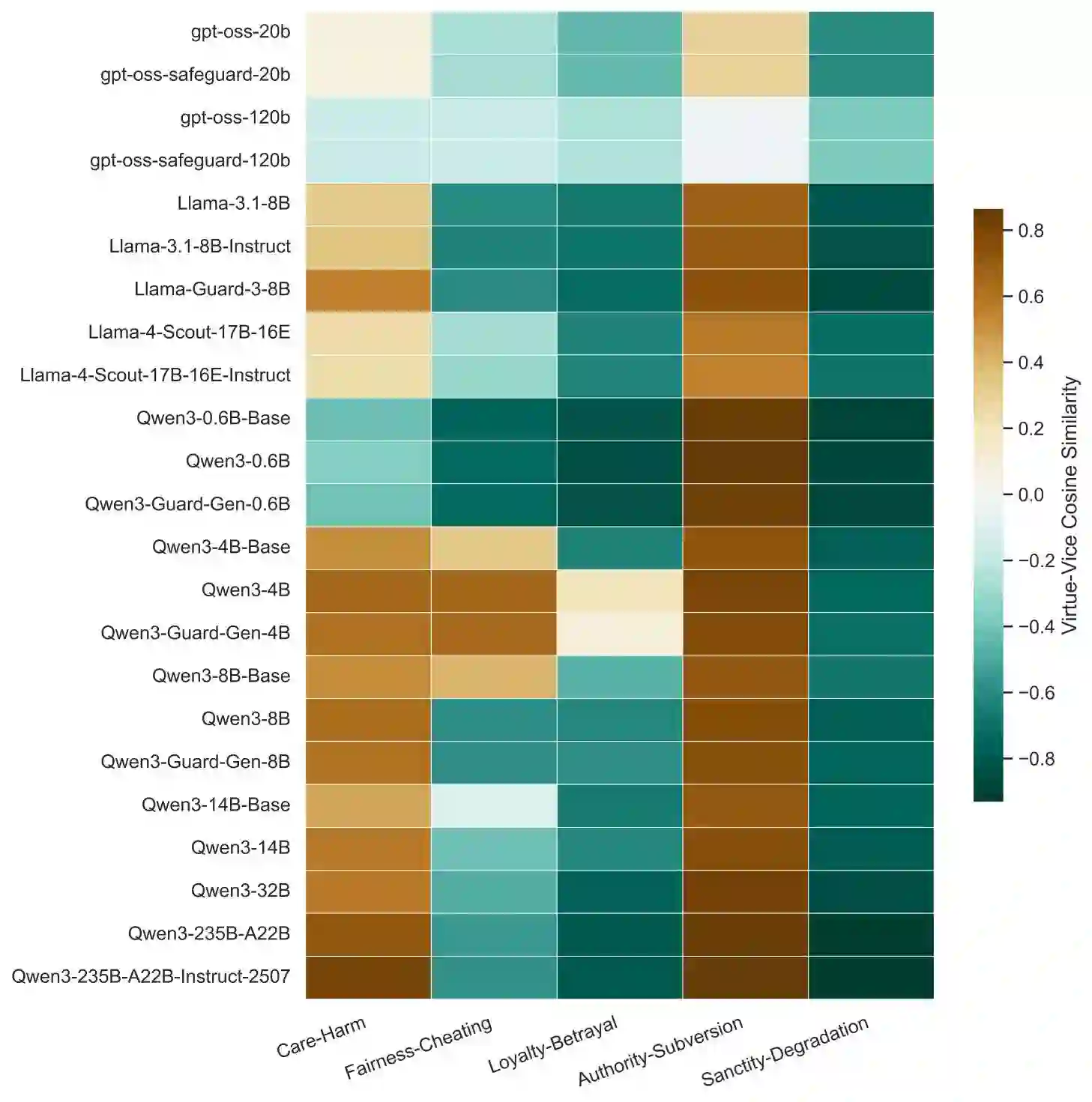
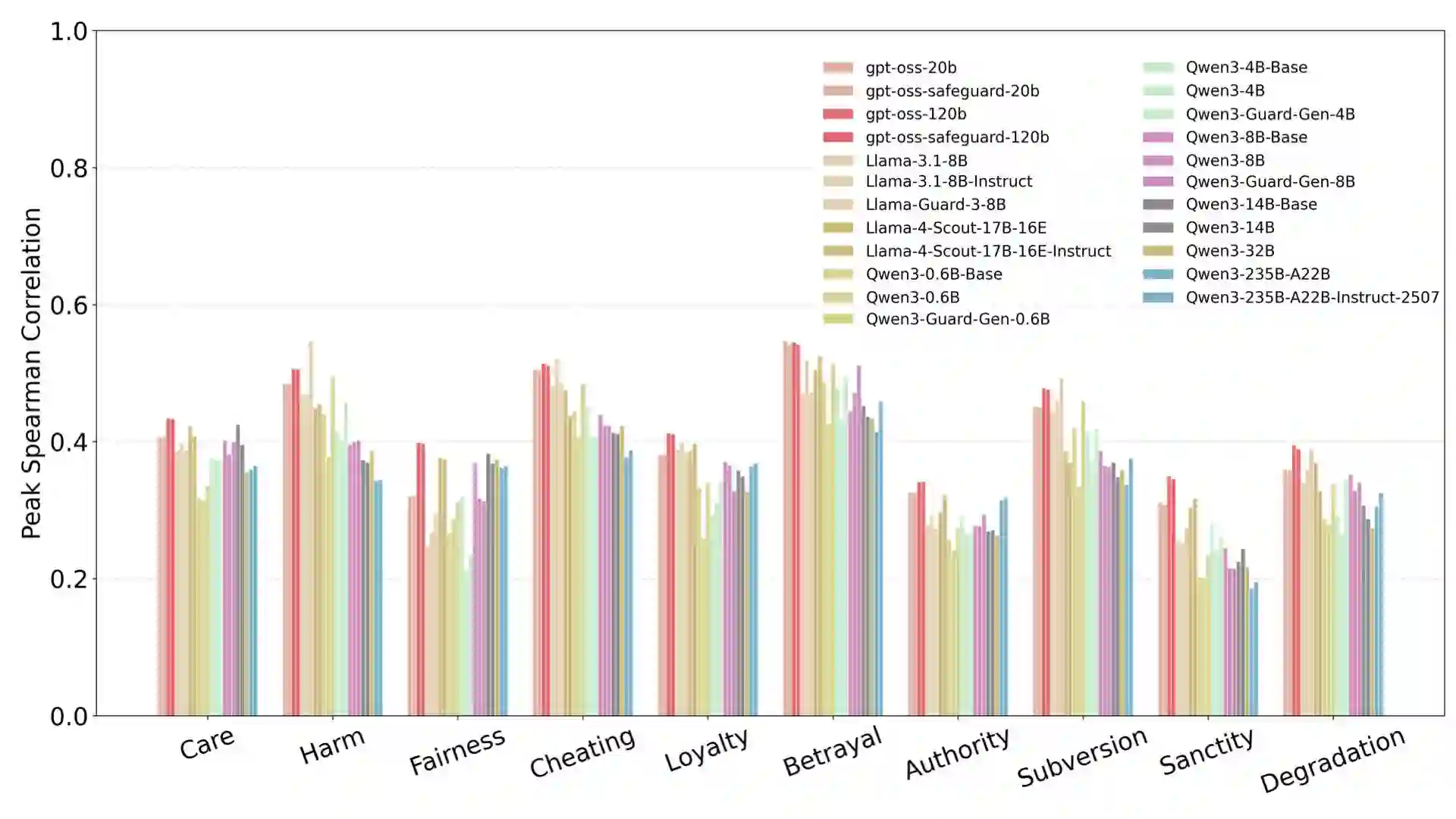
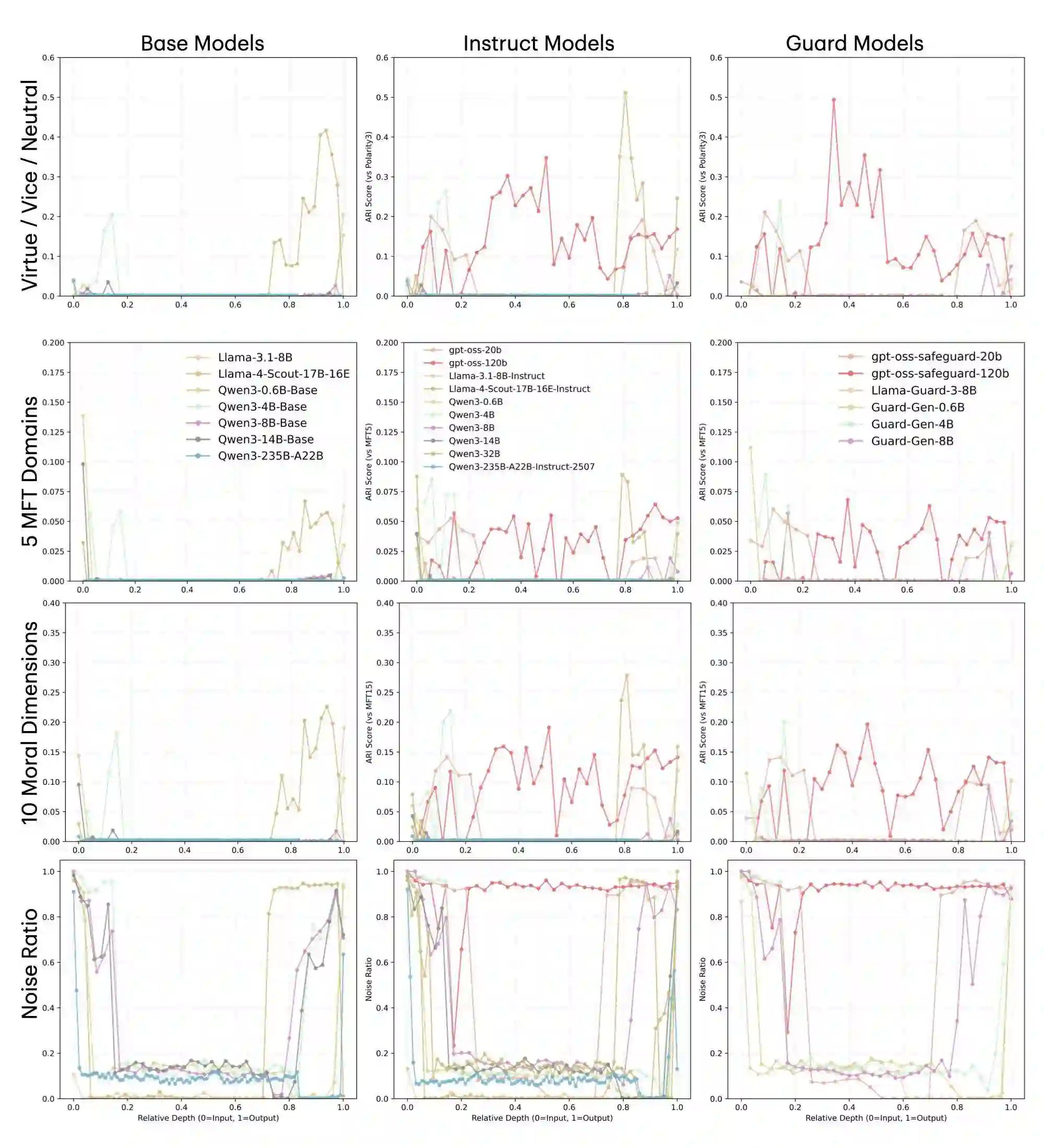
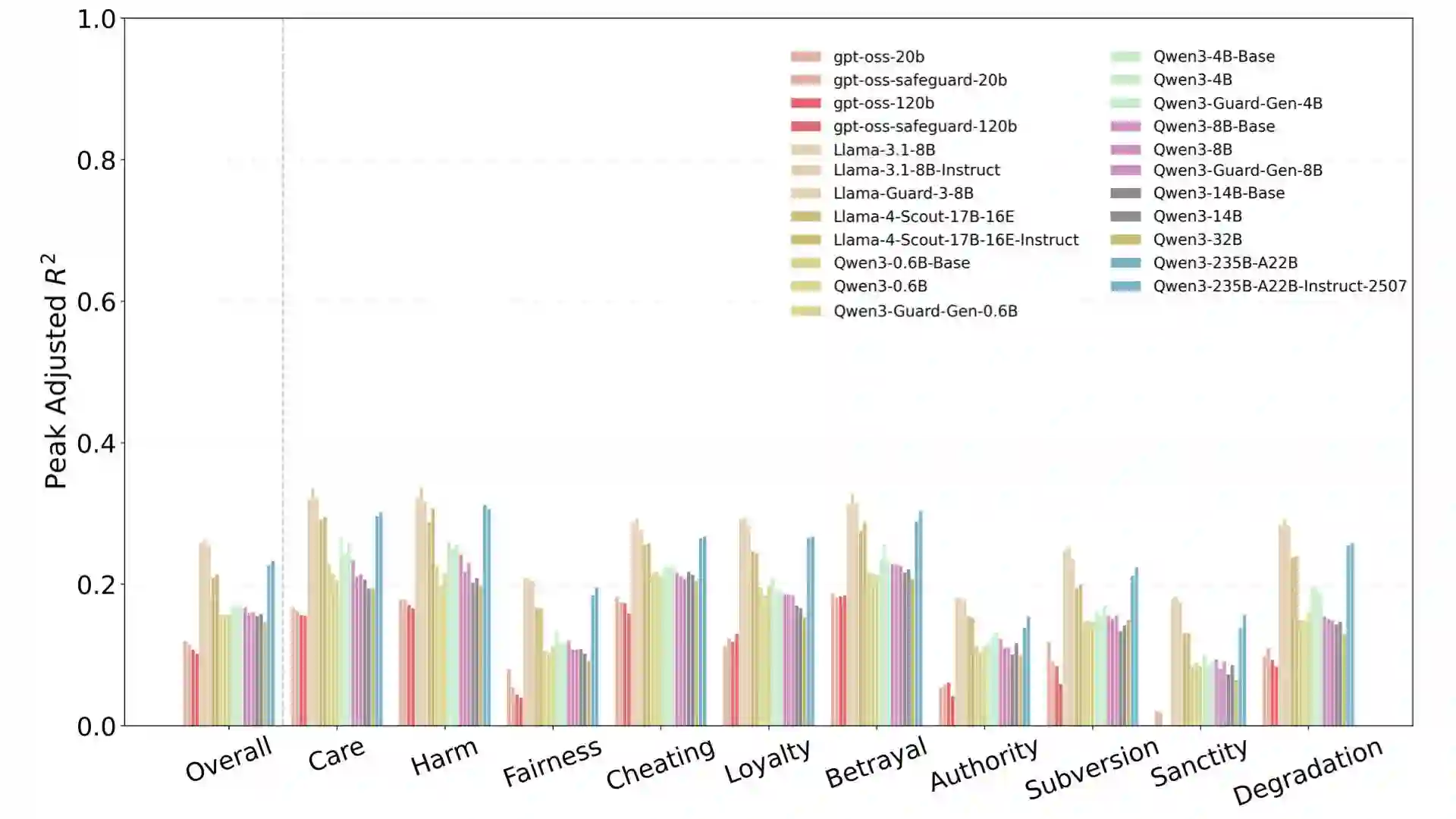
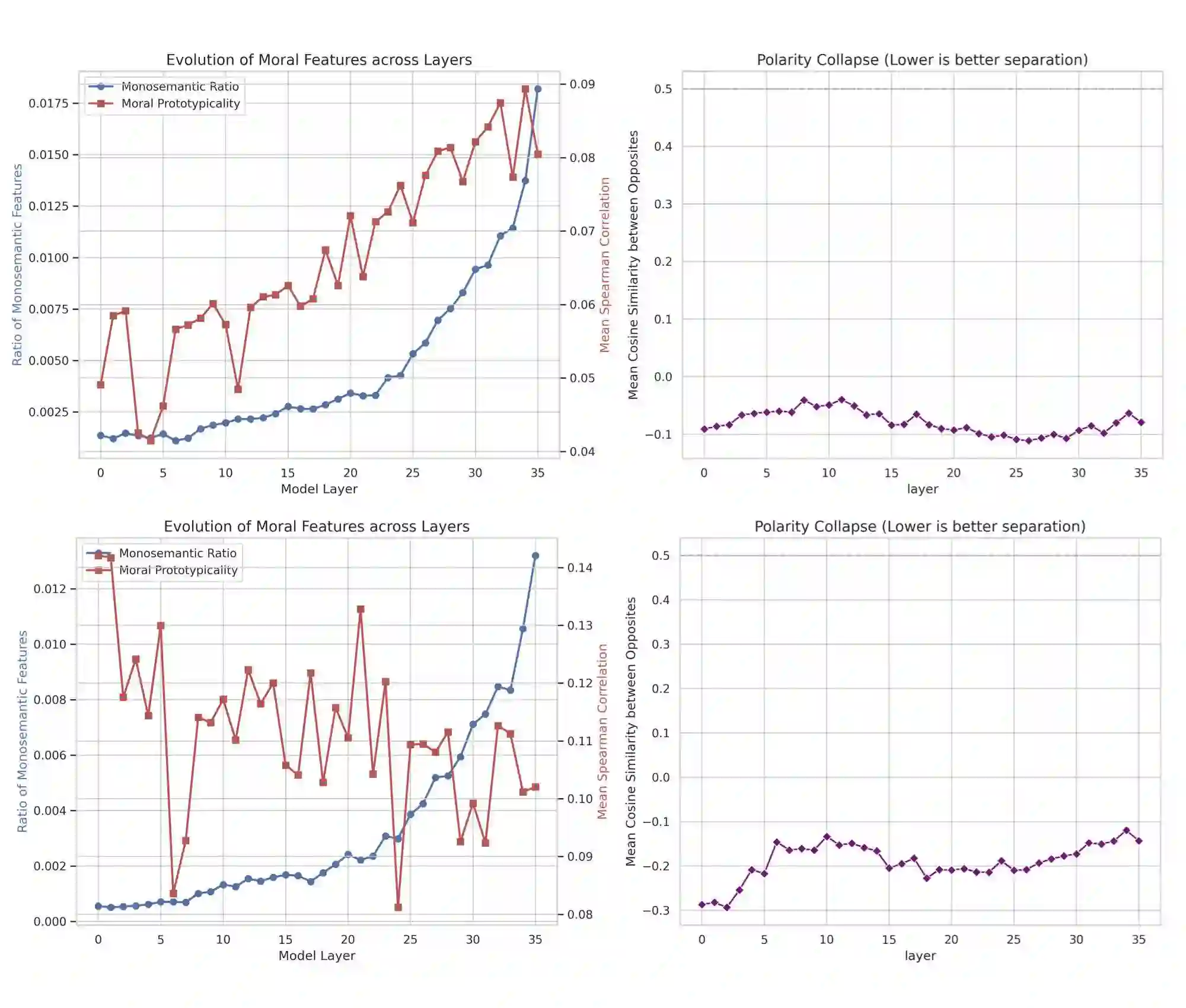
Existing behavioral alignment techniques for Large Language Models (LLMs) often neglect the discrepancy between surface compliance and internal unaligned representations, leaving LLMs vulnerable to long-tail risks. More crucially, we posit that LLMs possess an inherent state of moral indifference due to compressing distinct moral concepts into uniform probability distributions. We verify and remedy this indifference in LLMs' latent representations, utilizing 251k moral vectors constructed upon Prototype Theory and the Social-Chemistry-101 dataset. Firstly, our analysis across 23 models reveals that current LLMs fail to represent the distinction between opposed moral categories and fine-grained typicality gradients within these categories; notably, neither model scaling, architecture, nor explicit alignment reshapes this indifference. We then employ Sparse Autoencoders on Qwen3-8B, isolate mono-semantic moral features, and targetedly reconstruct their topological relationships to align with ground-truth moral vectors. This representational alignment naturally improves moral reasoning and granularity, achieving a 75% pairwise win-rate on the independent adversarial Flames benchmark. Finally, we elaborate on the remedial nature of current intervention methods from an experientialist philosophy, arguing that endogenously aligned AI might require a transformation from post-hoc corrections to proactive cultivation.
翻译:现有的大型语言模型(LLM)行为对齐技术常忽视表层合规性与内部未对齐表征之间的差异,使LLM易受长尾风险影响。更重要的是,我们认为LLM由于将不同的道德概念压缩为统一的概率分布,从而具有内在的道德漠然状态。我们基于原型理论和社会化学-101数据集构建的251k个道德向量,在LLM的潜在表征中验证并矫正了这种漠然性。首先,我们对23个模型的分析表明,当前LLM无法表征对立道德类别之间的区别以及这些类别内部的细粒度典型性梯度;值得注意的是,无论是模型缩放、架构还是显式对齐都无法改变这种漠然性。随后,我们在Qwen3-8B上采用稀疏自编码器,分离出单义道德特征,并有针对性地重构其拓扑关系以对齐真实道德向量。这种表征对齐自然提升了道德推理的精细度,在独立的对抗性Flames基准测试中实现了75%的成对胜率。最后,我们从经验主义哲学的角度阐述了当前干预方法的矫正性质,认为内生对齐的人工智能可能需要从事后修正转变为主动培育。