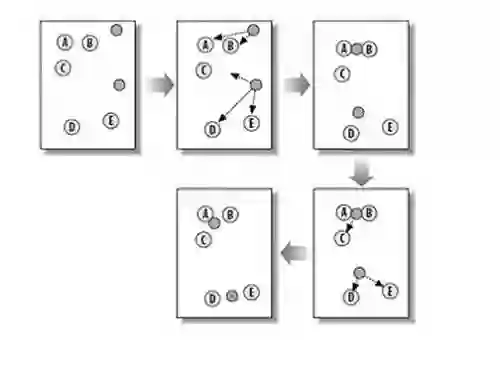
Lloyd's k-means algorithm is one of the most widely used clustering methods. We prove that in high-dimensional, high-noise settings, the algorithm exhibits catastrophic failure: with high probability, essentially every partition of the data is a fixed point. Consequently, Lloyd's algorithm simply returns its initial partition - even when the underlying clusters are trivially recoverable by other methods. In contrast, we prove that Hartigan's k-means algorithm does not exhibit this pathology. Our results show the stark difference between these algorithms and offer a theoretical explanation for the empirical difficulties often observed with k-means in high dimensions.
翻译:Lloyd的k-Means算法是最广泛使用的聚类方法之一。本文证明,在高维高噪声环境下,该算法会呈现灾难性失效:以高概率而言,数据的几乎每种划分都是不动点。因此,即使底层聚类可通过其他方法轻松恢复,Lloyd算法也仅会返回其初始划分。与之相反,我们证明Hartigan的k-Means算法不存在这种病态特性。研究结果揭示了这两种算法的本质差异,并为高维场景下k-Means算法常遇到的实证困境提供了理论解释。