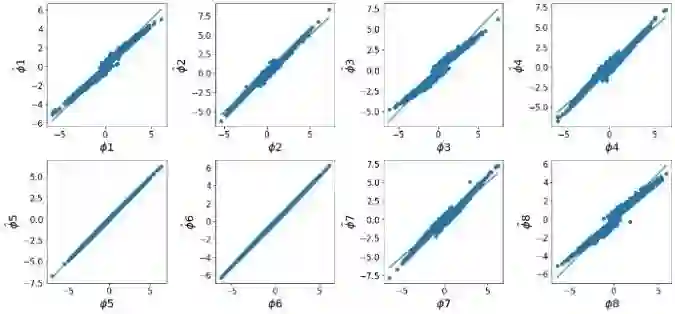
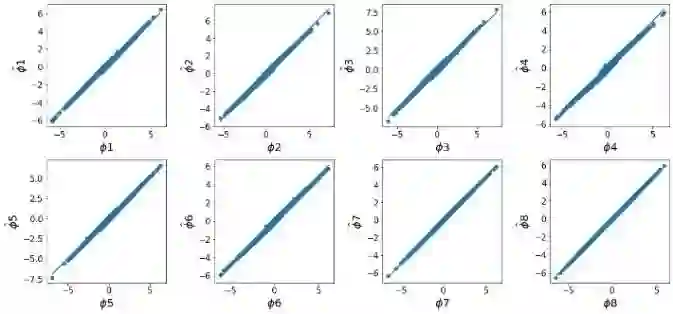
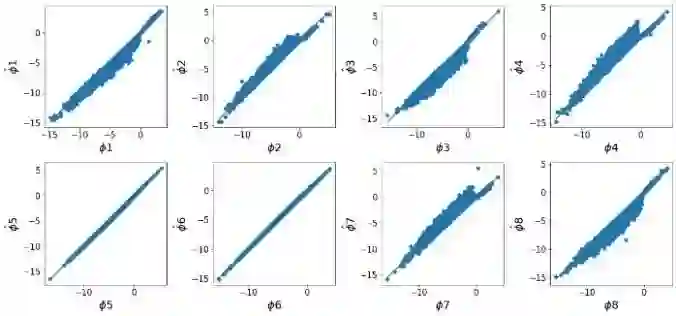
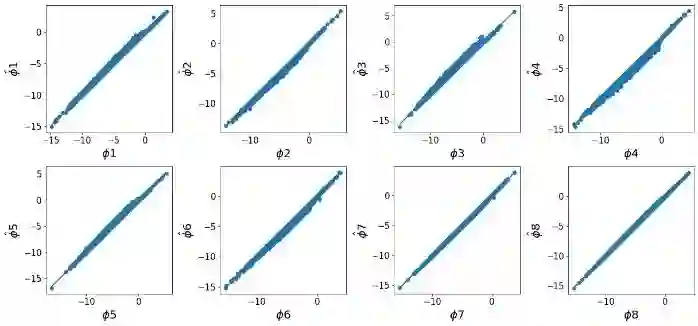
SHAP (SHapley Additive exPlanations) has become a popular method to attribute the prediction of a machine learning model on an input to its features. One main challenge of SHAP is the computation time. An exact computation of Shapley values requires exponential time complexity. Therefore, many approximation methods are proposed in the literature. In this paper, we propose methods that can compute SHAP exactly in polynomial time or even faster for SHAP definitions that satisfy our additivity and dummy assumptions (eg, kernal SHAP and baseline SHAP). We develop different strategies for models with different levels of model structure information: known functional decomposition, known order of model (defined as highest order of interaction in the model), or unknown order. For the first case, we demonstrate an additive property and a way to compute SHAP from the lower-order functional components. For the second case, we derive formulas that can compute SHAP in polynomial time. Both methods yield exact SHAP results. Finally, if even the order of model is unknown, we propose an iterative way to approximate Shapley values. The three methods we propose are computationally efficient when the order of model is not high which is typically the case in practice. We compare with sampling approach proposed in Castor & Gomez (2008) using simulation studies to demonstrate the efficacy of our proposed methods.
翻译:SHAP(SHapley Additive exPlanations)已成为将机器学习模型对输入的预测归因于其特征的流行方法。SHAP的主要挑战之一是计算时间。精确计算Shapley值需要指数级时间复杂度。因此,文献中提出了许多近似方法。在本文中,我们提出了一些方法,针对满足可加性和虚拟变量假设(例如,kernal SHAP和baseline SHAP)的SHAP定义,能够以多项式时间甚至更快的速度精确计算SHAP。我们针对具有不同级别模型结构信息的模型开发了不同策略:已知功能分解、已知模型阶数(定义为模型中交互作用的最高阶)或未知阶数。对于第一种情况,我们证明了一个可加性性质以及一种从低阶功能组件计算SHAP的方法。对于第二种情况,我们推导出能够以多项式时间计算SHAP的公式。这两种方法都产生精确的SHAP结果。最后,如果连模型阶数也未知,我们提出了一种迭代方法来近似Shapley值。当模型阶数不高时(这在实践中通常是典型情况),我们提出的这三种方法计算效率较高。我们通过仿真研究,与Castor & Gomez(2008)提出的采样方法进行比较,以证明我们提出方法的有效性。