
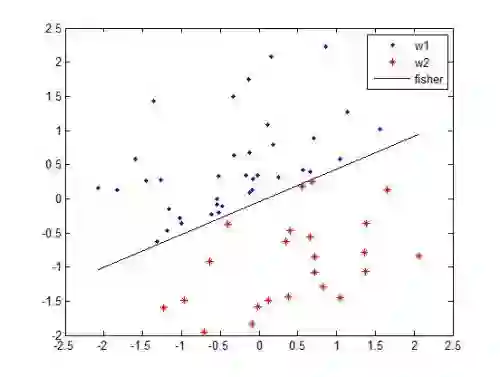
Many classification problems focus on maximizing the performance only on the samples with the highest relevance instead of all samples. As an example, we can mention ranking problems, accuracy at the top or search engines where only the top few queries matter. In our previous work, we derived a general framework including several classes of these linear classification problems. In this paper, we extend the framework to nonlinear classifiers. Utilizing a similarity to SVM, we dualize the problems, add kernels and propose a componentwise dual ascent method.
翻译:许多分类问题仅关注最大化最高相关性样本上的性能,而非所有样本。例如,排序问题、顶部准确率或搜索引擎中仅需考量少数最相关查询。在先前工作中,我们构建了一个包含多类此类线性分类问题的通用框架。本文将框架扩展至非线性分类器。利用与支持向量机的相似性,我们对问题进行对偶化处理、引入核函数,并提出一种分量对偶上升方法。
相关内容
专知会员服务
46+阅读 · 2020年7月29日
专知会员服务
71+阅读 · 2020年2月5日
专知会员服务
37+阅读 · 2019年10月17日
Arxiv
17+阅读 · 2019年9月9日


最新内容
相关VIP内容
专知会员服务
46+阅读 · 2020年7月29日
专知会员服务
71+阅读 · 2020年2月5日
专知会员服务
37+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
17+阅读 · 2019年9月9日