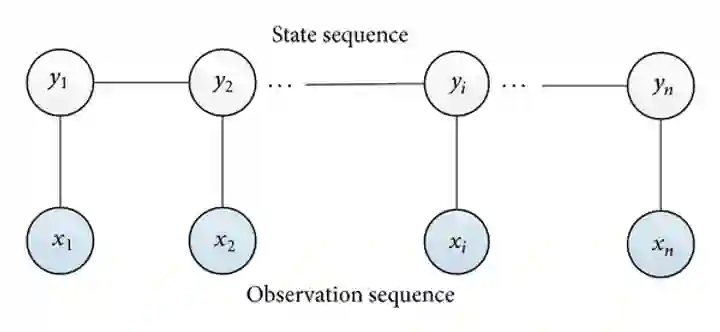
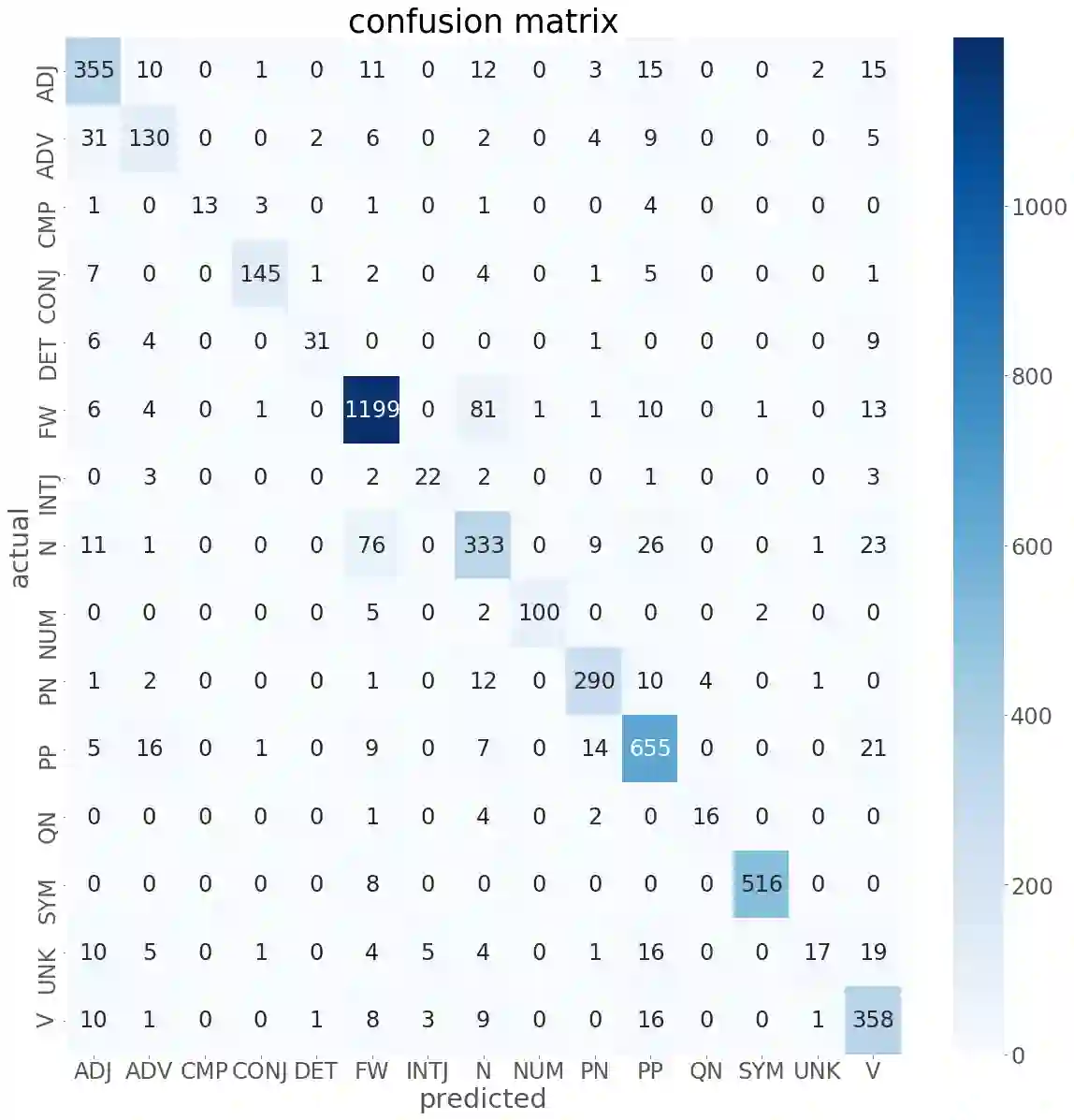
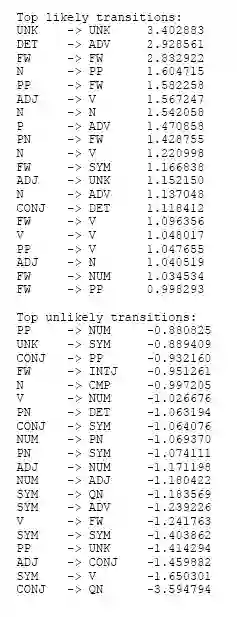
This paper investigates part-of-speech tagging, an important task in Natural Language Processing (NLP) for the Nagamese language. The Nagamese language, a.k.a. Naga Pidgin, is an Assamese-lexified Creole language developed primarily as a means of communication in trade between the Nagas and people from Assam in northeast India. A substantial amount of work in part-of-speech-tagging has been done for resource-rich languages like English, Hindi, etc. However, no work has been done in the Nagamese language. To the best of our knowledge, this is the first attempt at part-of-speech tagging for the Nagamese Language. The aim of this work is to identify the part-of-speech for a given sentence in the Nagamese language. An annotated corpus of 16,112 tokens is created and applied machine learning technique known as Conditional Random Fields (CRF). Using CRF, an overall tagging accuracy of 85.70%; precision, recall of 86%, and f1-score of 85% is achieved. Keywords. Nagamese, NLP, part-of-speech, machine learning, CRF.
翻译:本文研究了自然语言处理(NLP)中一项重要任务——纳加语的词性标注。纳加语,亦称纳加皮钦语,是一种以阿萨姆语词汇为基础的克里奥尔语,主要作为印度东北部那加人与阿萨姆人之间贸易往来的沟通工具而发展起来。目前,针对英语、印地语等资源丰富语言的词性标注已有大量研究工作,然而纳加语的相关研究尚属空白。据我们所知,这是首次针对纳加语进行词性标注的尝试。本工作的目标是对纳加语句子中的词汇进行词性标注。我们构建了一个包含16,112个标记的标注语料库,并应用了称为条件随机场(CRF)的机器学习技术。使用CRF模型,我们实现了整体标注准确率85.70%;精确率86%,召回率86%,F1分数85%的性能指标。关键词:纳加语,自然语言处理,词性标注,机器学习,条件随机场。