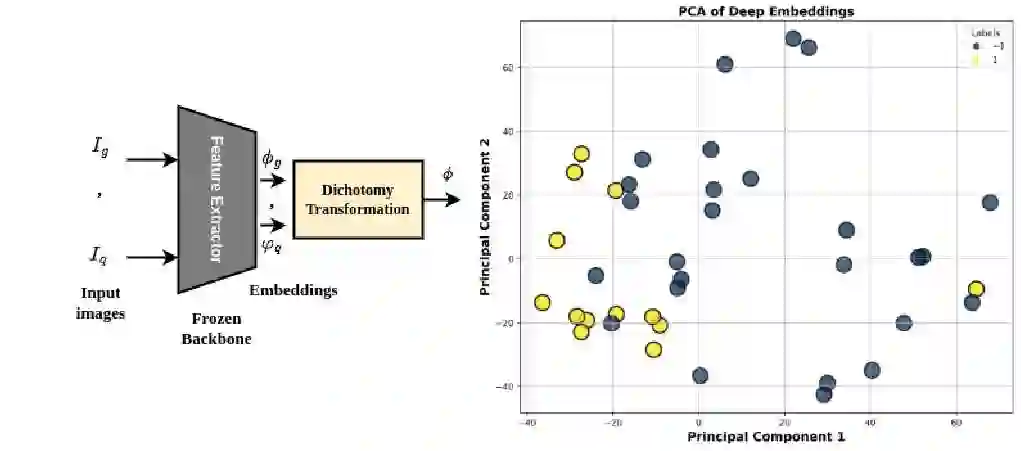
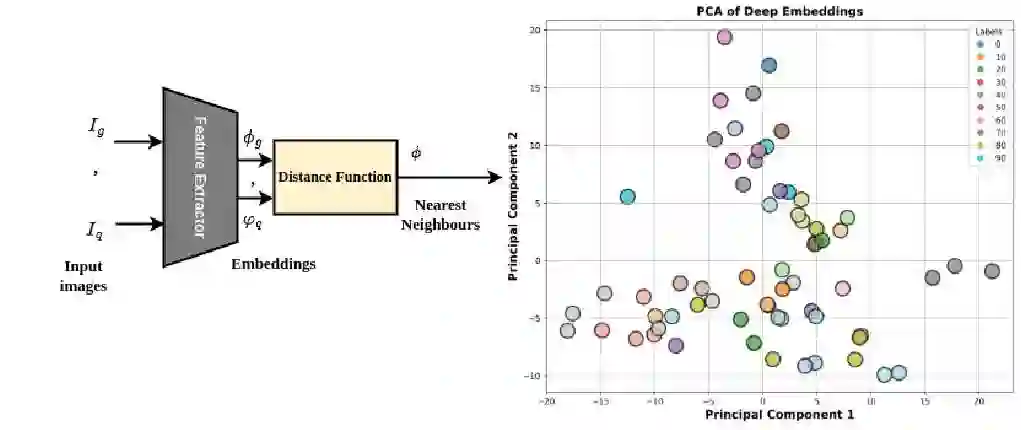
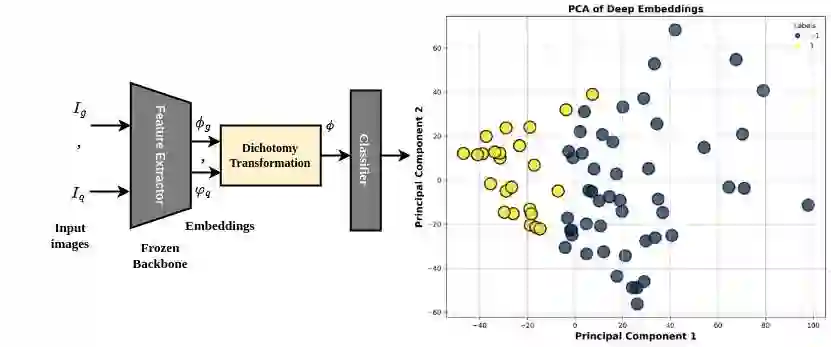
Image retrieval methods rely on metric learning to train backbone feature extraction models that can extract discriminant queries and reference (gallery) feature representations for similarity matching. Although state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large datasets, image retrieval remains challenging in many real-world video analytics and surveillance applications, e.g., person re-identification. Using the Euclidean space for matching limits the performance in real-world applications due to the curse of dimensionality, overfitting, and sensitivity to noisy data. We argue that the feature dissimilarity space is more suitable for similarity matching, and propose a dichotomy transformation to project query and reference embeddings into a single embedding in the dissimilarity space. We also advocate for end-to-end training of a backbone and binary classification models for pair-wise matching. As opposed to comparing the distance between queries and reference embeddings, we show the benefits of classifying the single dissimilarity space embedding (as similar or dissimilar), especially when trained end-to-end. We propose a method to train the max-margin classifier together with the backbone feature extractor by applying constraints to the L2 norm of the classifier weights along with the hinge loss. Our extensive experiments on challenging image retrieval datasets and using diverse feature extraction backbones highlight the benefits of similarity matching in the dissimilarity space. In particular, when jointly training the feature extraction backbone and regularised classifier for matching, the dissimilarity space provides a higher level of accuracy.
翻译:图像检索方法依赖度量学习来训练骨干特征提取模型,以提取用于相似性匹配的判别性查询与参考(图库)特征表示。尽管随着基于大规模数据集训练的深度学习(DL)模型的出现,最先进的准确率已显著提升,但在许多现实世界的视频分析与监控应用(例如行人重识别)中,图像检索仍然具有挑战性。由于维数灾难、过拟合以及对噪声数据的敏感性,使用欧几里得空间进行匹配限制了其在现实应用中的性能。我们认为特征相异空间更适合进行相似性匹配,并提出一种二分变换,将查询与参考嵌入投影到相异空间中的单个嵌入。我们还倡导对骨干模型和用于成对匹配的二元分类模型进行端到端训练。与比较查询和参考嵌入之间的距离不同,我们展示了分类单个相异空间嵌入(作为相似或不相似)的优势,尤其是在端到端训练时。我们提出一种方法,通过对分类器权重的L2范数施加约束并结合铰链损失,将最大间隔分类器与骨干特征提取器联合训练。我们在具有挑战性的图像检索数据集上使用多种特征提取骨干进行的广泛实验,突显了在相异空间中进行相似性匹配的优势。特别是,当联合训练用于匹配的特征提取骨干与正则化分类器时,相异空间能提供更高的准确率。