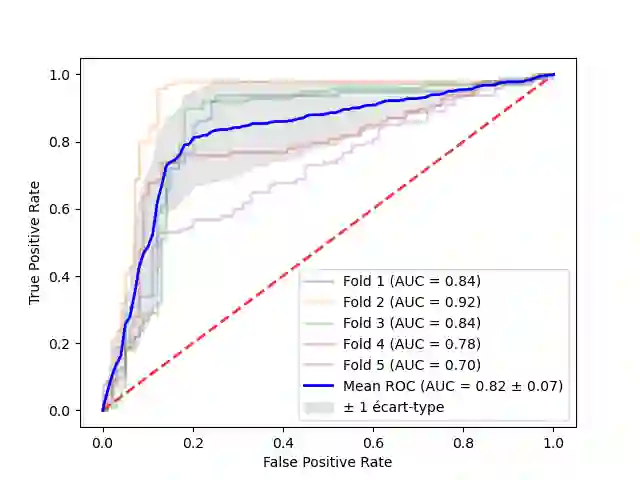
The rise of Large Language Models (LLMs) has triggered legal and ethical concerns, especially regarding the unauthorized use of copyrighted materials in their training datasets. This has led to lawsuits against tech companies accused of using protected content without permission. Membership Inference Attacks (MIAs) aim to detect whether specific documents were used in a given LLM pretraining, but their effectiveness is undermined by biases such as time-shifts and n-gram overlaps. This paper addresses the evaluation of MIAs on LLMs with partially inferable training sets, under the ex-post hypothesis, which acknowledges inherent distributional biases between members and non-members datasets. We propose and validate algorithms to create ``non-biased'' and ``non-classifiable'' datasets for fairer MIA assessment. Experiments using the Gutenberg dataset on OpenLamma and Pythia show that neutralizing known biases alone is insufficient. Our methods produce non-biased ex-post datasets with AUC-ROC scores comparable to those previously obtained on genuinely random datasets, validating our approach. Globally, MIAs yield results close to random, with only one being effective on both random and our datasets, but its performance decreases when bias is removed.
翻译:大型语言模型(LLMs)的兴起引发了法律与伦理担忧,尤其是其训练数据集中未经授权使用受版权保护材料的问题。这已导致多家科技公司因被指控未经许可使用受保护内容而面临诉讼。成员推断攻击(MIAs)旨在检测特定文档是否被用于给定LLM的预训练,但其有效性受到时间偏移和n-gram重叠等偏差的削弱。本文针对训练集部分可推断的LLMs,在事后假设框架下评估MIAs——该假设承认成员与非成员数据集间存在固有的分布偏差。我们提出并验证了构建“无偏”与“不可分类”数据集的算法,以实现更公平的MIA评估。基于古腾堡数据集在OpenLamma和Pythia上的实验表明,仅消除已知偏差并不充分。我们的方法构建的无偏事后数据集,其AUC-ROC分数与先前在真实随机数据集上获得的结果相当,验证了该方法的有效性。总体而言,MIAs在全局范围内表现接近随机,仅有一种方法在随机数据集和我们的数据集上均有效,但其性能在偏差消除后出现下降。