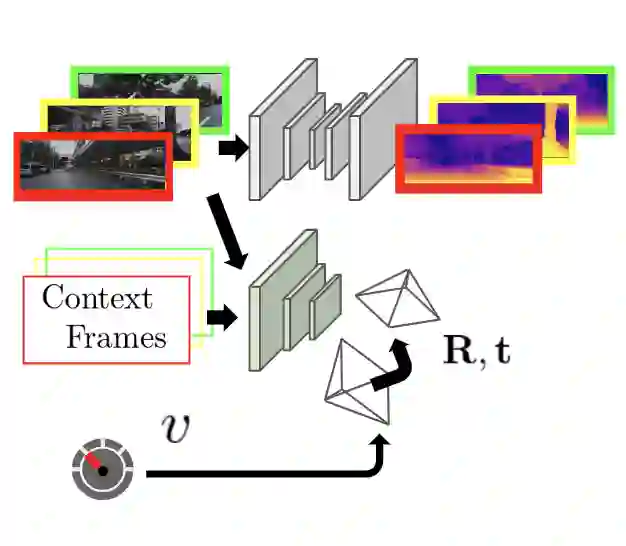
Autonomous vehicles and robots need to operate over a wide variety of scenarios in order to complete tasks efficiently and safely. Multi-camera self-supervised monocular depth estimation from videos is a promising way to reason about the environment, as it generates metrically scaled geometric predictions from visual data without requiring additional sensors. However, most works assume well-calibrated extrinsics to fully leverage this multi-camera setup, even though accurate and efficient calibration is still a challenging problem. In this work, we introduce a novel method for extrinsic calibration that builds upon the principles of self-supervised monocular depth and ego-motion learning. Our proposed curriculum learning strategy uses monocular depth and pose estimators with velocity supervision to estimate extrinsics, and then jointly learns extrinsic calibration along with depth and pose for a set of overlapping cameras rigidly attached to a moving vehicle. Experiments on a benchmark multi-camera dataset (DDAD) demonstrate that our method enables self-calibration in various scenes robustly and efficiently compared to a traditional vision-based pose estimation pipeline. Furthermore, we demonstrate the benefits of extrinsics self-calibration as a way to improve depth prediction via joint optimization.
翻译:自动驾驶车辆和机器人需要在多种场景中高效安全地完成任务。基于视频的多相机自监督单目深度估计是一种有前景的环境推理方法,它能从视觉数据中生成具有公制尺度的几何预测,且无需额外传感器。然而,大多数工作假设外参已完美标定以充分利用这一多相机设置,尽管准确高效的外参标定仍是一个具有挑战性的问题。本文提出了一种基于自监督单目深度与自运动学习原理的外参标定新方法。我们提出的课程学习策略利用单目深度与位姿估计器结合速度监督来估计外参,随后对固定于运动车辆上具有重叠视野的多相机系统,联合学习外参标定、深度和位姿估算。在基准多相机数据集(DDAD)上的实验表明,与传统基于视觉的位姿估计流程相比,我们的方法能在各种场景下鲁棒且高效地实现自标定。此外,我们证明了外参自标定通过联合优化提升深度预测的优越性。