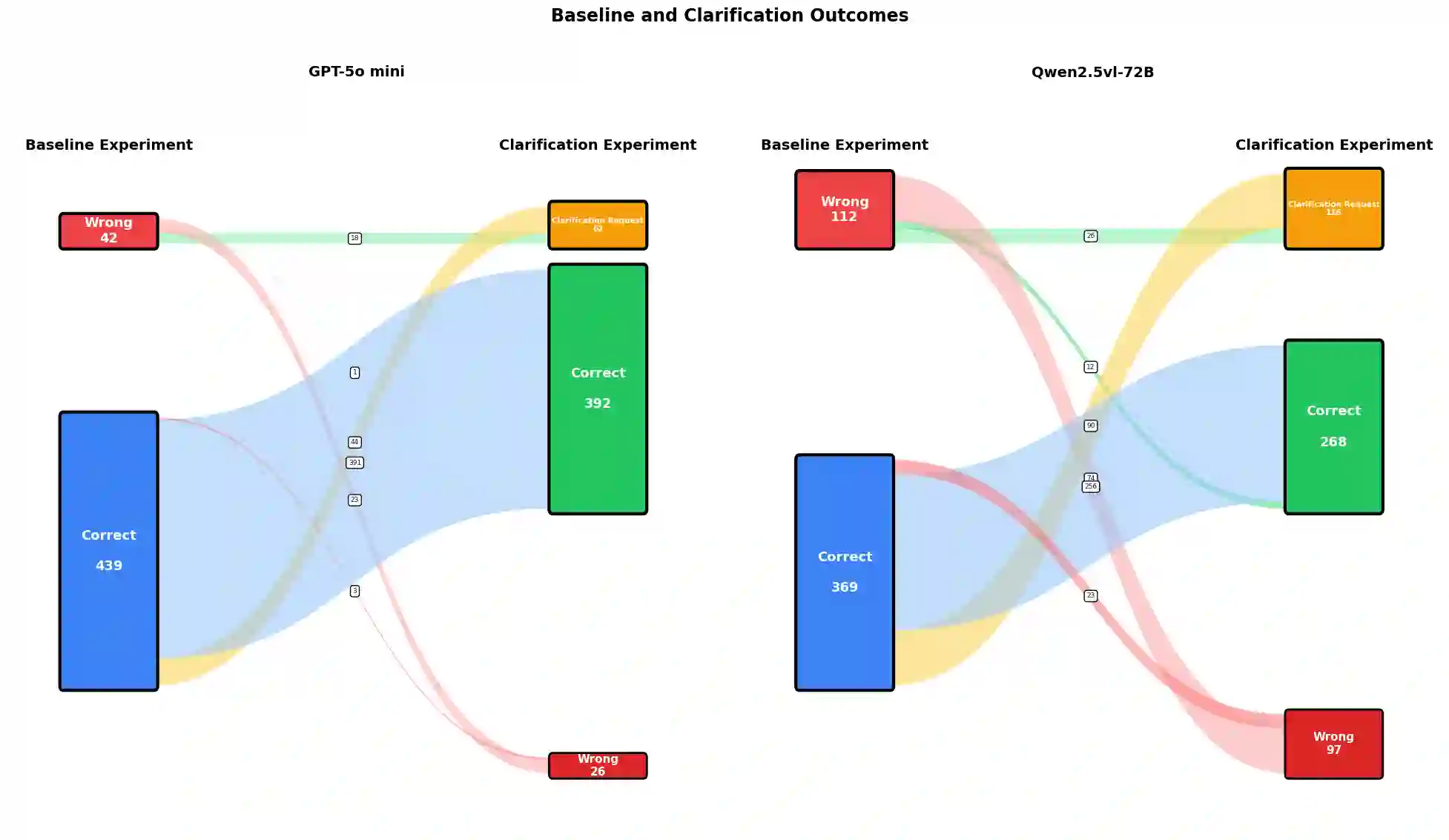
In human conversation, both interlocutors play an active role in maintaining mutual understanding. When addressees are uncertain about what speakers mean, for example, they can request clarification. It is an open question for language models whether they can assume a similar addressee role, recognizing and expressing their own uncertainty through clarification. We argue that reference games are a good testbed to approach this question as they are controlled, self-contained, and make clarification needs explicit and measurable. To test this, we evaluate three vision-language models comparing a baseline reference resolution task to an experiment where the models are instructed to request clarification when uncertain. The results suggest that even in such simple tasks, models often struggle to recognize internal uncertainty and translate it into adequate clarification behavior. This demonstrates the value of reference games as testbeds for interaction qualities of (vision and) language models.
翻译:在人类对话中,对话双方都积极维护相互理解。例如,当受话者对说话者的意思不确定时,可以请求澄清。对于语言模型而言,它们是否能承担类似的受话者角色,通过澄清来识别和表达自身的不确定性,仍是一个开放性问题。我们认为参考游戏是研究此问题的良好测试平台,因为它们具有可控性、自包含性,且能使澄清需求变得明确且可测量。为验证这一点,我们评估了三个视觉-语言模型,将基线参考解析任务与一项实验进行对比,该实验指示模型在不确定时请求澄清。结果表明,即使在此类简单任务中,模型也常常难以识别内部不确定性并将其转化为恰当的澄清行为。这证明了参考游戏作为(视觉和)语言模型交互特性测试平台的价值。