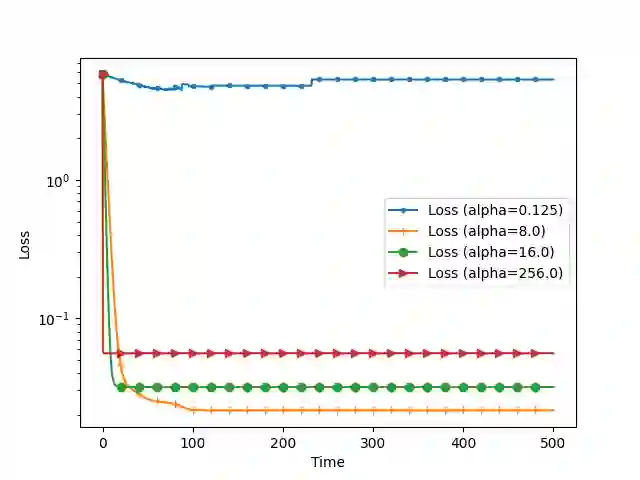
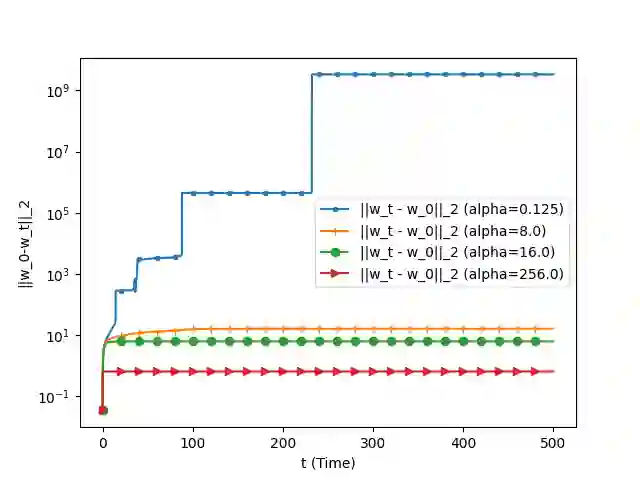
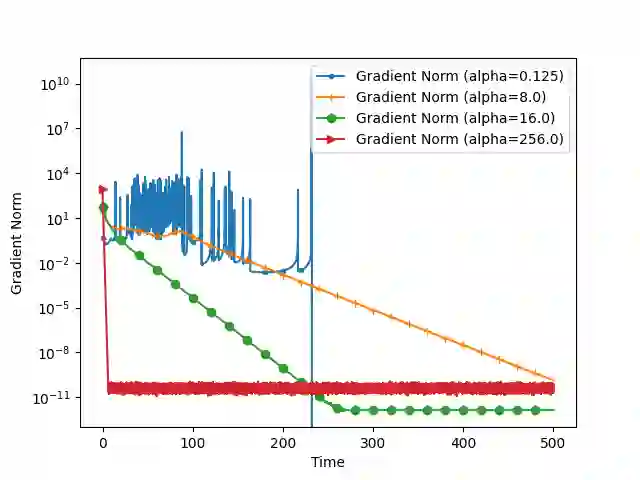
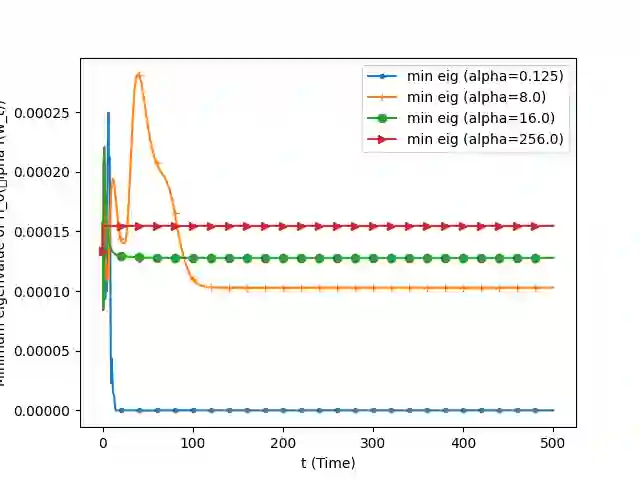
We analyze the convergence of Gauss-Newton dynamics for training neural networks with smooth activation functions. In the underparameterized regime, the Gauss-Newton gradient flow induces a Riemannian gradient flow on a low-dimensional, smooth, embedded submanifold of the Euclidean output space. Using tools from Riemannian optimization, we prove \emph{last-iterate} convergence of the Riemannian gradient flow to the optimal in-class predictor at an \emph{exponential rate} that is independent of the conditioning of the Gram matrix, \emph{without} requiring explicit regularization. We further characterize the critical impacts of the neural network scaling factor and the initialization on the convergence behavior. In the overparameterized regime, we show that the Levenberg-Marquardt dynamics with an appropriately chosen damping factor yields robustness to ill-conditioned kernels, analogous to the underparameterized regime. These findings demonstrate the potential of Gauss-Newton methods for efficiently optimizing neural networks, particularly in ill-conditioned problems where kernel and Gram matrices have small singular values.
翻译:我们分析了使用光滑激活函数训练神经网络时 Gauss-Newton 动力学的收敛性。在欠参数化机制下,Gauss-Newton 梯度流在欧几里得输出空间的一个低维、光滑、嵌入子流形上诱导出一个黎曼梯度流。利用黎曼优化的工具,我们证明了该黎曼梯度流的**末次迭代**以**指数速率**收敛到最优类内预测器,该速率与 Gram 矩阵的条件数无关,且**无需**显式正则化。我们进一步刻画了神经网络缩放因子和初始化对收敛行为的临界影响。在过参数化机制下,我们证明了具有适当选取阻尼因子的 Levenberg-Marquardt 动力学能够对病态核具有鲁棒性,这与欠参数化机制类似。这些发现展示了 Gauss-Newton 方法在高效优化神经网络方面的潜力,特别是在核矩阵与 Gram 矩阵具有小奇异值的病态问题中。