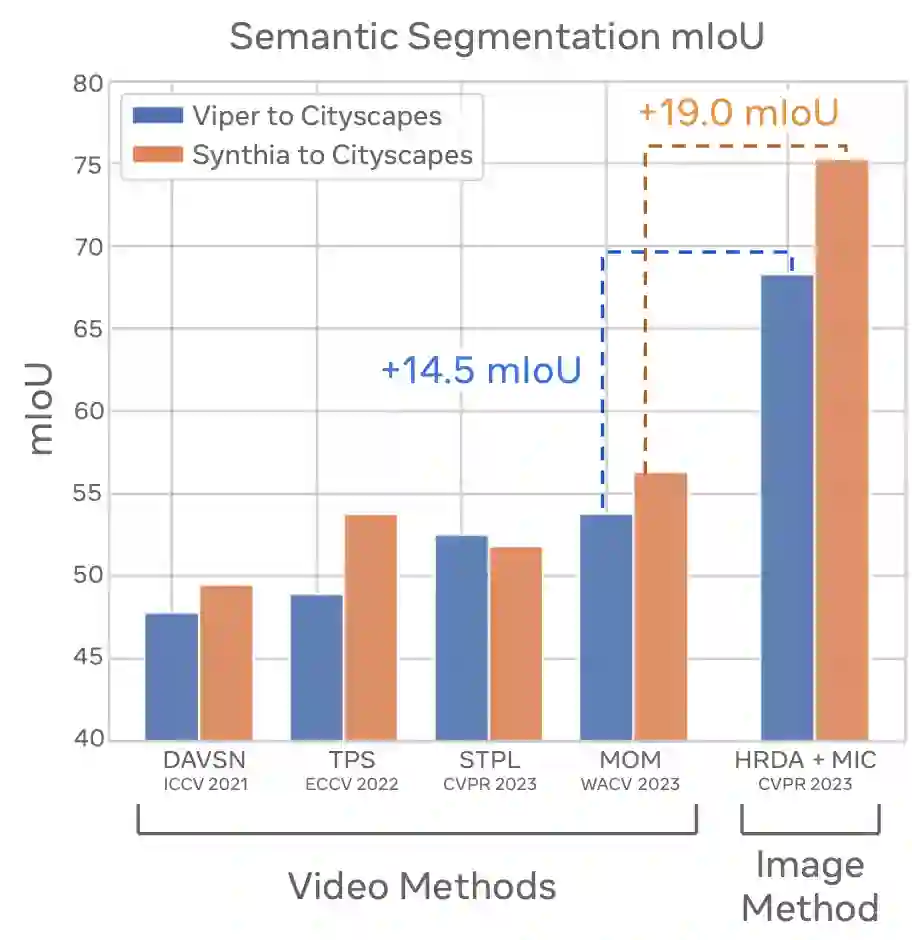
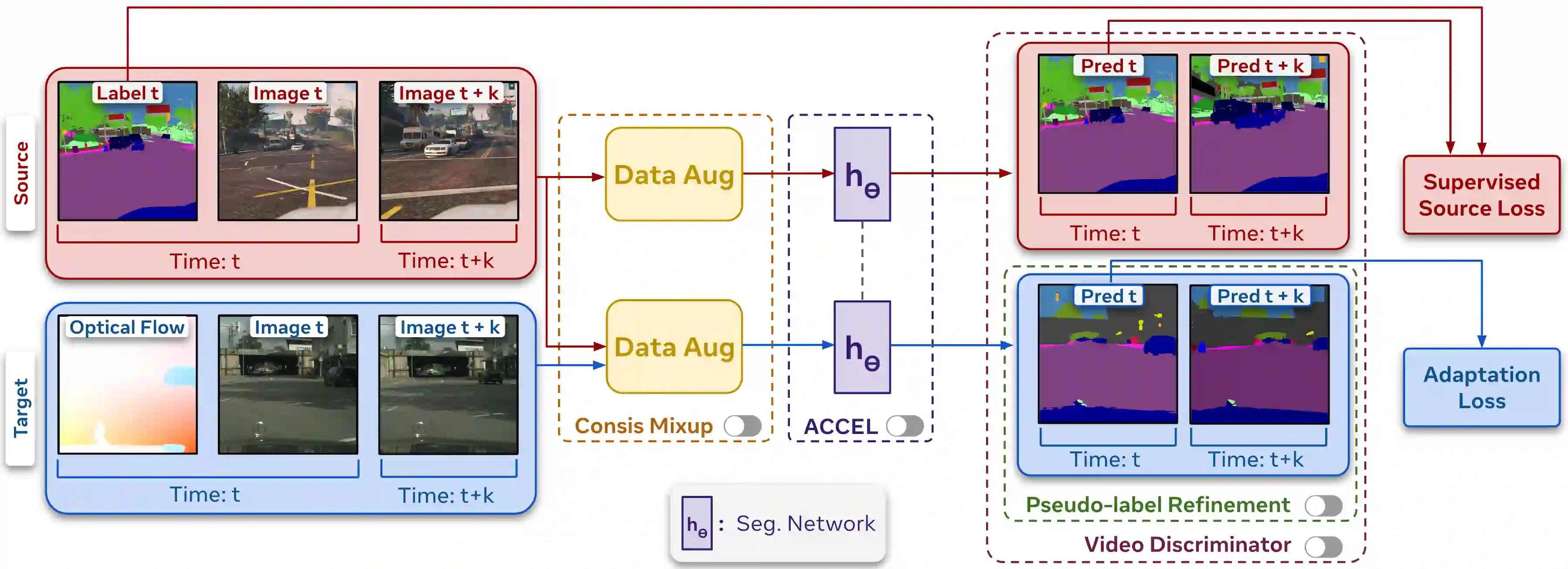
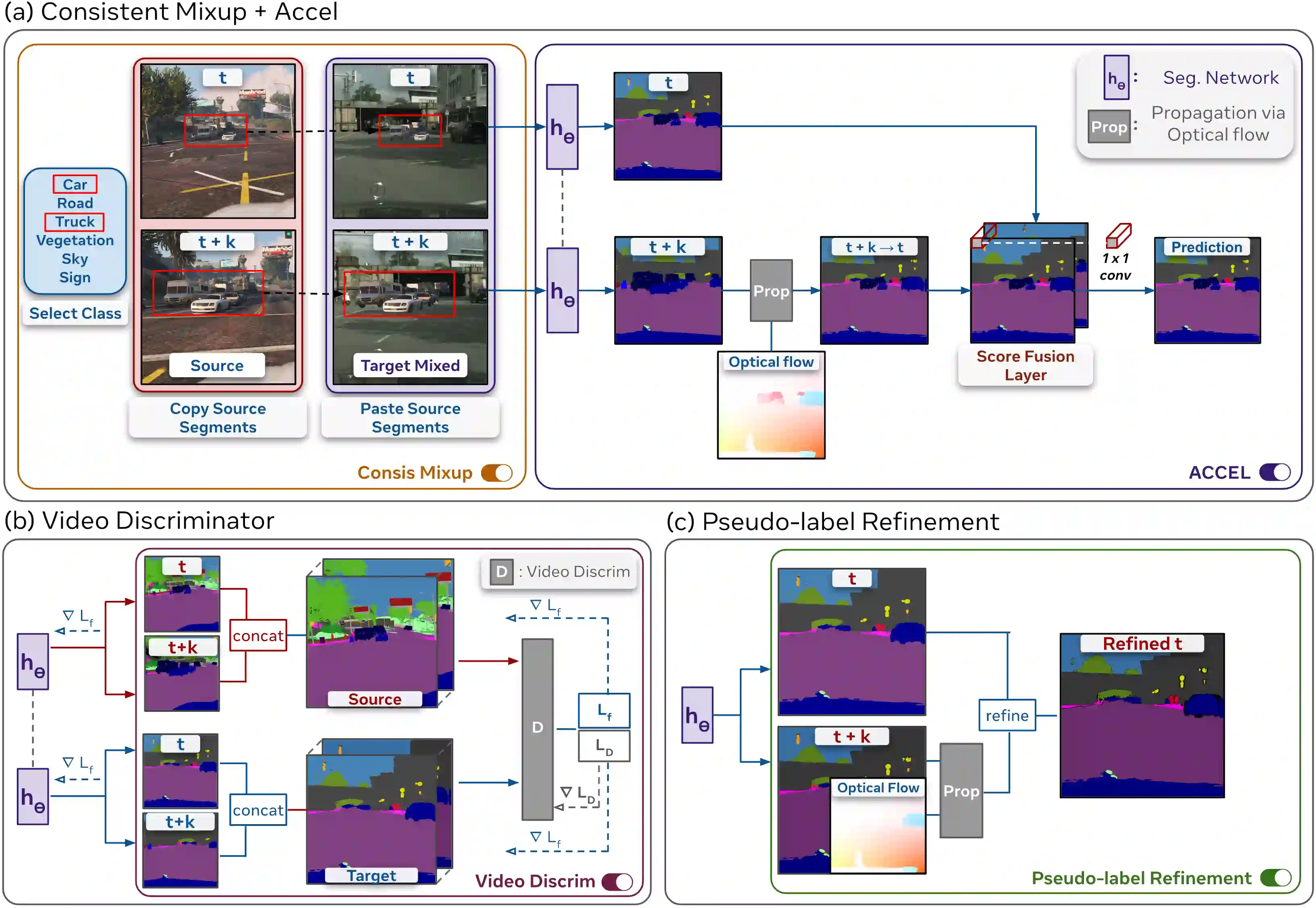
There has been abundant work in unsupervised domain adaptation for semantic segmentation (DAS) seeking to adapt a model trained on images from a labeled source domain to an unlabeled target domain. While the vast majority of prior work has studied this as a frame-level Image-DAS problem, a few Video-DAS works have sought to additionally leverage the temporal signal present in adjacent frames. However, Video-DAS works have historically studied a distinct set of benchmarks from Image-DAS, with minimal cross-benchmarking. In this work, we address this gap. Surprisingly, we find that (1) even after carefully controlling for data and model architecture, state-of-the-art Image-DAS methods (HRDA and HRDA+MIC)} outperform Video-DAS methods on established Video-DAS benchmarks (+14.5 mIoU on Viper$\rightarrow$CityscapesSeq, +19.0 mIoU on Synthia$\rightarrow$CityscapesSeq), and (2) naive combinations of Image-DAS and Video-DAS techniques only lead to marginal improvements across datasets. To avoid siloed progress between Image-DAS and Video-DAS, we open-source our codebase with support for a comprehensive set of Video-DAS and Image-DAS methods on a common benchmark. Code available at https://github.com/SimarKareer/UnifiedVideoDA
翻译:在无监督域自适应语义分割(DAS)领域已有大量工作,旨在将基于标记源域图像训练的模型适配至未标记目标域。尽管绝大多数先前研究将其作为帧级图像-DAS问题处理,但少数视频-DAS工作尝试额外利用相邻帧中存在的时间信号。然而,视频-DAS工作历来使用与图像-DAS不同的基准测试集,且跨基准测试的对比研究极少。在本工作中,我们弥补了这一缺口。令人惊讶的是,我们发现:(1)即使严格控制数据和模型架构后,最先进的图像-DAS方法(HRDA和HRDA+MIC)在现有视频-DAS基准测试上的表现仍优于视频-DAS方法(Viper→CityscapesSeq上mIoU提升14.5,Synthia→CityscapesSeq上提升19.0);(2)图像-DAS与视频-DAS技术的简单组合仅在不同数据集中带来边际改进。为避免图像-DAS与视频-DAS的孤立发展,我们开源了代码库,支持在通用基准测试上对全面视频-DAS与图像-DAS方法进行比较。代码见 https://github.com/SimarKareer/UnifiedVideoDA