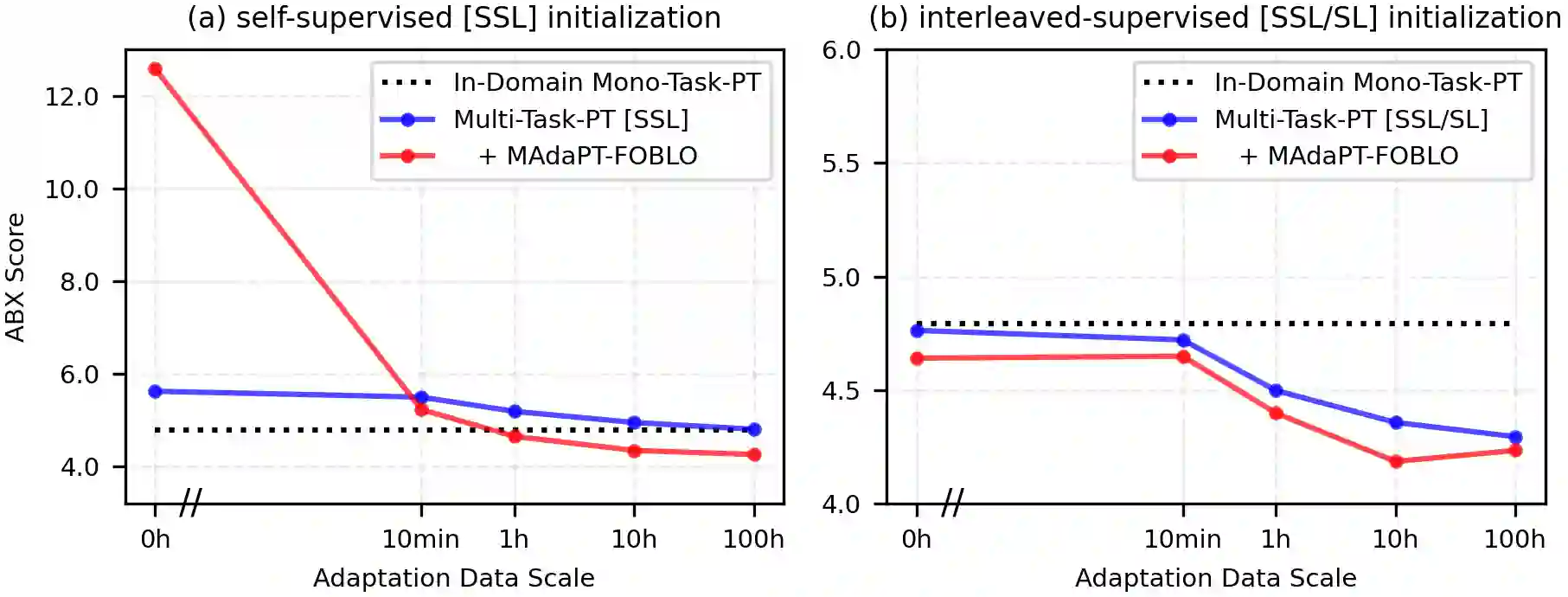
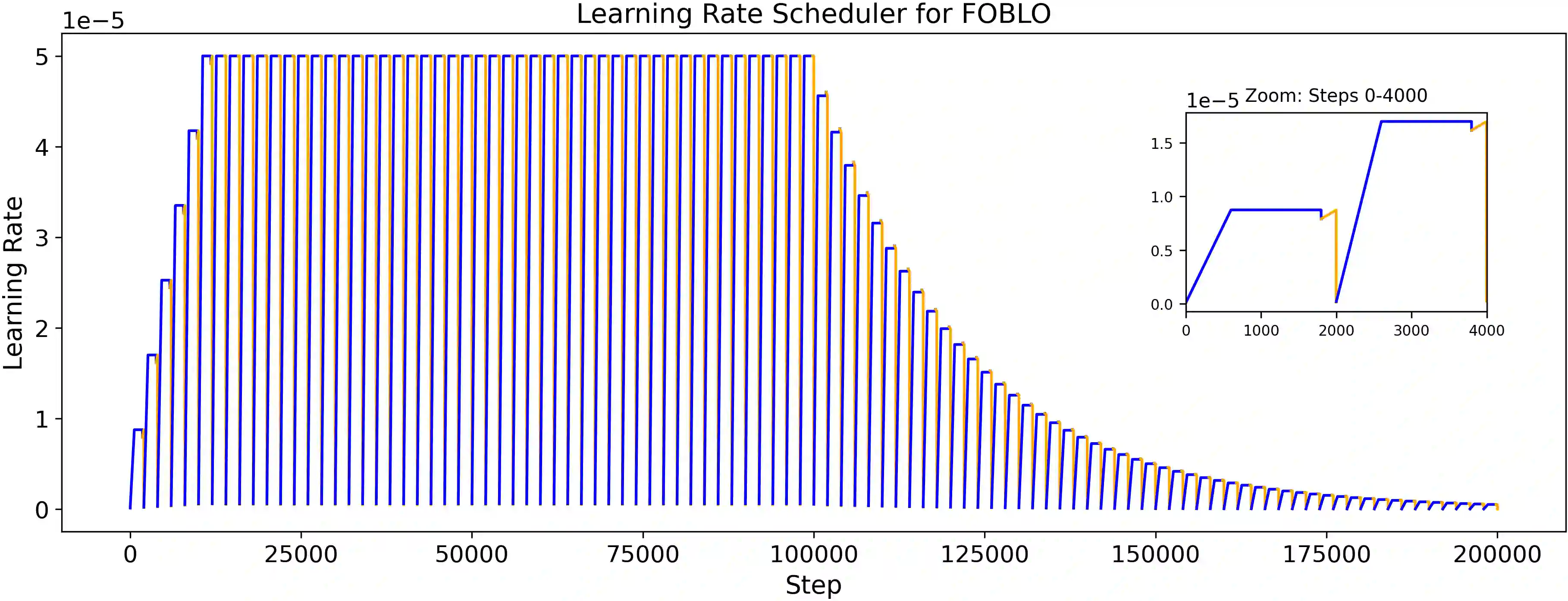
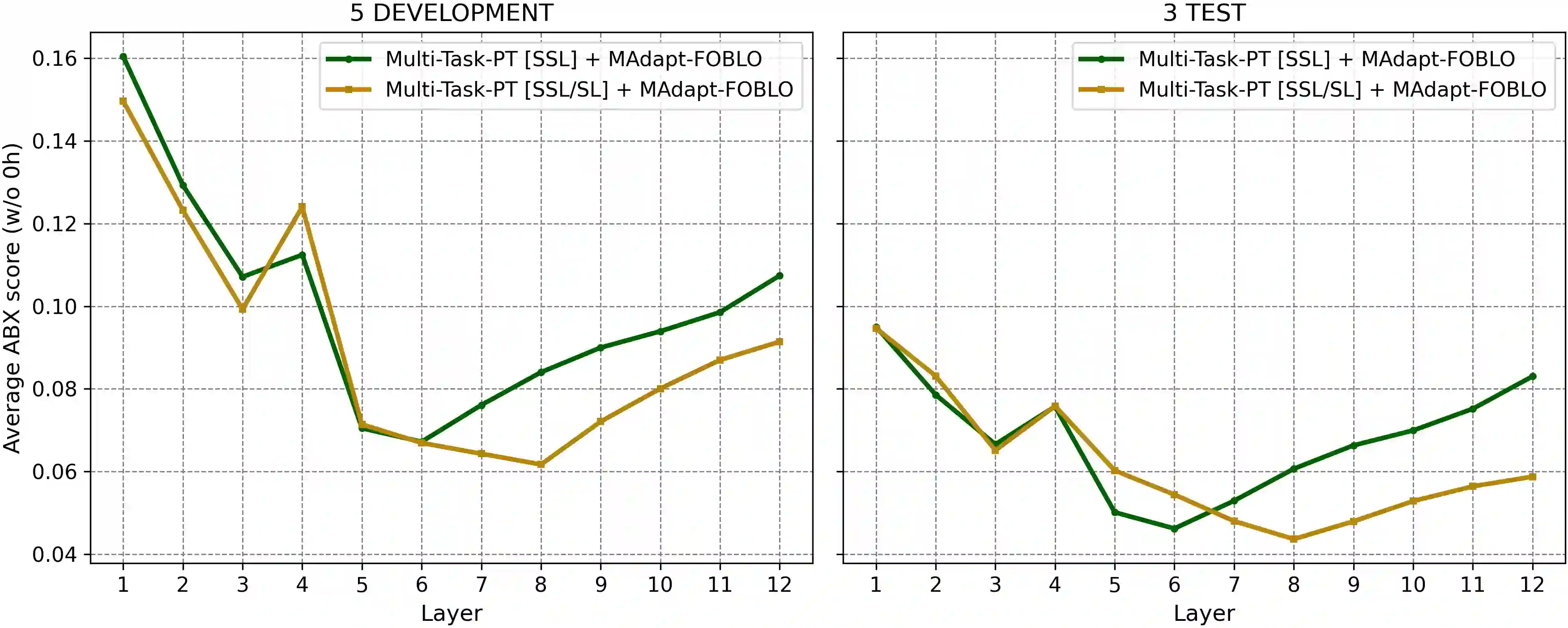
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
翻译:人类婴儿仅需接触数百小时的语音,便能习得新语言的基本单元,这突显了与数据饥渴的自监督语音模型之间存在的显著效率差距。为弥合这一差距,本文提出了SpidR-Adapt,旨在利用极少量未标注数据快速适应新语言。我们将此类低资源语音表征学习构建为一个元学习问题,并设计了一种多任务自适应预训练(MAdaPT)协议,该协议将适应过程表述为一个双层优化框架。为实现该框架下的可扩展元训练,我们提出了一种新颖的启发式解决方案——一阶双层优化(FOBLO),避免了沉重的计算成本。最后,我们通过交替使用自监督与监督目标的交错监督机制获得鲁棒的初始化,从而稳定了元训练过程。实验表明,SpidR-Adapt在音素可区分性(ABX)和口语语言建模(sWUGGY、sBLIMP、tSC)方面实现了快速提升,在训练少于1小时的目标语言音频后,其性能即超越领域内语言模型,数据效率比标准训练高出$100\times$以上。这些发现为构建受生物学启发的、数据高效的表征指明了一条实用且与架构无关的路径。我们在https://github.com/facebookresearch/spidr-adapt 开源了训练代码与模型检查点。