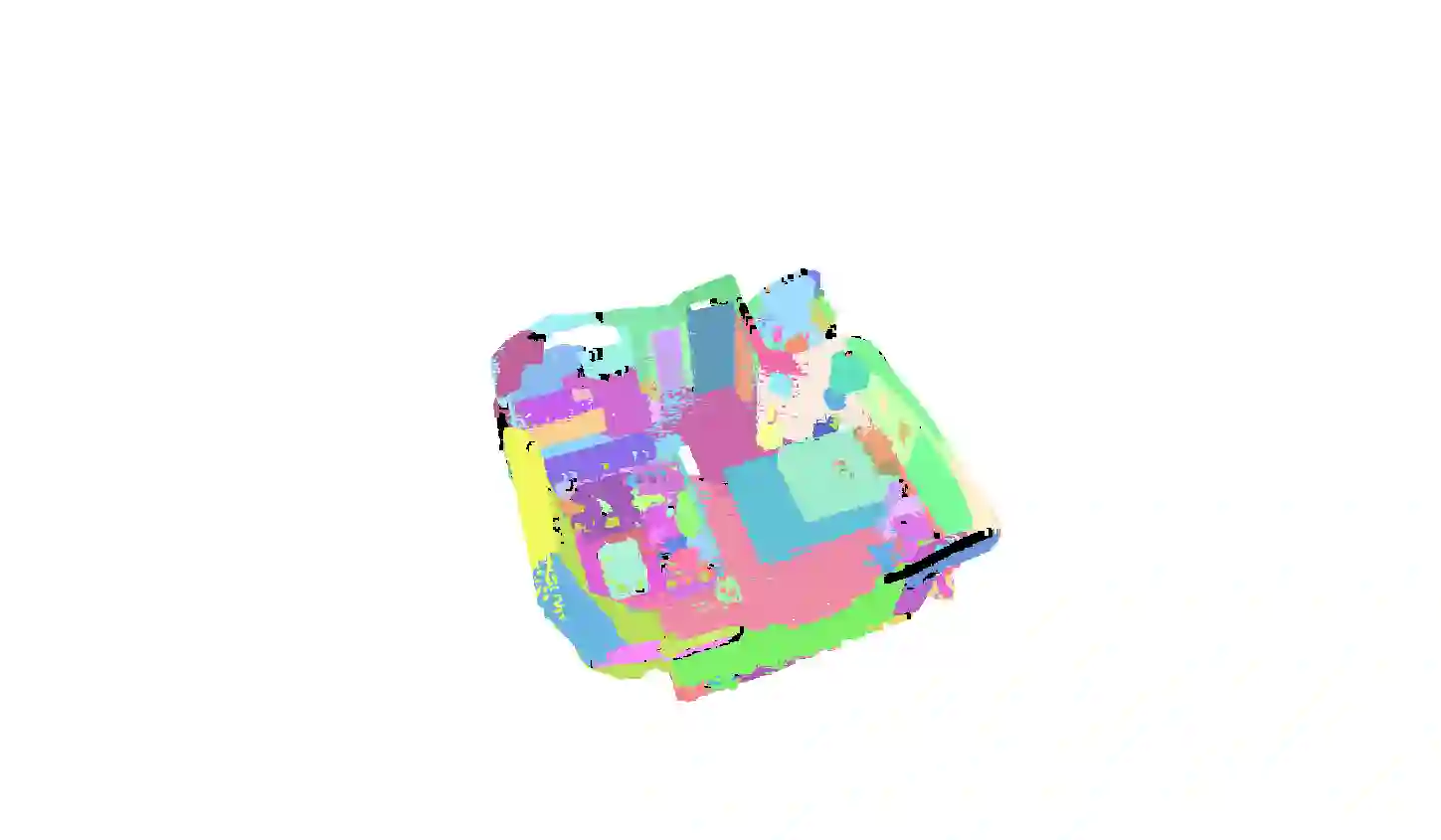
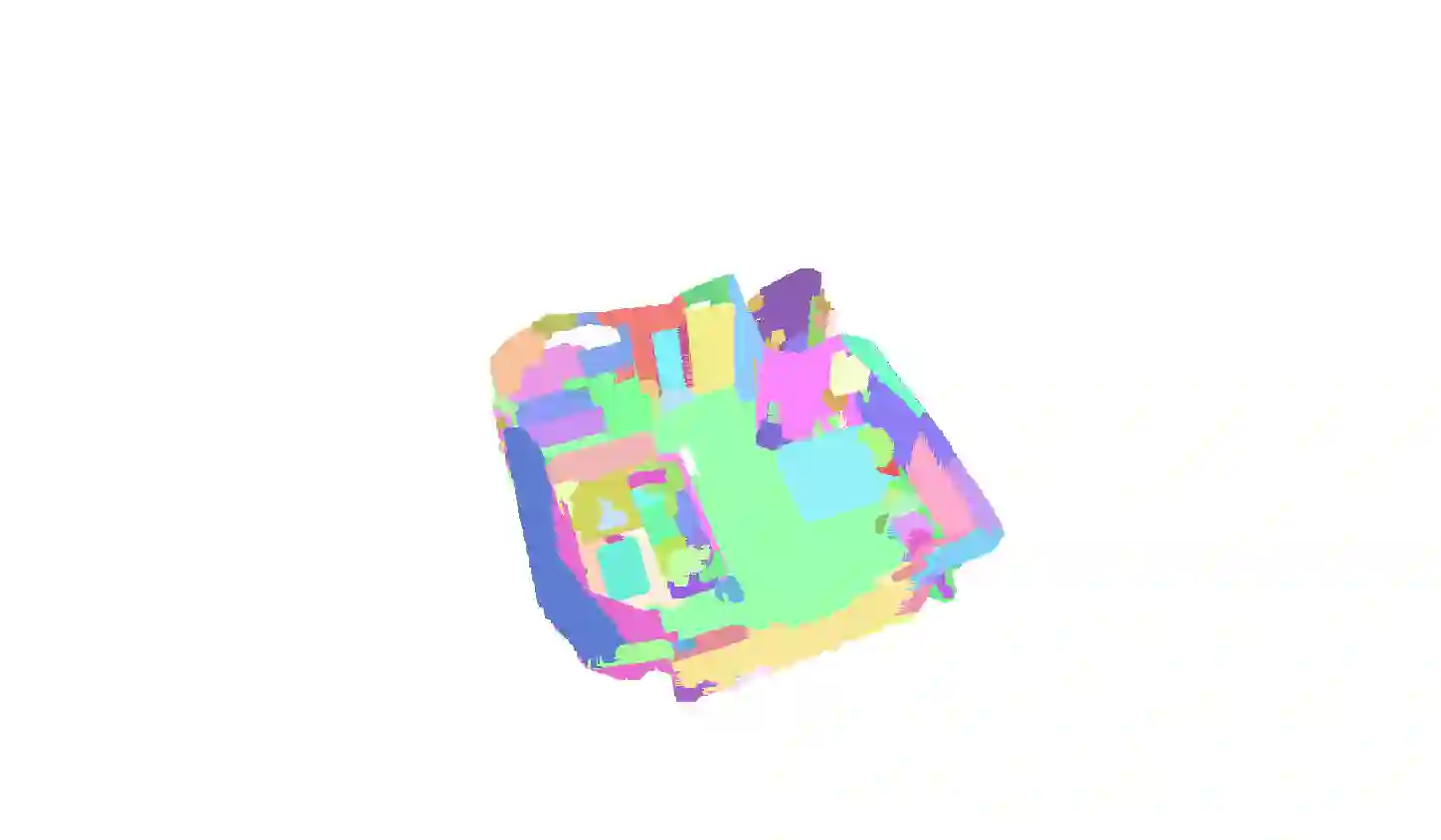
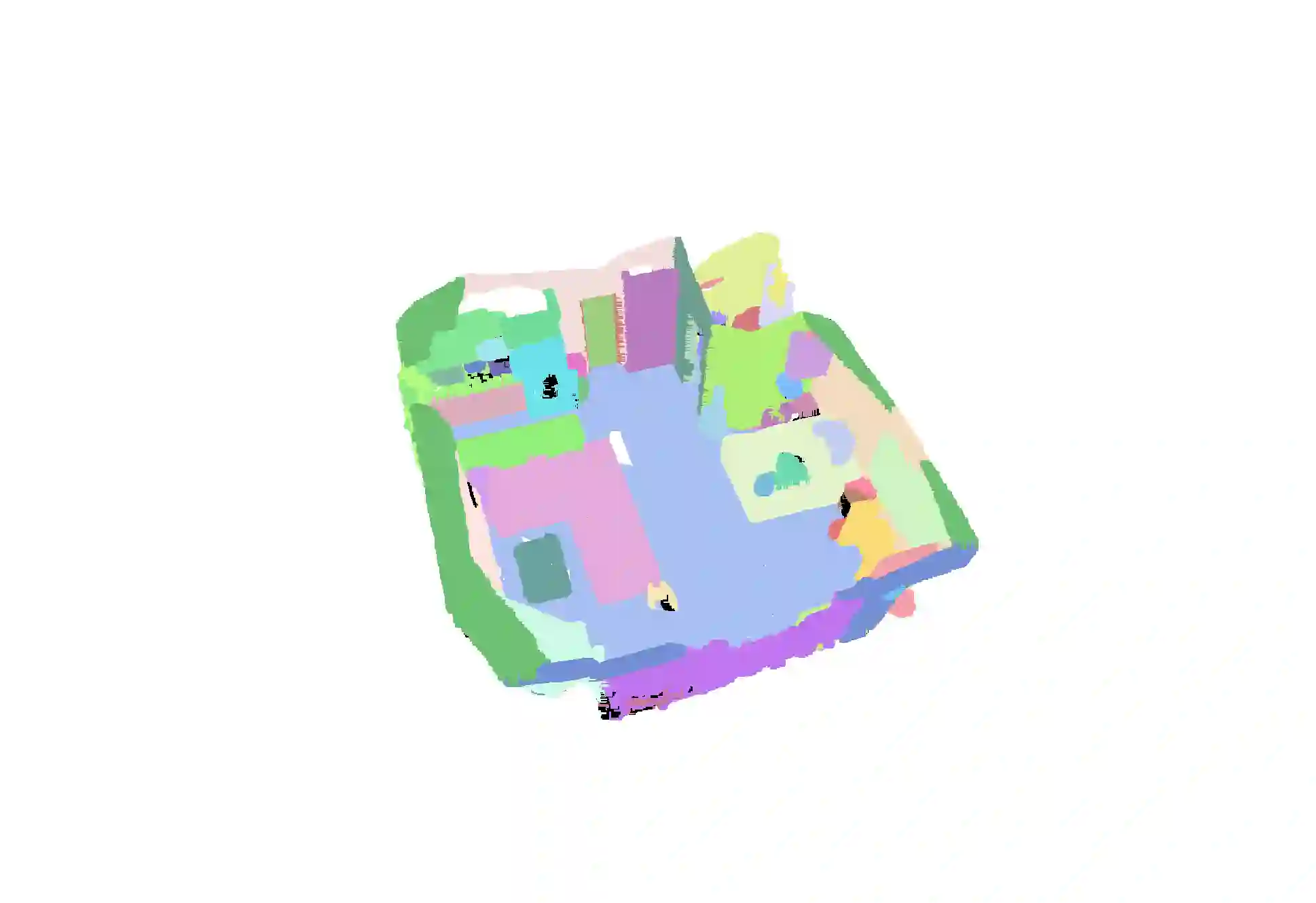
In this work, we propose SAM3D, a novel framework that is able to predict masks in 3D point clouds by leveraging the Segment-Anything Model (SAM) in RGB images without further training or finetuning. For a point cloud of a 3D scene with posed RGB images, we first predict segmentation masks of RGB images with SAM, and then project the 2D masks into the 3D points. Later, we merge the 3D masks iteratively with a bottom-up merging approach. At each step, we merge the point cloud masks of two adjacent frames with the bidirectional merging approach. In this way, the 3D masks predicted from different frames are gradually merged into the 3D masks of the whole 3D scene. Finally, we can optionally ensemble the result from our SAM3D with the over-segmentation results based on the geometric information of the 3D scenes. Our approach is experimented with ScanNet dataset and qualitative results demonstrate that our SAM3D achieves reasonable and fine-grained 3D segmentation results without any training or finetuning of SAM.
翻译:本文提出SAM3D,一种新型框架,能够在无需进一步训练或微调的情况下,借助RGB图像中的分割一切模型(SAM)预测3D点云中的掩码。对于带有位姿RGB图像的三维场景点云,我们首先利用SAM预测RGB图像的分割掩码,然后将2D掩码投影到3D点中。随后,我们采用自底向上的合并方法迭代合并3D掩码。每一步中,我们通过双向合并方法融合相邻两帧的点云掩码。通过这种方式,从不同帧预测的3D掩码逐渐合并为整个三维场景的3D掩码。最后,我们可根据需要将SAM3D的结果与基于三维场景几何信息的过分割结果进行集成。该方法在ScanNet数据集上进行了实验,定性结果表明,我们的SAM3D无需对SAM进行任何训练或微调,即可获得合理且精细的3D分割结果。